
Lambda Function To Read JSON File From S3 Bucket And Push Into DynamoDB Table
- Goto Lambda console and click on create function
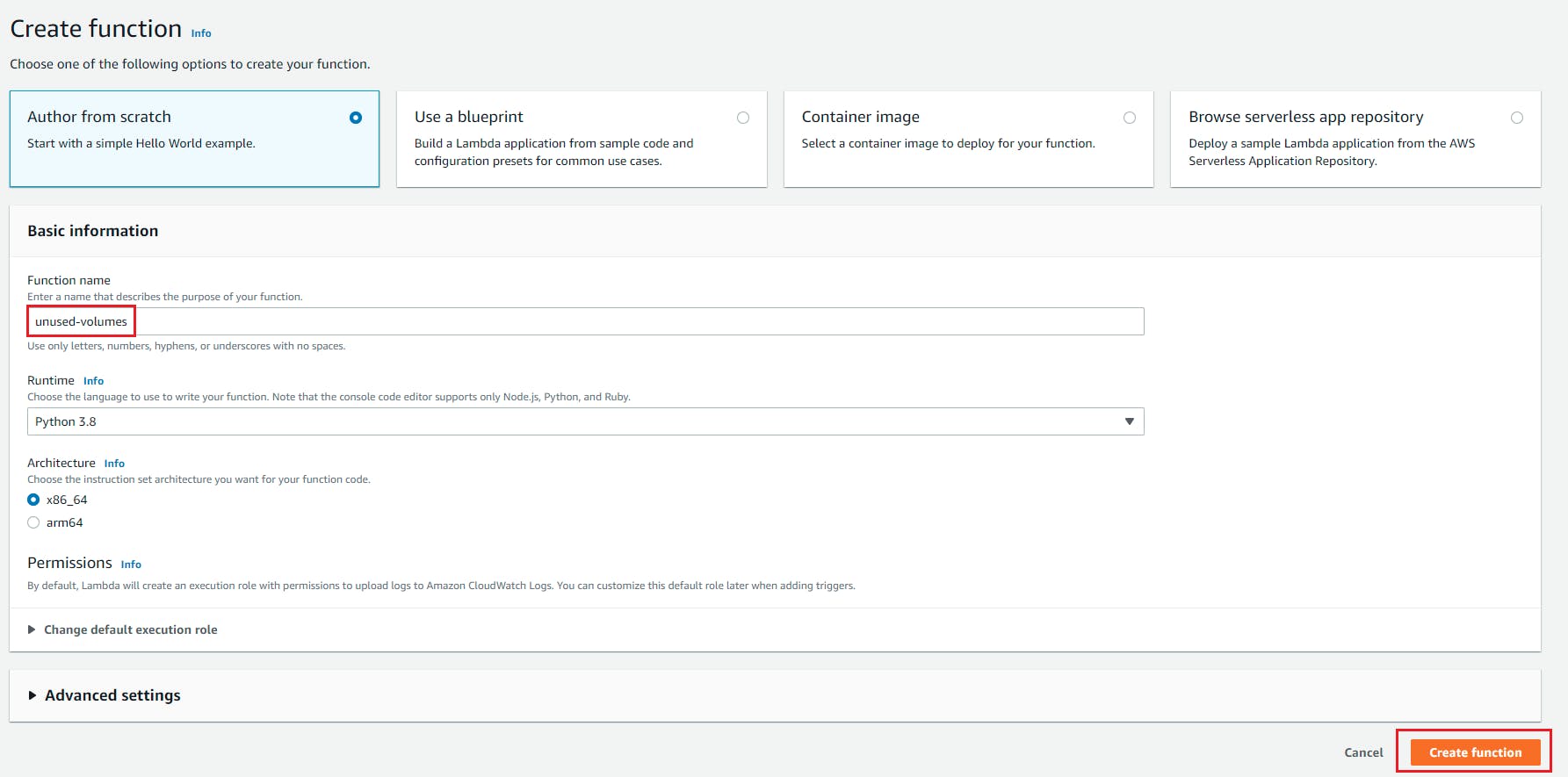
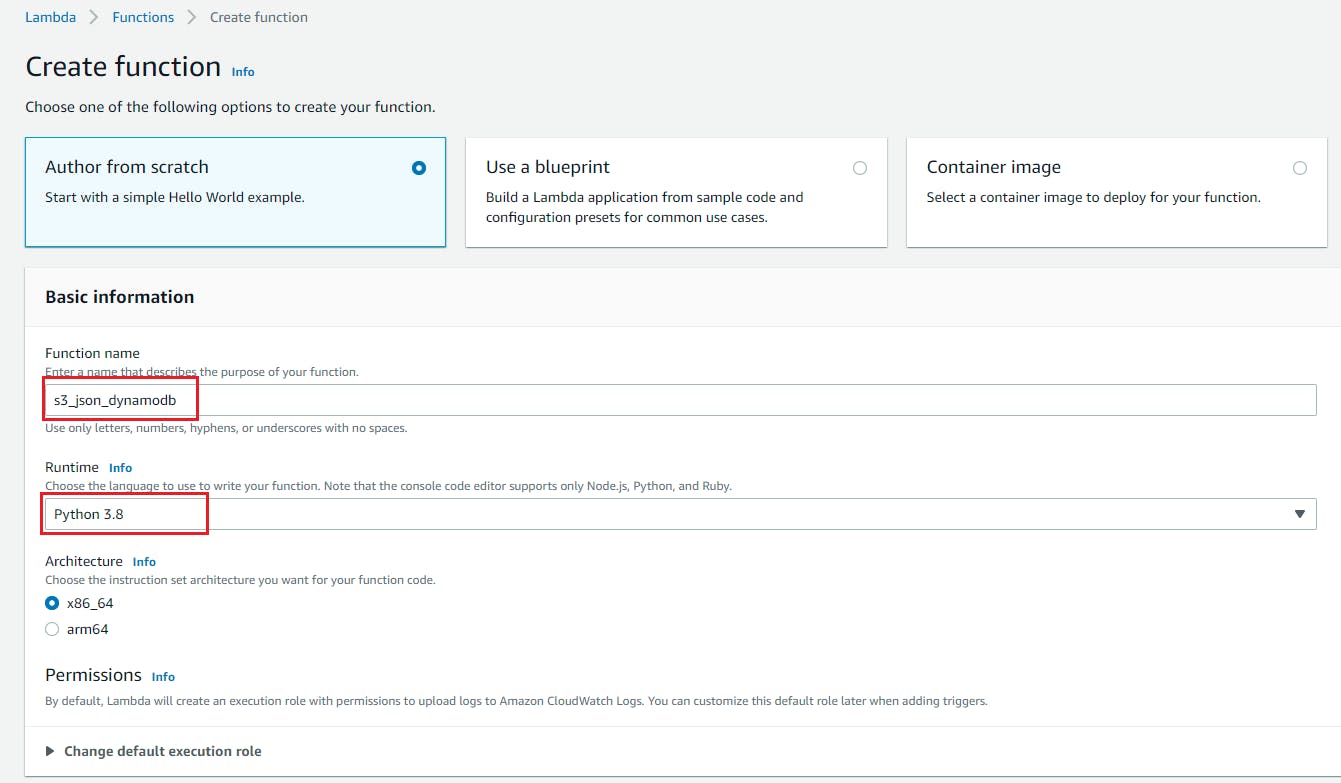
- Select “Author From Scratch” , Function name = s3_json_dynamodb, Runtime= Python and role we created with above policy attached to this blog and click on create function.
- Goto code editor and start writing the code.
- We will import 3 modules
import boto3 import json import ast - We will invoke the client for S3 and resource for dynamodb
s3_client = boto3.client('s3') dynamodb_client = boto3.resource('dynamodb') - First we will fetch bucket name from event json object
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] - Now we will fetch file name which is uploaded in s3 bucket from event json object
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] json_file_name = event['Records'][0]['s3']['object']['key'] - We will call now get_object() function to Retrieves objects from Amazon S3. To use GET , you must have READ access to the object. If you grant READ access to the anonymous user, you can return the object without using an authorization header. You can view this function official documentation here
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] json_file_name = event['Records'][0]['s3']['object']['key'] json_object = s3_client.get_object(Bucket=bucket,Key=json_file_name) - Lets decode the json object returned by function which will return string
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] json_file_name = event['Records'][0]['s3']['object']['key'] json_object = s3_client.get_object(Bucket=bucket,Key=json_file_name) file_reader = json_object['Body'].read().decode("utf-8") - We will now change this json string to dictionary by using ast.literal_eval(). You can view this function official documentation here
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] json_file_name = event['Records'][0]['s3']['object']['key'] json_object = s3_client.get_object(Bucket=bucket,Key=json_file_name) file_reader = json_object['Body'].read().decode("utf-8") file_reader = ast.literal_eval(file_reader) - Here first we will use dynamodb.Table(‘user’) function which will return our user table information which will be saved in table variable. Make sure to check official documentation here
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] json_file_name = event['Records'][0]['s3']['object']['key'] json_object = s3_client.get_object(Bucket=bucket,Key=json_file_name) file_reader = json_object['Body'].read().decode("utf-8") file_reader = ast.literal_eval(file_reader) table = dynamodb_client.Table('user') - Now we will use put_item() to push items into the user table. You can find official documentation here.
def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] json_file_name = event['Records'][0]['s3']['object']['key'] json_object = s3_client.get_object(Bucket=bucket,Key=json_file_name) file_reader = json_object['Body'].read().decode("utf-8") file_reader = ast.literal_eval(file_reader) table = dynamodb_client.Table('user') table.put_item(Item=file_reader) return "success"To view entire github code please click here
Set Event For S3 bucket
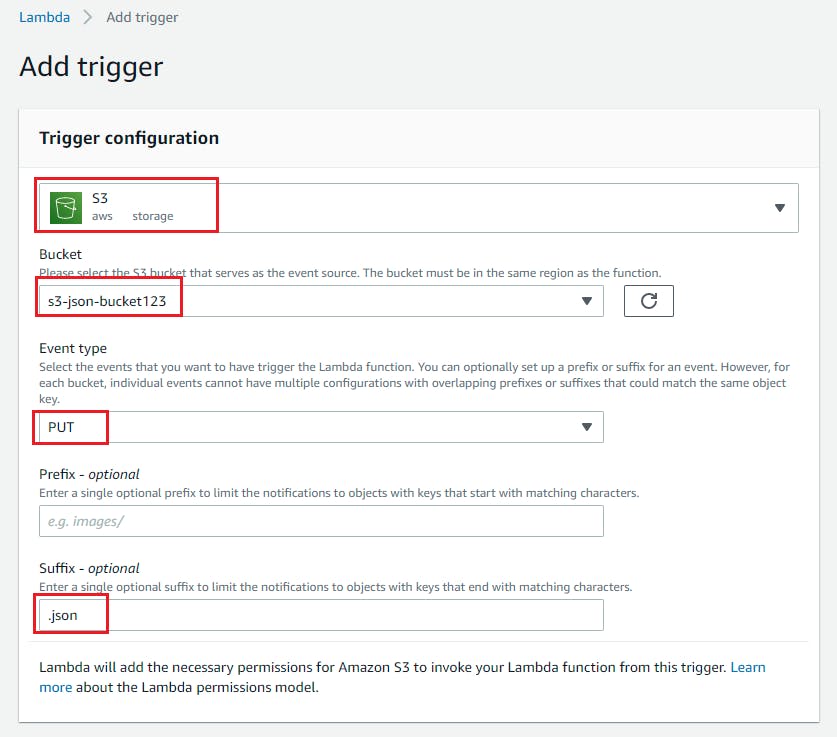
- Open Lambda function and click on add trigger
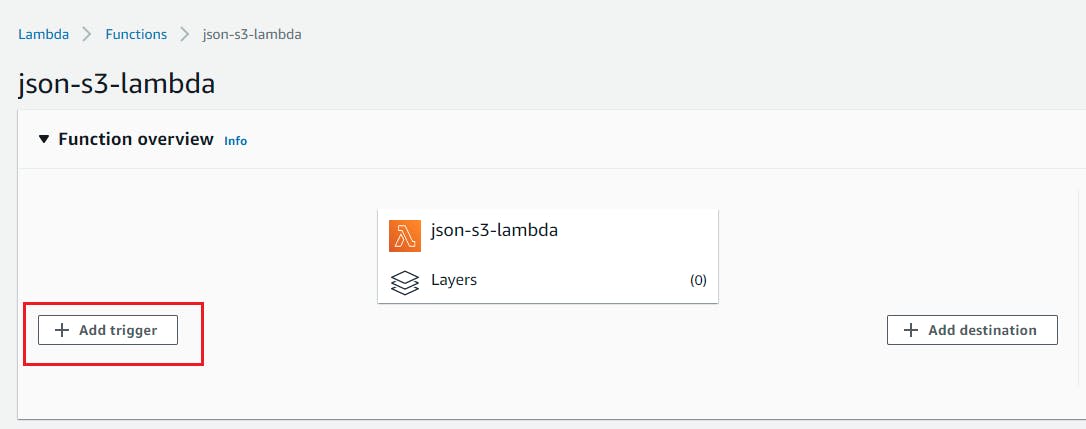
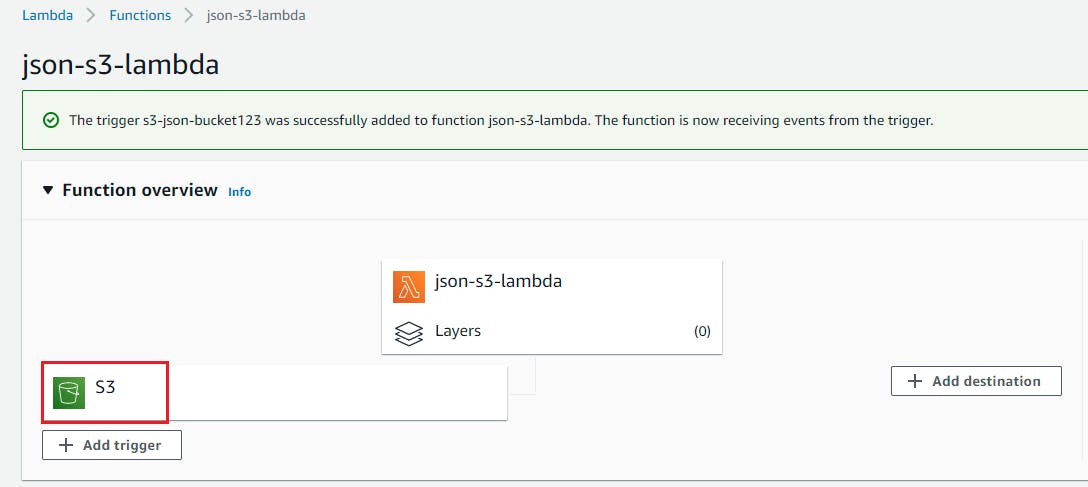
- Select S3 as trigger target and select the bucket we have created above and select event type as “PUT” and add suffix as “.json” Click on Add.
Create JSON File And Upload It To S3 Bucket
- Create .json file with below code
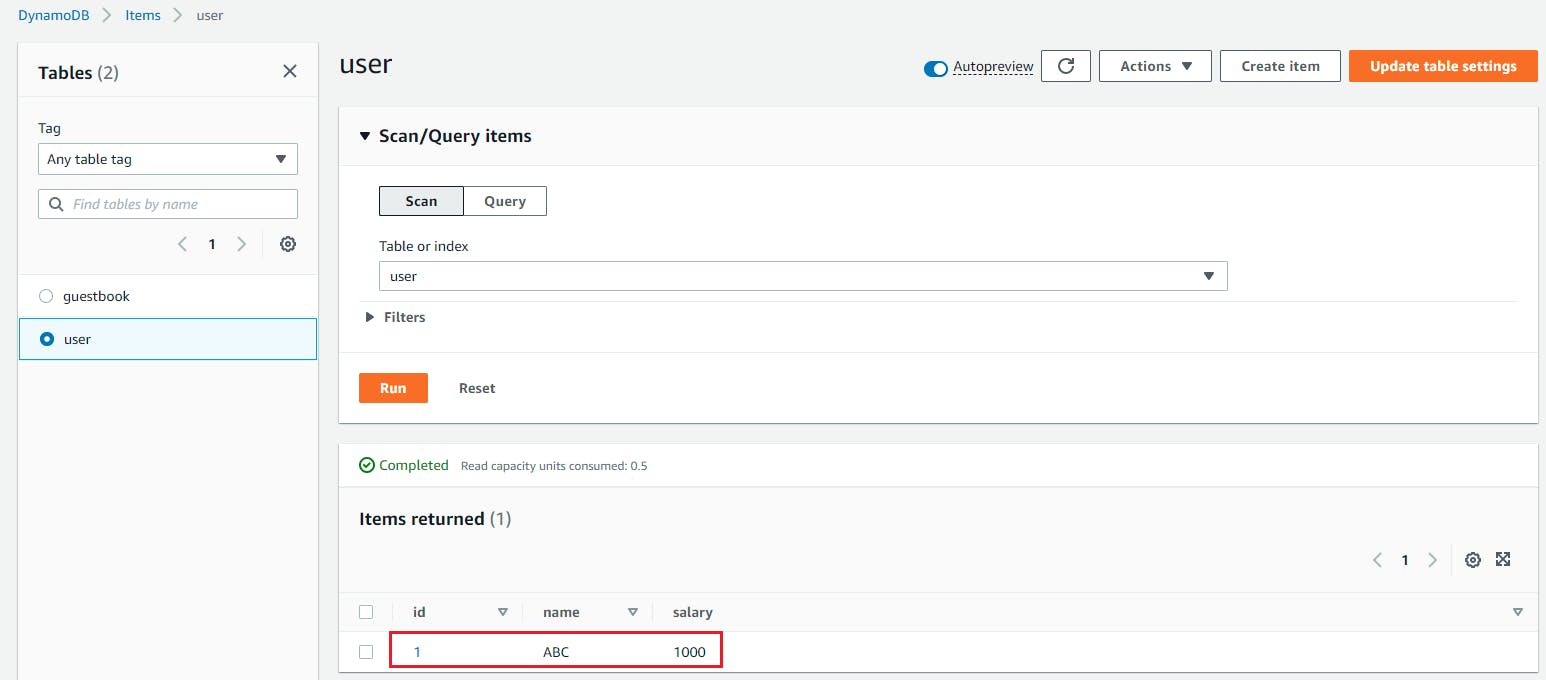
{ 'id': 1, 'name': 'ABC', 'salary': '1000' } - Now upload this file to S3 bucket and it will process the data and push this data to DynamoDB.


Author - Dheeraj Choudhary
I am an IT Professional with 11+ years of experience specializing in DevOps & Build and Release Engineering, Software configuration management in automating, build, deploy and release.
I blog about AWS and DevOps on my YouTube channel, which focuses on content such as, AWS, DevOps, open source, AI-ML and AWS community activities.

Set AWS Cloudwatch log groups Retention Policy for all Log using python boto3 script
In this blog we will write python script using boto3 which will set retention policy for all existing log groups which are already created i ...

List,Create And Delete S3 Buckets Using Python Boto3 Script
In this blog we are going to create python script to list, create and delete S3 buckets using boto3.Table Of ContentPrerequisite.Create S3 B ...