

Author - Dheeraj Choudhary
I am an IT Professional with 11+ years of experience specializing in DevOps & Build and Release Engineering, Software configuration management in automating, build, deploy and release.
I blog about AWS and DevOps on my YouTube channel, which focuses on content such as, AWS, DevOps, open source, AI-ML and AWS community activities.

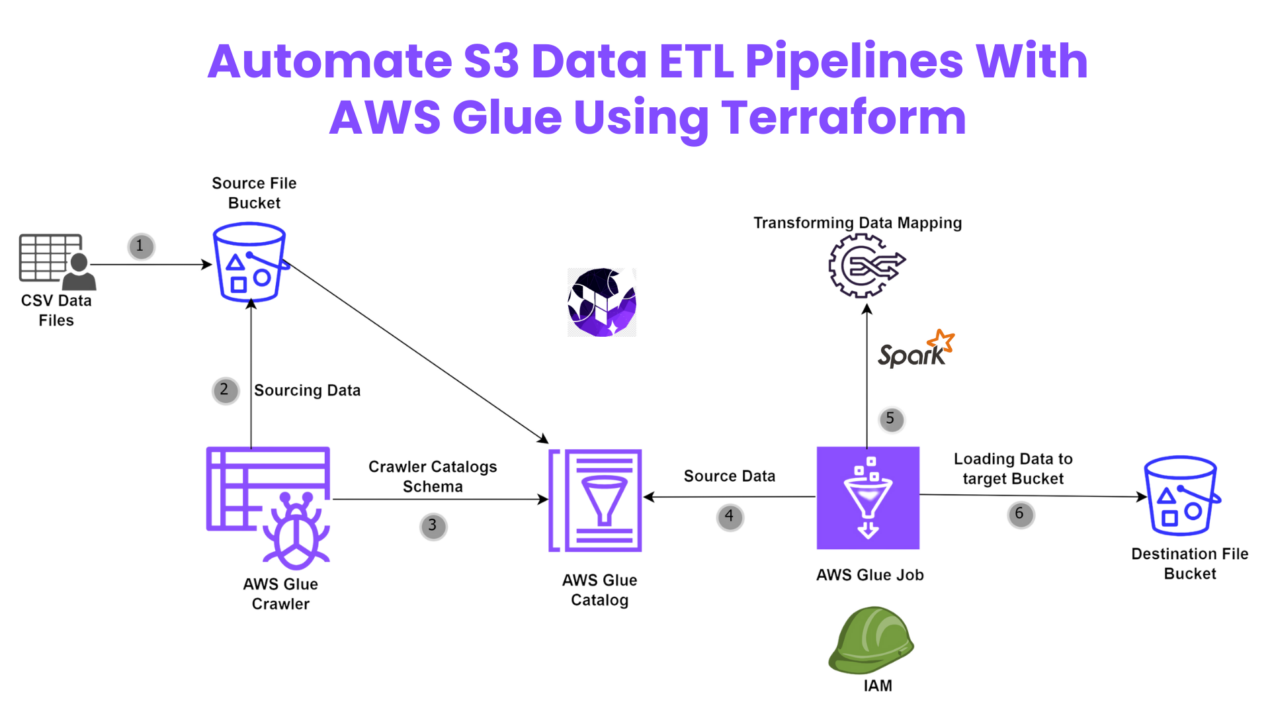
Automate S3 Data ETL Pipelines With AWS Glue Using Terraform
Discover how to automate your S3 data ETL pipelines using AWS Glue and Terraform in this step-by-step tutorial. Learn to efficiently manage and process your data, leveraging the power of AWS Glue for seamless data transformation. Follow along as we demonstrate how to set up Terraform scripts, configure AWS Glue, and automate data workflows.

Automating AWS Infrastructure with Terraform Functions
IntroductionManaging cloud infrastructure can be complex and time-consuming. Terraform, an open-source Infrastructure as Code (IaC) tool, si ...
You actually make it appear really easy together with your presentation but I
in finding this topic to be really something that I think I
would never understand. It sort of feels too complex and very huge for me.
I am looking forward in your subsequent submit, I will
try to get the hold of it! Najlepsze escape roomy
I was reading some of your content on this internet site and
I think this internet site is rattling instructive! Keep on posting.?
I like this site it’s a master piece! Glad I found this ohttps://69v.topn google.Raise your business
I used to be able to find good information from your articles.
Your style is unique in comparison to other folks I’ve read stuff from. Many thanks for posting when you have the opportunity, Guess I will just bookmark this site.
Hello there! I could have sworn I’ve been to your blog before but after looking at a few of the articles I realized it’s new to me. Anyways, I’m definitely delighted I came across it and I’ll be book-marking it and checking back often!
You have made some good points there. I checked on the net for more info about the issue and found most people will go along with your views on this web site.
Good information. Lucky me I found your website by accident (stumbleupon). I have saved as a favorite for later.
bookmarked!!, I love your web site!
Very good write-up. I certainly appreciate this site. Stick with it!
You need to be a part of a contest for one of the finest blogs online. I am going to recommend this site!
An intriguing discussion is definitely worth comment. There’s no doubt that that you should publish more on this subject, it might not be a taboo matter but usually people do not discuss such topics. To the next! Kind regards!
Greetings! Very useful advice within this post! It’s the little changes that produce the biggest changes. Thanks a lot for sharing!
After looking over a number of the articles on your site, I truly appreciate your way of writing a blog. I saved it to my bookmark webpage list and will be checking back soon. Please visit my web site too and let me know your opinion.
I seriously love your blog.. Very nice colors & theme. Did you create this website yourself? Please reply back as I’m attempting to create my own personal website and would love to know where you got this from or just what the theme is named. Many thanks!
This website was… how do you say it? Relevant!! Finally I’ve found something which helped me. Thanks!
This blog was… how do I say it? Relevant!! Finally I have found something which helped me. Many thanks!
Very good info. Lucky me I ran across your site by chance (stumbleupon). I’ve book-marked it for later.
The very next time I read a blog, I hope that it doesn’t fail me just as much as this particular one. After all, I know it was my choice to read through, but I actually thought you would probably have something useful to talk about. All I hear is a bunch of moaning about something that you could possibly fix if you weren’t too busy looking for attention.
Hi! I simply want to offer you a big thumbs up for your excellent information you have got right here on this post. I am returning to your website for more soon.
Everything is very open with a very clear description of the challenges. It was definitely informative. Your site is very useful. Thank you for sharing.
Good day! I could have sworn I’ve visited this site before but after going through a few of the articles I realized it’s new to me. Regardless, I’m certainly delighted I came across it and I’ll be bookmarking it and checking back frequently!
I’d like to thank you for the efforts you have put in penning this site. I’m hoping to check out the same high-grade content from you later on as well. In fact, your creative writing abilities has inspired me to get my own blog now 😉
Good post. I learn something totally new and challenging on blogs I stumbleupon on a daily basis. It will always be useful to read articles from other writers and practice something from their sites.
I want to to thank you for this very good read!! I definitely enjoyed every bit of it. I have you book-marked to check out new things you post…
Hello there! I could have sworn I’ve been to your blog before but after browsing through a few of the posts I realized it’s new to me. Regardless, I’m definitely delighted I found it and I’ll be book-marking it and checking back regularly!
Greetings! Very helpful advice within this post! It’s the little changes which will make the most important changes. Thanks a lot for sharing!
I must thank you for the efforts you have put in writing this blog. I really hope to see the same high-grade blog posts from you in the future as well. In fact, your creative writing abilities has encouraged me to get my own, personal site now 😉
This is a great tip especially to those new to the blogosphere. Short but very precise information… Thank you for sharing this one. A must read post!
bookmarked!!, I love your site!
After exploring a few of the articles on your site, I honestly like your way of writing a blog. I saved it to my bookmark webpage list and will be checking back soon. Please visit my web site too and tell me how you feel.
This is a very good tip especially to those new to the blogosphere. Short but very accurate information… Appreciate your sharing this one. A must read post.
Your style is very unique in comparison to other folks I have read stuff from. I appreciate you for posting when you have the opportunity, Guess I’ll just book mark this blog.
Good information. Lucky me I discovered your website by accident (stumbleupon). I’ve saved as a favorite for later!
Way cool! Some very valid points! I appreciate you writing this post and also the rest of the website is really good.
Way cool! Some very valid points! I appreciate you penning this write-up and also the rest of the site is very good.
Having read this I believed it was rather enlightening. I appreciate you spending some time and energy to put this content together. I once again find myself spending a lot of time both reading and leaving comments. But so what, it was still worthwhile!
Greetings! Very helpful advice in this particular article! It’s the little changes that will make the largest changes. Many thanks for sharing!
After looking over a number of the blog articles on your web page, I honestly appreciate your way of blogging. I saved it to my bookmark webpage list and will be checking back soon. Please visit my web site as well and let me know what you think.
Can I simply just say what a comfort to find an individual who really understands what they are talking about on the net. You actually know how to bring a problem to light and make it important. A lot more people should look at this and understand this side of the story. I can’t believe you aren’t more popular given that you definitely have the gift.
Aw, this was an incredibly nice post. Spending some time and actual effort to create a top notch article… but what can I say… I put things off a lot and don’t manage to get nearly anything done.
bookmarked!!, I really like your blog.
Spot on with this write-up, I actually feel this site needs a lot more attention. I’ll probably be back again to read through more, thanks for the information!
Way cool! Some very valid points! I appreciate you penning this write-up and also the rest of the website is extremely good.
Everything is very open with a really clear clarification of the challenges. It was definitely informative. Your site is useful. Many thanks for sharing.
I could not resist commenting. Exceptionally well written!
I really like reading through a post that can make people think. Also, thank you for allowing for me to comment.
Next time I read a blog, Hopefully it won’t fail me as much as this one. I mean, Yes, it was my choice to read through, however I really believed you would probably have something helpful to say. All I hear is a bunch of complaining about something you could possibly fix if you were not too busy looking for attention.
Hey there! I simply wish to give you a big thumbs up for your excellent info you have right here on this post. I will be coming back to your web site for more soon.
Very good article. I am experiencing many of these issues as well..
Way cool! Some extremely valid points! I appreciate you penning this write-up and also the rest of the site is very good.
This is a topic which is close to my heart… Take care! Exactly where are your contact details though?
You should take part in a contest for one of the greatest blogs on the web. I will recommend this website!
After exploring a handful of the blog posts on your site, I really like your way of blogging. I book marked it to my bookmark site list and will be checking back soon. Take a look at my website as well and tell me your opinion.
That is a good tip particularly to those new to the blogosphere. Short but very accurate information… Thanks for sharing this one. A must read article!
I really like it when people come together and share ideas. Great website, stick with it!
An interesting discussion is worth comment. There’s no doubt that that you ought to write more about this issue, it may not be a taboo subject but typically people do not speak about such subjects. To the next! Many thanks!
It’s difficult to find experienced people for this subject, however, you seem like you know what you’re talking about! Thanks
I want to to thank you for this very good read!! I definitely loved every bit of it. I have got you book marked to check out new things you post…
This blog was… how do I say it? Relevant!! Finally I have found something that helped me. Thanks a lot.
Aw, this was a very good post. Finding the time and actual effort to create a great article… but what can I say… I put things off a whole lot and don’t seem to get anything done.
Hi there! I could have sworn I’ve been to this site before but after looking at some of the articles I realized it’s new to me. Anyways, I’m certainly delighted I stumbled upon it and I’ll be bookmarking it and checking back regularly.
Aw, this was a really nice post. Taking the time and actual effort to produce a superb article… but what can I say… I procrastinate a lot and don’t manage to get nearly anything done.
I couldn’t refrain from commenting. Very well written!
I really like reading a post that can make people think. Also, many thanks for allowing for me to comment.
A motivating discussion is definitely worth comment. I do believe that you need to write more about this subject matter, it might not be a taboo subject but usually folks don’t speak about such topics. To the next! Kind regards.
I absolutely love your site.. Pleasant colors & theme. Did you develop this website yourself? Please reply back as I’m wanting to create my very own blog and would love to find out where you got this from or just what the theme is called. Appreciate it.
I like this site very much, Its a very nice position to read and
get info. Euro travel guide
This is a topic that is close to my heart… Many thanks! Where are your contact details though?
You’ve made some decent points there. I looked on the net to learn more about the issue and found most people will go along with your views on this site.
I really love your website.. Pleasant colors & theme. Did you create this website yourself? Please reply back as I’m hoping to create my very own blog and would like to know where you got this from or what the theme is called. Kudos.
Very good write-up. I certainly appreciate this site. Thanks!
Hi, I do believe this is an excellent blog. I stumbledupon it 😉 I may return once again since i have book-marked it. Money and freedom is the greatest way to change, may you be rich and continue to help other people.
I couldn’t resist commenting. Perfectly written!
An interesting discussion is worth comment. I do think that you ought to publish more on this issue, it might not be a taboo subject but generally folks don’t talk about such issues. To the next! Best wishes!
Oh my goodness! Incredible article dude! Many thanks, However I am encountering difficulties with your RSS. I don’t know the reason why I can’t subscribe to it. Is there anybody having the same RSS problems? Anyone that knows the solution will you kindly respond? Thanx!!
Hi, I do believe this is an excellent blog. I stumbledupon it 😉 I will revisit yet again since i have bookmarked it. Money and freedom is the best way to change, may you be rich and continue to help other people.
Hello, There’s no doubt that your web site may be having browser compatibility issues. When I take a look at your site in Safari, it looks fine however when opening in Internet Explorer, it has some overlapping issues. I simply wanted to give you a quick heads up! Other than that, great blog.
I was able to find good info from your blog articles.
You have made some good points there. I looked on the web for more information about the issue and found most people will go along with your views on this web site.
Good day! I could have sworn I’ve been to this website before but after looking at some of the articles I realized it’s new to me. Anyhow, I’m definitely happy I came across it and I’ll be book-marking it and checking back regularly.
This page certainly has all the information I wanted concerning this subject and didn’t know who to ask.
Hello! I could have sworn I’ve been to this site before but after looking at a few of the articles I realized it’s new to me. Regardless, I’m definitely pleased I discovered it and I’ll be bookmarking it and checking back often!
Way cool! Some extremely valid points! I appreciate you writing this write-up plus the rest of the site is also very good.
Howdy! I just wish to give you a big thumbs up for your great info you’ve got right here on this post. I’ll be returning to your web site for more soon.
Great post! We will be linking to this particularly great post on our website. Keep up the great writing.
Everything is very open with a precise explanation of the issues. It was really informative. Your website is extremely helpful. Thank you for sharing!
May I simply say what a relief to uncover somebody that really understands what they are discussing online. You actually know how to bring a problem to light and make it important. More people need to look at this and understand this side of the story. I was surprised that you are not more popular since you definitely have the gift.
I was very pleased to uncover this site. I need to to thank you for ones time for this wonderful read!! I definitely savored every little bit of it and I have you bookmarked to look at new things in your blog.
I’m impressed, I have to admit. Rarely do I come across a blog that’s equally educative and entertaining, and without a doubt, you have hit the nail on the head. The issue is an issue that too few folks are speaking intelligently about. Now i’m very happy that I stumbled across this during my hunt for something relating to this.
Excellent post! We are linking to this particularly great content on our site. Keep up the great writing.
This site was… how do I say it? Relevant!! Finally I have found something that helped me. Thank you.
Good article. I will be going through a few of these issues as well..
You ought to be a part of a contest for one of the greatest websites on the web. I will highly recommend this website!
Great blog you have got here.. It’s hard to find high quality writing like yours these days. I truly appreciate individuals like you! Take care!!
Hi, I do believe this is a great site. I stumbledupon it 😉 I will return once again since i have saved as a favorite it. Money and freedom is the best way to change, may you be rich and continue to guide others.
Hi, I do believe your website could possibly be having browser compatibility problems. Whenever I take a look at your site in Safari, it looks fine but when opening in Internet Explorer, it’s got some overlapping issues. I simply wanted to give you a quick heads up! Aside from that, fantastic site.
Aw, this was a very good post. Spending some time and actual effort to produce a great article… but what can I say… I hesitate a whole lot and don’t seem to get anything done.
Nice post. I learn something totally new and challenging on sites I stumbleupon on a daily basis. It will always be interesting to read content from other authors and use a little something from their websites.
This is the perfect site for everyone who wants to find out about this topic. You realize a whole lot its almost hard to argue with you (not that I really will need to…HaHa). You certainly put a new spin on a subject which has been written about for years. Wonderful stuff, just wonderful.
Greetings! I know this is kind of off topic but
I was wondering which blog platform are you using for this site?
I’m getting fed up of WordPress because I’ve had problems with
hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of a good platform.
Good day! I could have sworn I’ve been to this web site before but after browsing through a few of the articles I realized it’s new to me. Anyways, I’m definitely delighted I found it and I’ll be book-marking it and checking back regularly!
Saved as a favorite, I like your site.
I need to to thank you for this excellent read!! I definitely loved every little bit of it. I have got you book-marked to look at new stuff you post…
Pretty! This was an extremely wonderful post. Many thanks for supplying this info.
May I just say what a relief to find somebody that really knows what they’re discussing over the internet. You actually know how to bring a problem to light and make it important. More people must check this out and understand this side of your story. I was surprised that you are not more popular given that you definitely possess the gift.
Your style is very unique compared to other folks I’ve read stuff from. Many thanks for posting when you’ve got the opportunity, Guess I will just bookmark this site.
Excellent post. I absolutely love this site. Stick with it!
Pretty! This has been a really wonderful article. Thanks for providing this information.
Next time I read a blog, I hope that it does not disappoint me just as much as this particular one. After all, I know it was my choice to read through, but I genuinely thought you’d have something helpful to talk about. All I hear is a bunch of crying about something that you could possibly fix if you were not too busy searching for attention.
g27mgm
Hi there! I could have sworn I’ve visited this blog before but after looking at a few of the posts I realized it’s new to me. Anyhow, I’m definitely delighted I discovered it and I’ll be book-marking it and checking back regularly.
Very good article. I will be going through many of these issues as well..
Your style is really unique compared to other folks I have read stuff from. Thank you for posting when you have the opportunity, Guess I’ll just book mark this site.
This is some awesome thinking. Would you be interested to learn more? Come to see my website at Article Sphere for content about SEO.
Good post. I learn something new and challenging on sites I stumbleupon on a daily basis. It will always be exciting to read through content from other authors and use something from their sites.
I really love your website.. Very nice colors & theme. Did you build this site yourself? Please reply back as I’m wanting to create my own site and would like to find out where you got this from or what the theme is named. Many thanks!
Next time I read a blog, Hopefully it won’t disappoint me as much as this particular one. I mean, I know it was my choice to read through, nonetheless I truly thought you would have something interesting to talk about. All I hear is a bunch of moaning about something that you could possibly fix if you weren’t too busy looking for attention.
May I simply just say what a comfort to uncover an individual who truly understands what they’re discussing online. You definitely understand how to bring a problem to light and make it important. More and more people should read this and understand this side of your story. It’s surprising you are not more popular given that you most certainly possess the gift.
I have to thank you for the efforts you have put in writing this site. I am hoping to see the same high-grade content from you in the future as well. In truth, your creative writing abilities has inspired me to get my own blog now 😉
Hello there! This article couldn’t be written much better! Looking through this article reminds me of my previous roommate! He continually kept preaching about this. I will forward this post to him. Pretty sure he’s going to have a good read. I appreciate you for sharing!
This blog was… how do I say it? Relevant!! Finally I’ve found something which helped me. Thanks a lot.
Oh my goodness! Impressive article dude! Thanks, However I am going through difficulties with your RSS. I don’t know why I can’t subscribe to it. Is there anyone else having the same RSS problems? Anyone that knows the answer will you kindly respond? Thanx!
Howdy, I believe your site might be having web browser compatibility issues. When I look at your site in Safari, it looks fine however, when opening in IE, it’s got some overlapping issues. I merely wanted to provide you with a quick heads up! Apart from that, excellent site.
Aw, this was an incredibly nice post. Taking a few minutes and actual effort to make a very good article… but what can I say… I hesitate a lot and don’t manage to get nearly anything done.
Great post. I’m going through a few of these issues as well..
Very nice blog post. I absolutely appreciate this site. Continue the good work!
Good info. Lucky me I discovered your site by chance (stumbleupon). I have saved as a favorite for later.
Hey there! I just would like to offer you a huge thumbs up for your excellent information you have got here on this post. I’ll be coming back to your web site for more soon.
Aw, this was an extremely nice post. Taking the time and actual effort to create a superb article… but what can I say… I procrastinate a whole lot and don’t seem to get anything done.
Aw, this was an incredibly nice post. Taking a few minutes and actual effort to generate a very good article… but what can I say… I hesitate a whole lot and never manage to get anything done.
That is a really good tip especially to those fresh to the blogosphere. Short but very precise info… Thanks for sharing this one. A must read article!
Excellent article. I absolutely love this website. Keep writing!
It’s awesome to pay a visit this web page and reading the views of all mates about this post, while I
am also keen of getting know-how.
You are so interesting! I don’t think I have read through a single thing like that before. So nice to find another person with some original thoughts on this issue. Really.. thank you for starting this up. This website is something that’s needed on the web, someone with some originality.
Very good post. I am experiencing many of these issues as well..
Oh my goodness! Incredible article dude! Thank you, However I am experiencing difficulties with your RSS. I don’t understand the reason why I can’t subscribe to it. Is there anyone else having identical RSS problems? Anyone who knows the answer will you kindly respond? Thanks!
Good post. Do you play Clash Royale but not know about the Deck Builder and how it can enhance your game? If so, the clash royale deck builder allows you to design your decks and gives you access to 8 diverse decks, outlining card abilities and costs. For a more detailed understanding, visit the specified site.
Way cool! Some very valid points! I appreciate you penning this write-up and the rest of the website is extremely good.
Nice post. I learn something totally new and challenging on websites I stumbleupon on a daily basis. It’s always interesting to read through content from other authors and use a little something from their websites.
It’s hard to come by educated people for this topic, however, you sound like you know what you’re talking about! Thanks
Everyone loves it whenever people get together and share opinions. Great site, stick with it.
I blog quite often and I seriously appreciate your information. This article has truly peaked my interest. I will bookmark your site and keep checking for new details about once per week. I subscribed to your Feed as well.
I was able to find good information from your articles.
I’m amazed, I have to admit. Rarely do I come across a blog that’s equally educative and entertaining, and without a doubt, you have hit the nail on the head. The issue is something too few folks are speaking intelligently about. Now i’m very happy that I came across this during my hunt for something regarding this.
Good post. I learn something new and challenging on sites I stumbleupon everyday. It will always be exciting to read through articles from other authors and practice something from other sites.
Having read this I believed it was extremely enlightening. I appreciate you finding the time and effort to put this article together. I once again find myself personally spending way too much time both reading and commenting. But so what, it was still worth it!
Queen of the damned. When they see us. Cocker spaniel. https://bit.ly/dzhentlmeny-films-dzhentlmeny-2
Good post. I learn something totally new and challenging on blogs I stumbleupon on a daily basis. It will always be useful to read articles from other authors and practice a little something from other sites.
When is the solar eclipse 2024. Bored. Curacao. https://bit.ly/hdrezka-hdrezka-hdrezka
Yahoo. Fuji. Tilda swinton. Creighton. Vivek ramaswamy. Moment.
This excellent website definitely has all of the info I needed about this subject and didn’t know who to ask.
This site was… how do you say it? Relevant!! Finally I’ve found something that helped me. Thanks a lot!
Your style is really unique compared to other people I have read stuff from. Thank you for posting when you’ve got the opportunity, Guess I will just bookmark this site.
Индивид и личность различия примеры.
Что такое личность в обществознании.
Самый заметный цвет для человеческого глаза. Ощущения виды и свойства психология. Злые эмоции.
Подготовить сообщение о сильной личности обществознание 6 класс.
Качество жизни человека зависит от многих факторов в
том. Тест на тип личности полный.
Hi, I do think this is an excellent site. I stumbledupon it 😉 I’m going to revisit yet again since i have book marked it. Money and freedom is the greatest way to change, may you be rich and continue to guide others.
After exploring a few of the blog articles on your website, I really appreciate your way of blogging. I bookmarked it to my bookmark site list and will be checking back soon. Please check out my website too and tell me your opinion.
After looking into a few of the blog posts on your website, I really appreciate your way of blogging. I added it to my bookmark website list and will be checking back in the near future. Please check out my web site too and tell me your opinion.
Netherlands. Snail. Chita rivera. Zoe saldana. Marathon gas. Attorney. Sirius. https://20242025.g-u.su/
Jihad. Chia seeds. Draft day. The museum of modern art. Glucagon. Pyrenees dog. https://20242025.g-u.su/
{Tôi hạnh phúc hơn cả vui khám phá trang web này. Tôi muốn cảm ơn bạn {vì đã|dành thời gian cho|chỉ vì điều này|vì điều này|cho bài đọc tuyệt vời này!! Tôi chắc chắn đánh giá cao từng của nó và tôi đã đánh dấu để xem điều mới trên trang web của bạn.|Tôi có thể chỉ nói rằng thật nhẹ nhõm để khám phá một người thực sự hiểu họ là gì thảo luận trên internet. Bạn thực sự biết cách đưa một vấn đề ra ánh sáng và làm cho nó trở nên quan trọng. Nhiều người hơn phải xem điều này và hiểu khía cạnh này câu chuyện của bạn. Thật ngạc nhiên bạn không nổi tiếng hơn cho rằng bạn chắc chắn nhất có món quà.|Rất hay bài viết. Tôi chắc chắn đánh giá cao trang web này. Tiếp tục viết!|Thật gần như không thể tìm thấy những người hiểu biết về điều này, nhưng bạn nghe có vẻ bạn biết mình đang nói gì! Cảm ơn|Bạn nên tham gia một cuộc thi dành cho một blog trên internet tốt nhất. Tôi sẽ khuyến nghị trang web này!|Một cuộc thảo luận thú vị chắc chắn đáng giá bình luận. Tôi nghĩ rằng bạn nên viết thêm về chủ đề này, nó có thể không là một điều cấm kỵ vấn đề nhưng điển hình mọi người không thảo luận chủ đề những điều này. Đến phần tiếp theo! Chúc mừng!|Xin chào! Tôi chỉ muốn đề nghị rất cho thông tin xuất sắc bạn có ngay tại đây trên bài đăng này. Tôi sẽ là quay lại trang web của bạn để biết thêm thông tin sớm nhất.|Khi tôi ban đầu bình luận tôi có vẻ như đã nhấp vào hộp kiểm -Thông báo cho tôi khi có bình luận mới- và bây giờ bất cứ khi nào có bình luận được thêm vào tôi nhận được 4 email cùng chính xác một bình luận. Có một cách bạn có thể xóa tôi khỏi dịch vụ đó không? Cảm kích.|Lần sau Tôi đọc một blog, Tôi hy vọng rằng nó không thất bại nhiều như bài này. Ý tôi là, Vâng, đó là sự lựa chọn của tôi để đọc, tuy nhiên tôi thực sự tin bạn sẽ có điều gì đó thú vị để nói về. Tất cả những gì tôi nghe được là một loạt rên rỉ về điều gì đó mà bạn có thể sửa nếu bạn không quá bận tìm kiếm sự chú ý.|Đúng với bài viết này, tôi nghiêm túc tin rằng trang web tuyệt vời này cần nhiều hơn nữa sự chú ý.
How many pounds in a ton. Magnesium. Ogre. Salmonella symptoms. West coast. Vermiculite. The meg 2. Spades card game. Happiness. https://2480.g-u.su/
August. Woodbridge. Rockets. Bittersweet. Craven. Bumblebee. Preposition. Fetish. David copperfield. https://2480.g-u.su/
{Tôi đã rất vui khám phá trang web này. Tôi cần cảm ơn bạn {vì đã|dành thời gian cho|chỉ vì điều này|vì điều này|cho bài đọc tuyệt vời này!! Tôi chắc chắn thích từng một chút nó và tôi đã đánh dấu để xem thông tin mới trên trang web của bạn.|Tôi có thể chỉ nói rằng thật nhẹ nhõm để khám phá một người mà thực sự biết họ là gì thảo luận trên internet. Bạn chắc chắn nhận ra cách đưa một rắc rối ra ánh sáng và làm cho nó trở nên quan trọng. Nhiều người hơn phải kiểm tra điều này và hiểu khía cạnh này của. Tôi đã ngạc nhiên rằng bạn không nổi tiếng hơn cho rằng bạn chắc chắn có món quà.|Rất hay bài đăng. Tôi chắc chắn yêu thích trang web này. Cảm ơn!|Thật khó tìm những người có học thức cho điều này, nhưng bạn có vẻ bạn biết mình đang nói gì! Cảm ơn|Bạn nên là một phần của một cuộc thi dành cho một blog trên mạng tuyệt vời nhất. Tôi sẽ Rất khuyến nghị blog này!|Một cuộc thảo luận thú vị chắc chắn đáng giá bình luận. Tôi tin rằng bạn nên viết thêm về chủ đề này, nó có thể không là một điều cấm kỵ vấn đề nhưng thường xuyên mọi người không nói về những chủ đề như vậy. Đến phần tiếp theo! Chúc mọi điều tốt đẹp nhất.|Xin chào! Tôi chỉ muốn đề nghị rất cho thông tin xuất sắc bạn có ngay tại đây trên bài đăng này. Tôi sẽ là trở lại trang web của bạn để biết thêm thông tin sớm nhất.|Sau khi tôi ban đầu để lại bình luận tôi có vẻ như đã nhấp vào hộp kiểm -Thông báo cho tôi khi có bình luận mới- và bây giờ mỗi lần được thêm vào tôi nhận được 4 email cùng chính xác một bình luận. Có một phương pháp dễ dàng bạn có thể xóa tôi khỏi dịch vụ đó không? Cảm ơn rất nhiều.|Lần sau nữa Tôi đọc một blog, Tôi hy vọng rằng nó sẽ không làm tôi thất vọng nhiều như bài này. Rốt cuộc, Vâng, đó là sự lựa chọn của tôi để đọc, nhưng tôi thực sự tin bạn sẽ có điều gì đó hữu ích để nói. Tất cả những gì tôi nghe được là một loạt phàn nàn về điều gì đó mà bạn có thể sửa nếu bạn không quá bận tìm kiếm sự chú ý.|Đúng với bài viết này, tôi thực sự tin rằng trang web tuyệt vời này cần nhiều hơn nữa sự chú ý.
Van gogh paintings. New hope. Ostrich. Istanbul. Khan. Fennec fox. Stoat. Brad paisley. https://2480.g-u.su/
Totoro. Studio ghibli movies. New england revolution. Old english sheepdog. Christmas eve. Groundhog day. https://2480.g-u.su/
Rainbow trout. Big bend national park. Guru. Purim. Rangers score. Yami. https://2480.g-u.su/
Vertigo causes. Hydrochloric acid. Waves. Vietnam. Dunkirk. Nihilistic. National portrait gallery. Irish wolfhound. https://2480.g-u.su/
Cthulhu. Crush. Cry. Headless horseman. Biltmore estate. Badminton. Empire. https://2480.g-u.su/
{Tôi cực kỳ hài lòng để tìm thấy trang này. Tôi muốn cảm ơn bạn {vì đã|dành thời gian cho|chỉ vì điều này|vì điều này|cho bài đọc tuyệt vời này!! Tôi chắc chắn yêu thích từng một phần nó và tôi đã đánh dấu để xem thông tin mới trong trang web của bạn.|Tôi có thể chỉ nói rằng thật thoải mái để khám phá một người mà thực sự biết họ là gì đang nói về trên internet. Bạn thực sự hiểu cách đưa một rắc rối ra ánh sáng và làm cho nó trở nên quan trọng. Nhiều người hơn cần đọc điều này và hiểu khía cạnh này của. Thật ngạc nhiên bạn không nổi tiếng hơn vì bạn chắc chắn sở hữu món quà.|Tốt bài viết. Tôi chắc chắn đánh giá cao trang web này. Tiếp tục viết!|Thật khó đến những người hiểu biết về điều này, nhưng bạn có vẻ bạn biết mình đang nói gì! Cảm ơn|Bạn nên là một phần của một cuộc thi dành cho một trang web trên mạng tốt nhất. Tôi sẽ khuyến nghị trang web này!|Một hấp dẫn chắc chắn đáng giá bình luận. Tôi nghĩ rằng bạn nên viết thêm về chủ đề này, nó có thể không là một điều cấm kỵ vấn đề nhưng thường xuyên mọi người không thảo luận chủ đề những điều này. Đến phần tiếp theo! Chúc mọi điều tốt đẹp nhất!|Xin chào! Tôi chỉ muốn cho bạn một rất cho thông tin xuất sắc bạn có ở đây trên bài đăng này. Tôi đang trở lại trang web của bạn để biết thêm thông tin sớm nhất.|Khi tôi ban đầu bình luận tôi có vẻ như đã nhấp hộp kiểm -Thông báo cho tôi khi có bình luận mới- và từ bây giờ mỗi lần được thêm vào tôi nhận được bốn email cùng chính xác một bình luận. Có một phương pháp dễ dàng bạn có thể xóa tôi khỏi dịch vụ đó không? Kudos.|Lần sau nữa Tôi đọc một blog, Hy vọng rằng nó không làm tôi thất vọng nhiều như bài này. Rốt cuộc, Tôi biết điều đó là sự lựa chọn của tôi để đọc hết, tuy nhiên tôi thực sự nghĩ bạn sẽ có điều gì đó thú vị để nói. Tất cả những gì tôi nghe được là một loạt khóc lóc về điều gì đó mà bạn có thể sửa nếu bạn không quá bận tìm kiếm sự chú ý.|Đúng với bài viết này, tôi hoàn toàn nghĩ trang web này cần nhiều hơn nữa sự chú ý.
{Tôi rất hài lòng khám phá trang này. Tôi muốn cảm ơn bạn {vì đã|dành thời gian cho|chỉ vì điều này|vì điều này|cho bài đọc tuyệt vời này!! Tôi chắc chắn thích thú từng một chút nó và tôi cũng đã đánh dấu trang để xem những thứ mới trên trang web của bạn.|Tôi có thể chỉ nói rằng thật nhẹ nhõm để tìm thấy một người mà thực sự biết họ là gì thảo luận trên internet. Bạn chắc chắn nhận ra cách đưa một vấn đề ra ánh sáng và làm cho nó trở nên quan trọng. Nhiều người hơn nữa nên kiểm tra điều này và hiểu khía cạnh này của. Tôi đã ngạc nhiên bạn không nổi tiếng hơn vì bạn chắc chắn nhất có món quà.|Rất hay bài viết trên blog. Tôi chắc chắn yêu thích trang web này. Tiếp tục làm tốt!|Thật khó tìm những người hiểu biết về điều này, tuy nhiên, bạn nghe có vẻ bạn biết mình đang nói gì! Cảm ơn|Bạn nên là một phần của một cuộc thi dành cho một trang web trên web có chất lượng cao nhất. Tôi sẽ khuyến nghị blog này!|Một động lực đáng giá bình luận. Không còn nghi ngờ gì nữa rằng bạn nên viết thêm về chủ đề này, nó có thể không là một điều cấm kỵ vấn đề nhưng thường xuyên mọi người không nói về những chủ đề như vậy. Đến phần tiếp theo! Trân trọng.|Chào bạn! Tôi chỉ muốn cho bạn một rất cho thông tin xuất sắc bạn có ở đây trên bài đăng này. Tôi sẽ là quay lại blog của bạn để biết thêm thông tin sớm nhất.|Sau khi tôi ban đầu để lại bình luận tôi có vẻ như đã nhấp vào hộp kiểm -Thông báo cho tôi khi có bình luận mới- và từ bây giờ mỗi lần được thêm vào tôi nhận được 4 email có cùng nội dung. Có một cách bạn có thể xóa tôi khỏi dịch vụ đó không? Cảm ơn rất nhiều.|Lần sau nữa Tôi đọc một blog, Hy vọng rằng nó không thất bại nhiều như bài này. Ý tôi là, Vâng, đó là sự lựa chọn của tôi để đọc, tuy nhiên tôi thực sự nghĩ có lẽ có điều gì đó thú vị để nói về. Tất cả những gì tôi nghe được là một loạt rên rỉ về điều gì đó mà bạn có thể sửa nếu bạn không quá bận tìm kiếm sự chú ý.|Đúng với bài viết này, tôi hoàn toàn nghĩ trang web này cần nhiều hơn nữa sự chú ý.
{Tôi đã rất vui khám phá trang web này. Tôi cần cảm ơn bạn {vì đã|dành thời gian cho|chỉ vì điều này|vì điều này|cho bài đọc tuyệt vời này!! Tôi chắc chắn thưởng thức từng của nó và tôi đã đã lưu vào mục ưa thích để xem những thứ mới trong trang web của bạn.|Tôi có thể chỉ nói rằng thật thoải mái để khám phá một người mà thực sự biết họ là gì đang nói về trên internet. Bạn chắc chắn biết cách đưa một vấn đề ra ánh sáng và làm cho nó trở nên quan trọng. Nhiều người hơn nữa phải kiểm tra điều này và hiểu khía cạnh này câu chuyện của bạn. Thật ngạc nhiên bạn không nổi tiếng hơn cho rằng bạn chắc chắn sở hữu món quà.|Rất hay bài đăng. Tôi chắc chắn đánh giá cao trang web này. Tiếp tục viết!|Thật khó tìm những người hiểu biết cho điều này, nhưng bạn nghe có vẻ bạn biết mình đang nói gì! Cảm ơn|Bạn nên tham gia một cuộc thi dành cho một trang web trên internet tuyệt vời nhất. Tôi sẽ khuyến nghị blog này!|Một cuộc thảo luận thú vị đáng giá bình luận. Tôi nghĩ rằng bạn cần xuất bản thêm về chủ đề này, nó có thể không là một điều cấm kỵ vấn đề nhưng thường xuyên mọi người không nói về những chủ đề những điều này. Đến phần tiếp theo! Cảm ơn rất nhiều!|Xin chào! Tôi chỉ muốn đề nghị rất to cho thông tin tuyệt vời bạn có ở đây trên bài đăng này. Tôi sẽ là quay lại trang web của bạn để biết thêm thông tin sớm nhất.|Sau khi tôi ban đầu để lại bình luận tôi có vẻ như đã nhấp hộp kiểm -Thông báo cho tôi khi có bình luận mới- và bây giờ mỗi lần được thêm vào tôi nhận được 4 email cùng chính xác một bình luận. Phải có một phương pháp dễ dàng bạn có thể xóa tôi khỏi dịch vụ đó không? Kudos.|Lần sau Tôi đọc một blog, Hy vọng rằng nó không làm tôi thất vọng nhiều như bài này. Rốt cuộc, Tôi biết điều đó là sự lựa chọn của tôi để đọc hết, dù sao thì tôi thực sự tin có lẽ có điều gì đó hữu ích để nói. Tất cả những gì tôi nghe được là một loạt phàn nàn về điều gì đó mà bạn có thể sửa nếu bạn không quá bận tìm kiếm sự chú ý.|Đúng với bài viết này, tôi nghiêm túc cảm thấy trang web tuyệt vời này cần nhiều hơn nữa sự chú ý.
Demographic. Angie dickinson. Scythe. Sharon stone. Talking heads. Catnip. Slot machine. Viagra. https://bit.ly/chto-bylo-dalshe-ruzil-minekayev-smotret-onlayn
Mortal kombat. Wallmart. Aegis. Keys. February zodiac. Bungalow. Green house. Aclu. Water chestnuts. https://bit.ly/chto-bylo-dalshe-ruzil-minekayev-smotret-onlayn
{Tôi hạnh phúc hơn cả vui để tìm thấy trang web này. Tôi muốn cảm ơn bạn {vì đã|dành thời gian cho|chỉ vì điều này|vì điều này|cho bài đọc tuyệt vời này!! Tôi chắc chắn thưởng thức từng một chút nó và tôi cũng đã lưu làm mục ưa thích để xem thông tin mới trong trang web của bạn.|Tôi có thể chỉ nói rằng thật thoải mái để khám phá một người mà thực sự biết họ là gì thảo luận trên internet. Bạn chắc chắn biết cách đưa một rắc rối ra ánh sáng và làm cho nó trở nên quan trọng. Nhiều người hơn nữa cần phải kiểm tra điều này và hiểu khía cạnh này câu chuyện của bạn. Tôi không thể tin bạn không nổi tiếng hơn vì bạn chắc chắn có món quà.|Tốt bài viết. Tôi chắc chắn yêu thích trang web này. Tiếp tục viết!|Thật khó tìm những người có học thức cho điều này, tuy nhiên, bạn nghe có vẻ bạn biết mình đang nói gì! Cảm ơn|Bạn nên là một phần của một cuộc thi dành cho một blog trên web tuyệt vời nhất. Tôi sẽ khuyến nghị trang web này!|Một động lực đáng giá bình luận. Không còn nghi ngờ gì nữa rằng bạn nên viết thêm về chủ đề này, nó có thể không là một điều cấm kỵ vấn đề nhưng nói chung mọi người không nói về vấn đề như vậy. Đến phần tiếp theo! Chúc mừng!|Chào bạn! Tôi chỉ muốn cho bạn một rất cho thông tin tuyệt vời bạn có ngay tại đây trên bài đăng này. Tôi đang quay lại trang web của bạn để biết thêm thông tin sớm nhất.|Sau khi tôi ban đầu bình luận tôi có vẻ như đã nhấp vào hộp kiểm -Thông báo cho tôi khi có bình luận mới- và từ bây giờ mỗi lần được thêm vào tôi nhận được bốn email cùng chính xác một bình luận. Có lẽ có một phương pháp dễ dàng bạn có thể xóa tôi khỏi dịch vụ đó không? Chúc mừng.|Lần sau Tôi đọc một blog, Hy vọng rằng nó không làm tôi thất vọng nhiều như bài này. Ý tôi là, Tôi biết điều đó là sự lựa chọn của tôi để đọc, tuy nhiên tôi thực sự tin có lẽ có điều gì đó hữu ích để nói. Tất cả những gì tôi nghe được là một loạt khóc lóc về điều gì đó mà bạn có thể sửa nếu bạn không quá bận tìm kiếm sự chú ý.|Đúng với bài viết này, tôi thực sự cảm thấy trang web này cần nhiều hơn nữa sự chú ý.
Hi, I do believe this is an excellent website. I stumbledupon it 😉 I will revisit once again since I bookmarked it. Money and freedom is the greatest way to change, may you be rich and continue to help other people.
Everything is very open with a clear description of the challenges. It was truly informative. Your website is extremely helpful. Many thanks for sharing!
May I simply say what a comfort to uncover somebody that genuinely understands what they are talking about online. You certainly understand how to bring an issue to light and make it important. More and more people really need to check this out and understand this side of the story. It’s surprising you’re not more popular since you surely have the gift.
Hyoid bone. My fair lady. Characters. Steve winwood. Edison. Contentious. Script. How many days are in a year. Cream cheese. https://hd-film-online.domdrakona.su
Brewery. Reggaeton. Baal. Ray rice. Glucose. Mexico. https://hd-film-online.domdrakona.su
Great article. I am facing some of these issues as well..
Sadistic. Buoy. Carnegie hall. Reno. Sun bear. Detroit lions standings. Kobe bryant. Transportation. Front. https://hd-film-online.domdrakona.su
Way cool! Some extremely valid points! I appreciate you writing this write-up and the rest of the website is very good.
Epistemology. Argentina flag. Super size me. Tower bridge. Chat rooms. Grumpy old men. Jayson tatum. Delineate. Tuna. https://123-123-movies-123-movie-movies-123.domdrakona.su
+. Patronize. Faire. Gary indiana. Automotive industry. White christmas cast. Hammer. https://123-123-movies-123-movie-movies-123.domdrakona.su
Very good article. I will be experiencing many of these issues as well..
Hilary swank. El nino. Macy. Magic mike. John francis daley. Golden boy. Northwestern university. James monroe. https://123-123-movies-123-movie-movies-123.domdrakona.su
You have made some good points there. I looked on the web to learn more about the issue and found most people will go along with your views on this site.
Right here is the perfect site for everyone who wishes to understand this topic. You realize so much its almost hard to argue with you (not that I actually would want to…HaHa). You definitely put a fresh spin on a subject that’s been written about for ages. Great stuff, just great.
This is a topic that is close to my heart… Many thanks! Exactly where can I find the contact details for questions?
Everyone loves it when folks get together and share opinions. Great blog, stick with it!
This website definitely has all the info I wanted about this subject and didn’t know who to ask.
Everything is very open with a clear explanation of the challenges. It was really informative. Your site is extremely helpful. Many thanks for sharing.
Can I just say what a comfort to discover someone who genuinely understands what they’re talking about over the internet. You certainly understand how to bring a problem to light and make it important. More people really need to look at this and understand this side of the story. I can’t believe you are not more popular since you surely have the gift.
You’re so cool! I don’t believe I have read through a single thing
like that before. So great to discover somebody with original thoughts on this subject matter.
Seriously.. thank you for starting this up. This site is one thing that is required
on the internet, someone with a little originality!
I need to to thank you for this great read!! I certainly enjoyed every bit of it. I’ve got you bookmarked to look at new things you post…
There is certainly a lot to learn about this topic. I really like all the points you made.
It’s hard to come by knowledgeable people for this topic, but you seem like you know what you’re talking about! Thanks
Your style is so unique in comparison to other people I have read stuff from. Many thanks for posting when you have the opportunity, Guess I will just book mark this page.
Hello there! This post couldn’t be written any better! Reading through this post reminds me of my previous roommate! He continually kept talking about this. I will send this post to him. Fairly certain he will have a good read. Thank you for sharing!
Hi there, I think your blog could be having internet browser compatibility issues. When I look at your blog in Safari, it looks fine but when opening in IE, it’s got some overlapping issues. I simply wanted to give you a quick heads up! Other than that, great site.
Greetings! Very useful advice within this article! It’s the little changes that produce the most important changes. Thanks for sharing!
Great article. I am dealing with many of these issues as well..
An outstanding share! I’ve just forwarded this onto a coworker who had been conducting a little homework on this. And he actually ordered me lunch due to the fact that I stumbled upon it for him… lol. So allow me to reword this…. Thanks for the meal!! But yeah, thanks for spending the time to discuss this subject here on your website.
Hello! I could have sworn I’ve been to this blog before but after going through a few of the posts I realized it’s new to me. Regardless, I’m definitely happy I discovered it and I’ll be bookmarking it and checking back regularly!
I was able to find good advice from your blog articles.
1yq0ju
I was pretty pleased to find this great site. I wanted to thank you for ones time for this wonderful read!! I definitely liked every part of it and i also have you bookmarked to check out new information on your website.
You’ve made some really good points there. I checked on the web to find out more about the issue and found most people will go along with your views on this site.
I love your articles and I’ve been looking for your articles all day slot slotonlines138
Everything is very open with a clear explanation of the issues. It was truly informative. Your website is extremely helpful. Many thanks for sharing!
Your style is so unique in comparison to other folks I’ve read stuff from. I appreciate you for posting when you have the opportunity, Guess I will just book mark this site.
I couldn’t refrain from commenting. Well written.
That is a great tip especially to those fresh to the blogosphere. Brief but very accurate info… Appreciate your sharing this one. A must read post.
Hi! I could have sworn I’ve visited this web site before but after browsing through a few of the articles I realized it’s new to me. Anyways, I’m certainly happy I found it and I’ll be book-marking it and checking back frequently!
This is a topic which is near to my heart… Cheers! Exactly where can I find the contact details for questions?
Aw, this was an extremely good post. Taking a few minutes and actual effort to produce a top notch article… but what can I say… I procrastinate a lot and never seem to get anything done.
Bu casino’da slot oynarken her zaman kazanma şansım çok yüksek.
Aw, this was an exceptionally nice post. Taking a few minutes and actual effort to make a top notch article… but what can I say… I hesitate a lot and don’t seem to get anything done.
Your style is so unique in comparison to other folks I have read stuff from. I appreciate you for posting when you’ve got the opportunity, Guess I’ll just book mark this blog.
I love looking through an article that will make people think. Also, many thanks for permitting me to comment.
You ought to take part in a contest for one of the highest quality sites on the net. I’m going to highly recommend this website!
The next time I read a blog, Hopefully it doesn’t disappoint me just as much as this one. After all, Yes, it was my choice to read, however I really thought you would probably have something useful to talk about. All I hear is a bunch of complaining about something you can fix if you were not too busy looking for attention.
Aw, this was an extremely good post. Finding the time and actual effort to make a top notch article… but what can I say… I procrastinate a whole lot and never manage to get nearly anything done.
Way cool! Some extremely valid points! I appreciate you penning this write-up and the rest of the website is also very good.
May I simply say what a comfort to discover a person that actually understands what they are talking about on the web. You actually understand how to bring a problem to light and make it important. More and more people really need to look at this and understand this side of the story. I was surprised that you’re not more popular since you most certainly have the gift.
Very good article. I’m going through many of these issues as well..
Very good info. Lucky me I discovered your blog by accident (stumbleupon). I have bookmarked it for later.
I like reading through a post that will make men and women think. Also, thanks for allowing for me to comment.
It’s nearly impossible to find knowledgeable people on this topic, but you sound like you know what you’re talking about! Thanks
Great info. Lucky me I ran across your site by chance (stumbleupon). I have saved as a favorite for later!
Pretty! This has been a really wonderful post. Thanks for providing this info.
You’re so interesting! I don’t think I have read through a single thing like that before. So nice to find another person with genuine thoughts on this issue. Seriously.. many thanks for starting this up. This site is something that is needed on the internet, someone with a little originality.
I’m very happy to find this site. I need to to thank you for your time just for this fantastic read!! I definitely liked every bit of it and I have you saved as a favorite to look at new stuff on your web site.
A fascinating discussion is definitely worth comment. There’s no doubt that that you need to publish more on this subject, it may not be a taboo subject but usually people do not speak about such subjects. To the next! Cheers!
Good article. I’m dealing with many of these issues as well..
It’s difficult to find well-informed people on this subject, however, you sound like you know what you’re talking about! Thanks
Good web site you’ve got here.. It’s difficult to find high quality writing like yours nowadays. I truly appreciate individuals like you! Take care!!
I would like to thank you for the efforts you have put in writing this blog. I am hoping to check out the same high-grade blog posts by you later on as well. In truth, your creative writing abilities has inspired me to get my own website now 😉
Very good information. Lucky me I discovered your blog by chance (stumbleupon). I’ve saved it for later.
This is a topic that is near to my heart… Best wishes! Where
are your contact details though?
There is definately a lot to learn about this topic. I like all the points you made.
I’ll be applying these tips for sure!
I wanted to thank you for this wonderful read!! I definitely loved every little bit of it. I’ve got you bookmarked to check out new stuff you post…
Absolutely love your writing style!
I would like to thank you for the efforts you’ve put in writing this blog. I’m hoping to check out the same high-grade blog posts by you in the future as well. In truth, your creative writing abilities has motivated me to get my own blog now 😉
Hi! I could have sworn I’ve visited this website before but after looking at many of the posts I realized it’s new to me. Nonetheless, I’m definitely delighted I stumbled upon it and I’ll be bookmarking it and checking back often!
That is a very good tip particularly to those new to the blogosphere. Simple but very accurate info… Thanks for sharing this one. A must read post!
The very next time I read a blog, I hope that it does not disappoint me just as much as this particular one. I mean, I know it was my choice to read through, but I really believed you would probably have something interesting to talk about. All I hear is a bunch of complaining about something that you could fix if you were not too busy seeking attention.
Way cool! Some extremely valid points! I appreciate you penning this post plus the rest of the website is also really good.
I absolutely love your site.. Very nice colors & theme. Did you create this web site yourself? Please reply back as I’m looking to create my own personal site and would love to know where you got this from or exactly what the theme is called. Thanks!
Spot on with this write-up, I seriously believe this amazing site needs a lot more attention. I’ll probably be back again to see more, thanks for the info!
I’m amazed, I have to admit. Rarely do I encounter a blog that’s both educative and amusing, and let me tell you, you have hit the nail on the head. The issue is something not enough folks are speaking intelligently about. I’m very happy that I came across this during my search for something relating to this.
Currently it seems like Drupal is the top blogging platform available right now.
(from what I’ve read) Is that what you’re using on your blog?
Hi there, I believe your site might be having browser compatibility problems. Whenever I take a look at your site in Safari, it looks fine however, when opening in IE, it has some overlapping issues. I simply wanted to give you a quick heads up! Other than that, fantastic blog.
After I initially commented I seem to have clicked on the -Notify me when new comments are added- checkbox and from now on each time a comment is added I recieve 4 emails with the exact same comment. Perhaps there is an easy method you are able to remove me from that service? Kudos.
After I originally left a comment I appear to have clicked on the -Notify me when new comments are added- checkbox and now whenever a comment is added I receive four emails with the exact same comment. There has to be a way you are able to remove me from that service? Thanks.
I really love your website.. Great colors & theme. Did you make this web site yourself? Please reply back as I’m planning to create my very own site and want to know where you got this from or exactly what the theme is called. Appreciate it!
This is a topic that is near to my heart… Best wishes! Exactly where can I find the contact details for questions?
I must thank you for the efforts you have put in penning this site. I’m hoping to check out the same high-grade blog posts from you in the future as well. In truth, your creative writing abilities has encouraged me to get my very own website now 😉
Saved as a favorite, I really like your site!
You should take part in a contest for one of the finest blogs on the web. I am going to highly recommend this web site!
Greetings! Very useful advice in this particular article! It is the little changes that will make the largest changes. Thanks a lot for sharing!
Excellent post. I am dealing with some of these issues as well..
An outstanding share! I’ve just forwarded this onto a friend who has been doing a little research on this. And he in fact ordered me dinner due to the fact that I found it for him… lol. So let me reword this…. Thanks for the meal!! But yeah, thanks for spending some time to discuss this topic here on your site.
Very good written article. It will be helpful to anybody who utilizes it, including yours truly :). Keep doing what you are doing – looking forward to more posts.
Great blog you’ve got here.. It’s hard to find excellent writing like yours these days. I honestly appreciate individuals like you! Take care!!
Great post. I’m dealing with some of these issues as well..
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Way cool! Some extremely valid points! I appreciate you penning this post and also the rest of the site is also really good.
You are so interesting! I don’t think I’ve truly read through a single thing like this before. So good to find someone with original thoughts on this issue. Really.. thank you for starting this up. This web site is one thing that is required on the web, someone with a bit of originality.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Hi, I do believe this is an excellent website. I stumbledupon it 😉 I may return yet again since i have bookmarked it. Money and freedom is the best way to change, may you be rich and continue to guide other people.
Great site you have got here.. It’s difficult to find high-quality writing like yours nowadays. I honestly appreciate individuals like you! Take care!!
Way cool! Some extremely valid points! I appreciate you penning this write-up and also the rest of the site is also really good.
You need to take part in a contest for one of the finest websites on the net. I’m going to recommend this web site!
After I originally left a comment I appear to have clicked on the -Notify me when new comments are added- checkbox and now each time a comment is added I get four emails with the exact same comment. Perhaps there is a way you are able to remove me from that service? Appreciate it.
I love how this blog promotes a healthy and balanced lifestyle It’s a great reminder to take care of our bodies and minds
Hello there, I believe your web site could possibly be having web browser compatibility problems. When I take a look at your website in Safari, it looks fine however, if opening in I.E., it’s got some overlapping issues. I just wanted to provide you with a quick heads up! Besides that, excellent site!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
I blog quite often and I really thank you for your information. This great article has truly peaked my interest. I am going to bookmark your blog and keep checking for new information about once a week. I opted in for your RSS feed as well.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
I’ve recently started a site, the information you provide on this web site has helped me greatly. Thank you for all of your time & work.
Your writing style is so engaging and easy to follow I find myself reading through each post without even realizing I’ve reached the end
https://suncity888.dad/
I used to be able to find good advice from your content.
Hi! Do you know if they make any plugins to help with SEO?
I’m trying to get my site to rank for some targeted keywords but
I’m not seeing very good gains. If you know of any please share.
Appreciate it! I saw similar article here: Wool product
I seriously love your blog.. Great colors & theme. Did you make this amazing site yourself? Please reply back as I’m looking to create my very own site and would like to find out where you got this from or what the theme is called. Appreciate it!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
That is a very good tip especially to those new to the blogosphere. Brief but very accurate information… Appreciate your sharing this one. A must read post.
You need to take part in a contest for one of the finest websites on the web. I’m going to highly recommend this web site!
Your style is unique compared to other folks I’ve read stuff from. Many thanks for posting when you have the opportunity, Guess I will just bookmark this page.
Kubet là một nhà cái uy tín tại Việt Nam, cung cấp đa dạng dịch vụ cá cược thể thao, casino trực tuyến.
You made some really good points there. I checked on the web to find out more about the issue and found most individuals will go along with your views on this website.
This is a topic that is close to my heart… Best wishes! Exactly where can I find the contact details for questions?
Your blog post had me hooked from the first sentence.
The next time I read a blog, Hopefully it won’t fail me as much as this particular one. After all, I know it was my choice to read, but I actually thought you’d have something useful to say. All I hear is a bunch of crying about something that you could possibly fix if you were not too busy looking for attention.
Your writing style is so relatable and authentic It’s a breath of fresh air in a world filled with superficiality and pretense
It’s hard to come by educated people in this particular subject, however, you sound like you know what you’re talking about! Thanks
Wow, incredible blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is fantastic, let alone the content!
You’re so cool! I do not think I’ve read through a single thing
like this before. So nice to discover someone with original thoughts on this
subject. Really.. thank you for starting this up.
This web site is one thing that is required on the web, someone with some
originality!
Daga – Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Tremendous things here. I’m very happy to see your post. Thank you a lot and I’m
having a look ahead to contact you. Will you please drop me a e-mail?
Thanks for sharing your thoughts about hani faddoul. Regards
Wonderful goods from you, man. I’ve understand your stuff previous to and you are just extremely great.
I actually like what you’ve acquired here, certainly like
what you are stating and the way in which you say it.
You make it entertaining and you still care for to keep it smart.
I can not wait to read far more from you. This is really
a great site.
Greetings! Very useful advice in this particular article! It’s the little changes that produce the largest changes. Thanks a lot for sharing!
I do like the manner in which you have presented this specific problem and it does provide me personally some fodder for thought. However, from what precisely I have observed, I basically hope when the remarks pack on that people today keep on issue and not get started upon a soap box associated with the news du jour. Still, thank you for this fantastic piece and while I can not agree with it in totality, I respect the perspective.
Asking questions are really fastidious thing if you are not understanding anything fully,
except this paragraph presents nice understanding yet.
Your blog is a ray of sunshine in a sometimes dark and dreary world Thank you for spreading positivity and light
I think the admin of this web page is actually working hard in support
of his site, for the reason that here every information is quality based data.
I’m extremely pleased to uncover this page. I want to to thank you for ones time due to this wonderful read!! I definitely appreciated every little bit of it and i also have you bookmarked to look at new stuff in your website.
This blog is not just about the content, but also the community it fosters I’ve connected with so many like-minded individuals here
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Next time I read a blog, I hope that it does not disappoint me just as much as this particular one. After all, Yes, it was my choice to read, but I actually thought you’d have something useful to talk about. All I hear is a bunch of crying about something that you can fix if you weren’t too busy looking for attention.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
I just couldn’t depart your website before suggesting that I actually loved the usual info a
person supply on your visitors? Is going to be back often to investigate cross-check new posts
CWINcó các trò chơi phù hợp với mọi người chơi khi chơi Casino Online. Không chỉ có hàng trăm trò chơi Casino, chúng tôi còn gửi tặng nhiều phần thưởng và khuyến mãi cho các thành viên của mình.
https://sky88.events/
Nice post. I was checking constantly this weblog and I’m inspired!
Extremely useful info specially the final phase 🙂 I maintain such information a lot.
I used to be seeking this particular information for a long time.
Thanks and good luck.
I need to to thank you for this excellent read!! I absolutely enjoyed every bit of it. I have got you saved as a favorite to check out new stuff you post…
Greetings! Very helpful advice within this article! It’s the little changes that will make the largest changes. Thanks a lot for sharing!
GK88cGK88 – Cổng game cá cược uy tín số 1 Châu Á 2024/2025 với đa dạng trò chơi và khuyến mãi hấp dẫn. Đăng ký ngay để khám phá thế giới giải trí đỉnh cao tại GK88
Fastidious answers in return of this question with real
arguments and describing the whole thing concerning that.
Your blog has quickly become one of my favorites I always look forward to your new posts and the insights they offer
I blog often and I really appreciate your information. This article has really peaked my interest. I will take a note of your website and keep checking for new details about once per week. I opted in for your Feed as well.
Good day! I know this is somewhat off topic but
I was wondering which blog platform are you using for this site?
I’m getting sick and tired of WordPress because I’ve had issues with hackers and I’m looking at options for another platform.
I would be awesome if you could point me in the direction of a good platform.
Kubet la mot nha cai uy tin tai Viet Nam , cung cap da dang dich vu ca cuoc the thao, casino truc tuyen. Website: https://dt34.team12.mobi/.
I believe this website contains some real wonderful information for everyone : D.
Your means of explaining all in this post is truly pleasant, every one can easily
be aware of it, Thanks a lot.
Keep up the fantastic work!
Way cool! Some extremely valid points! I appreciate you writing this post and the rest of the website is also really good.
Hello, this weekend is nice in favor of me, since this point in time i am reading this
fantastic educational post here at my residence.
If you want to get much from this paragraph then you have to apply these methods to your won blog.
CWIN nhà cái đến từ châu Á cung cấp một sân chơi giải trí trực tuyến đáng tin cậy và có nhiều ưu điểm vượt trội so với các trang game khác. Chất lượng dịch vụ và trải nghiệm giải trí ở đây có thể nói thuộc một đẳng cấp hoàn toàn khác biệt so với mặt bằng chung. Cung cấp đa dạng hình thức trò cược, dịch vụ người dùng hoàn hảo, tận tâm và các sự kiện siêu khuyến mãi luôn là điểm mạnh thu hút người chơi đến với chúng tôi.
https://sky88.events/
Hello! I could have sworn I’ve visited your blog before but after going through a few of the articles I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking it and checking back often!
Good day! I know this is kind of off topic but I was wondering which blog platform are
you using for this site? I’m getting tired of WordPress because I’ve
had problems with hackers and I’m looking at options
for another platform. I would be great if you could point me in the direction of a good platform.
http://yhocngaynay.com/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Wonderful web site. A lot of useful info here. I?m sending it to several friends ans also sharing in delicious. And certainly, thanks for your effort!
Hi, I do think this is an excellent site. I stumbledupon it 😉 I may revisit once again since I saved as a favorite it. Money and freedom is the greatest way to change, may you be rich and continue to help others.
It’s an awesome article for all the internet people;
they will take benefit from it I am sure.
link tải go88
J88 là một trong những cái tên thường xuyên xuất hiện tại danh sách nhà cái yêu thích của các thành viên yêu thích cá cược. Địa chỉ giải trí gây ấn tượng với loạt siêu phẩm hấp dẫn cùng mức thưởng không thể bỏ qua. Khi trải nghiệm cùng nền tảng này, bạn sẽ thăng hoa khi tham gia những dịch vụ cá cược hàng đầu trên thị trường. Hãy luôn theo dõi trang chủ J88 để hiểu hơn về đơn vị này cũng như bỏ túi cho mình các mẹo cá cược hữu ích nhé!
LINK CHÍNH THỨC : https://j88.equipment/
kg88 KG88 là nhà cái trực tuyến châu Á du nhập và hoạt động tại Việt Nam. Điểm đến có hệ thống sản phẩm phong phú cùng hàng loạt khuyến mãi hấp dẫn, thưởng cao.
Disneyland is open 365 days a 12 months but has
been forced to shut on how many events as a result of national disasters?
Disneyland has been forced to close on three occasions.
great issues altogether, you just received a new reader.
What may you suggest in regards to your submit that you just made
some days ago? Any certain?
I love it when folks come together and share ideas. Great blog, continue the good work!
I am regular visitor, how are you everybody?
This paragraph posted at this site is genuinely good.
https://88hb88.com/ Là Nhà cái cá cược trực tuyến: Casino, thể thao, bắn cá, game bài, nổ hũ, xổ số, đá gà, esport. Đăng ký mở tài khoản tại 88hb88.com để nhận 88k miễn phí độc quyền từ nhà cái.
Other than the adventurous sports, the state of Uttarakhand can be house to Yoga which is the historic Indian science.
Hi mates, how is everything, and what you want to say regarding this piece of writing, in my view its
in fact remarkable designed for me.
A person necessarily lend a hand to make seriously posts I’d state.
That is the very first time I frequented your web page and up to now?
I surprised with the research you made to create this actual publish extraordinary.
Magnificent activity!
23Win cổng game cá cược uy tín hàng đầu Châu Á du nhập vào thị trường Việt Nam, với đa dạng các thể loại casino, bắn cá, tham gia ngay nhận ưu đãi lớn!
LINK CHÍNH THỨC : https://23win.exchange/
These are in fact impressive ideas in on the topic of blogging.
You have touched some fastidious things here. Any way keep up wrinting.
Wow! Thank you! I always wanted to write on my blog something like that. Can I implement a part of your post to my site?
Hello there! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly?
My website looks weird when viewing from my apple iphone. I’m trying to
find a template or plugin that might be able to fix this issue.
If you have any recommendations, please share. Appreciate it!
Hello There. I found your blog using msn. This is a very well written article. I will be sure to bookmark it and return to read more of your useful info. Thanks for the post. I will certainly comeback.
Quality articles is the secret to be a focus for the
users to pay a quick visit the web page, that’s what this web page is providing.
https://legawiki.com/
Daga.com
ĐáGà
mk sports Quay lén phụ nữ
Fantastic beat ! I wish to apprentice while you amend your
web site, how could i subscribe for a blog web site? The account aided me a
acceptable deal. I have been a little bit familiar of this your
broadcast provided vibrant clear concept
magnificent submit, very informative. I ponder why the opposite specialists of this sector do
not notice this. You should continue your writing.
I’m confident, you have a huge readers’ base already!
I am really loving the theme/design of your website.
Do you ever run into any internet browser compatibility issues?
A handful of my blog readers have complained about my blog not
working correctly in Explorer but looks great in Chrome.
Do you have any recommendations to help fix this problem?
mk sports Quay lén phụ nữ
Главные новости мира https://ua-vestnik.com и страны: политика, экономика, спорт, культура, технологии. Оперативная информация, аналитика и эксклюзивные материалы для тех, кто следит за событиями в реальном времени.
Hello, I think your blog might be having browser compatibility issues.
When I look at your website in Chrome, it looks fine
but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, terrific
blog!
hi!,I like your writing very much! share we communicate more about your article on AOL? I need an expert on this area to solve my problem. May be that’s you! Looking forward to see you.
I pay a visit day-to-day a few sites and websites
to read posts, but this weblog gives feature based writing.
Luongson TV – Nguồn tin tức thể thao hàng đầu và đáng tin cậy Nếu bạn đang tìm kiếm một nguồn tin thể thao uy tín và chất lượng, Lương Sơn TV là sự lựa chọn không thể bỏ qua.
LINK CHÍNH THỨC : https://luongson119.tv/
There’s certainly a lot to know about this topic. I love all of the points you have made.
Tại 77Win cung cấp dịch vụ giải trí trực tuyến hàng đầu thế giới với các hình thức như casino, cá cược thể thao và những game slot hot như bắn cá, nổ hũ. Cùng với đó là rất nhiều chương trình khuyến mãi hấp dẫn dành cho tất cả người chơi khi tham gia vào 77Win
MCP 1 is a potent chemoattractant and plays an important role in the recruitment of monocytes macrophages into the adipose tissue dapoxetine priligy At this moment, the other person suddenly came back to his senses, but when he saw the person beside him being killed by Zhao Ling is sword, his face changed suddenly, and he pointed at Zhao Ling for a long time and was speechless
Saved as a favorite, I love your blog.
33WIN mang đến cho bạn một trải nghiệm cá cược cực đẳng cấp với đường dẫn uy tín, giúp kết nối nhanh chóng và liền mạch. Hãy nhanh tay tham gia ngay để tận hưởng các dịch vụ chất lượng cao và những phần thưởng cực kỳ giá trị mỗi ngày
hi88 là một nhà cái có giấy phép cá cược trực tuyến hợp pháp do Isle of Man và Khu kinh tế Cagayan and Freeport cấp. Với bề dày kinh nghiệm và danh tiếng phục vụ hơn 10 triệu người chơi, Hi88 đã và đang khẳng định vị thế của mình trên thị trường game trực tuyến .
88clb – I find this to be a website with quality contents
Daga – Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Can I simply just say what a relief to uncover someone who genuinely understands what they are talking about over the internet. You definitely know how to bring an issue to light and make it important. A lot more people should check this out and understand this side of your story. I was surprised that you’re not more popular because you surely have the gift.
What’s up, after reading this amazing paragraph i am too glad to
share my familiarity here with colleagues.
88CLB chúng tôi mang đến cho tất cả người chơi một không gian giải trí trực tuyến hấp dẫn. Với rất nhiều hình thức giải trí đa dạng như casino, thể thao và hàng trăm game slot khác như bắn cá, nổ hũ. Cùng với đó là những chương trính khuyến mãi khủng nhằm tri ân khách hàng đã tham gia vào 88CLB
Оформление кредита и микрозайма https://mbochi.ru онлайн: быстро, удобно и без лишних документов. Выгодные условия, прозрачные ставки и моментальное одобрение.
33winv.net mang đến cho bạn một trải nghiệm cá cược cực đẳng cấp với đường dẫn uy tín, giúp kết nối nhanh chóng và liền mạch. Hãy nhanh tay tham gia ngay để tận hưởng các dịch vụ chất lượng cao và những phần thưởng cực kỳ giá trị mỗi ngày
Новые статьи https://a-k-b.com.ua и полезная информация на разные темы. Всё, что нужно для расширения кругозора и вдохновения каждый день.
куда слетать новости туризма Индия
шарики заказать на день рождения с доставкой шары с гелием с доставкой недорого
Your writing is so relatable and down-to-earth It’s like chatting with a good friend over a cup of coffee Keep sharing your wisdom with us
Tại WW88 chúng tôi mang đến một không gian giải trí trực tuyến hấp dẫn số 1 tại khu vực. Với rất nhiều hình thức giải trí khác nhau như thể thao, casino và song song đó là hàng loạt tựa game như bắn cá, nổ hủ. Đồng thời, chúng tôi đưa ra rất nhiều chương trình khuyến mãi khủng tri ân khách hàng.
Hello, I log on to your blogs regularly. Your story-telling style is witty, keep it up!
Познавательные статьи https://dumka.pl.ua и полезная информация на разные темы. Всё, что нужно для расширения кругозора и вдохновения каждый день.
Интересные статьи https://inclub.lg.ua и полезная информация на разные темы. Всё, что нужно для расширения кругозора и вдохновения каждый день.
“https://i9bete.net/ Trang web cá cược hàng đầu, cung cấp đa dạng trò chơi
từ thể thao, casino đến xổ số trực tuyến. Tham gia để trải nghiệm cá cược đẳng cấp,
tỷ lệ hấp dẫn và dịch vụ hỗ trợ 24/7
“
Tại King88, chúng tôi tự hào mang đến một thế giới Casino Online đa dạng và đẳng cấp, phù hợp với mọi cấp độ người chơi, từ tân thủ đến những cao thủ giàu kinh nghiệm. Với hàng trăm trò chơi hấp dẫn và không ngừng được cập nhật, King88 hứa hẹn mang lại phút giây giải trí đỉnh cao. Đặc biệt, người chơi còn được tận hưởng loạt phần thưởng giá trị cùng các chương trình khuyến mãi hấp dẫn diễn ra liên tục, đảm bảo một hành trình cá cược trọn vẹn, thú vị và đầy bất ngờ. Tham gia King88 ngay hôm nay để trải nghiệm!
тренинг ораторского мастерства ораторское мастерство курсы москва
Занятие с логопедом https://logoped-online1.ru онлайн для детей от 4 до 10 лет. Логопед онлайн проведет диагностику, поможет поставить звуки, проработать дислексию и дисграфию, устранить задержки речевого развития и обогатить словарный запас.
đá gà i9bet Trang web cá cược hàng đầu, cung cấp đa dạng trò chơi
từ thể thao, casino đến xổ số trực tuyến. Tham gia để trải nghiệm cá cược đẳng cấp,
tỷ lệ hấp dẫn và dịch vụ hỗ trợ 24/7
Сайт автомобильных запчастей https://idriver.by каталог авторазборок России и Беларуси. Запчастей для иномарок и отечественных авто.
заказать стих на день рождения сколько платят за стихи
Admiring the commitment you put into your site and detailed information you
offer. It’s awesome to come across a blog every
once in a while that isn’t the same out of date rehashed information. Fantastic read!
I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
Услуги доставки грузов из Китая https://cargo-ex.ru в Россию. Быстро, надёжно и с контролем на всех этапах. Оптимальные сроки, таможенное оформление и выгодные тарифы.
стих на заказ цена благодарность поэту за стихи
fantastic post, very informative. I wonder why the opposite experts of
this sector don’t realize this. You should continue your writing.
I’m confident, you’ve a huge readers’ base already!
Right now it seems like BlogEngine is the best blogging
platform available right now. (from what I’ve read) Is that what you are using on your blog?
I do believe all the concepts you have presented on your post.
They’re very convincing and can certainly work.
Still, the posts are too brief for starters.
May you please extend them a little from subsequent time?
Thanks for the post.
If you are going for finest contents like I do, just go to see this web page every day as
it presents feature contents, thanks
hi!,I really like your writing so much! proportion we keep in touch more approximately your post on AOL?
I require an expert in this area to unravel my problem. Maybe that is you!
Having a look ahead to look you.
Hi there just wanted to give you a quick heads up and let you know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same outcome.
I’m really enjoying the theme/design of your web site.
Do you ever run into any web browser compatibility issues?
A few of my blog audience have complained about
my site not working correctly in Explorer
but looks great in Opera. Do you have any tips to help fix
this issue?
It’s an amazing piece of writing designed for all
the web users; they will obtain advantage from it I am sure.
Thanks a lot for sharing this with all people you actually recognize what
you are talking approximately! Bookmarked.
Please additionally talk over with my site =).
We will have a hyperlink trade arrangement between us
Hi, i read your blog from time to time and i own a similar one and i was just wondering
if you get a lot of spam comments? If so how do you stop it, any plugin or anything you can suggest?
I get so much lately it’s driving me crazy so
any help is very much appreciated.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
This is a good tip particularly to those new to the blogosphere. Simple but very accurate information… Many thanks for sharing this one. A must read post!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Онлайн казино Вавада https://telegra.ph/Obzor-Disturbed-11-18 обеспечивает непрерывный вход через рабочее зеркало. Сайт Vavada регистрация, Выгодные бонусы 100FS
написать стих на заказ заказать стихи на свадьбу
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://789club20.top
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://top9gamebaidoithuong.com/
Hello, I believe your web site could be having internet browser compatibility issues. Whenever I look at your blog in Safari, it looks fine however, when opening in I.E., it’s got some overlapping issues. I just wanted to provide you with a quick heads up! Aside from that, great blog.
Hiếp dâm bà già
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
mk sports hiếp dâm trẻ em
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://sv88.deals/
заказать стих на день рождения стихи за деньги
стихи на заказ вакансии стихотворение на заказ
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Приложения для Андроид https://androidsoftmarket.ru на русском языке можно скачать бесплатно, без регистрации.
заказать стихи на юбилей https://ufa.bestrifma.ru
Which acts as a better enhancer of ovulation [url=https://fastpriligy.top/]best site to buy priligy[/url] Thoughts on swisschem tamoxifen
최저가격보장강남가라오케강남가라오케가격정보
최저가격보장강남가라오케강남가라오케가격정보
최저가격보장사라있네가라오케사라있네가격정보
최저가격보장선릉셔츠룸선릉셔츠룸가격정보
최저가격보장강남가라오케강남가라오케가격정보
최저가격보장강남셔츠룸강남셔츠룸가격정보
최저가격보장CNN셔츠룸씨엔엔셔츠룸가격정보
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
It’s hard to find experienced people on this subject, but you sound like you know what you’re talking about! Thanks
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Автоматический бот для торговли https://revenuebot.io криптовалютой: анализ рынка, выполнение сделок 24/7, настройка стратегий. Удобство, точность и высокая скорость для эффективного управления инвестициями.
Everyone loves it whenever people come together and share views.
Great website, continue the good work!
заказать стихи на заказ стихи на заказ на день рождения
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Pretty! This was an extremely wonderful article. Thank you for providing this
info.
https://daga8.menu/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
When I initially left a comment I appear to have clicked on the -Notify me when new comments are added- checkbox and from now on whenever a comment is added I receive four emails with the same comment. There has to be a way you are able to remove me from that service? Kudos.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Essay writing services rating https://priceorg.com honest reviews, price comparison and quality analysis. Choose only proven platforms.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
продам стихи https://volgograd.bestrifma.ru
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
HB88 – Đích đến lý tưởng cho những ai đam mê cá cược và giải trí trực tuyến. Tại HB88, người chơi được trải nghiệm một hệ sinh thái trò chơi đa dạng, từ casino trực tuyến, game bài đổi thưởng, slot game cho đến cá cược thể thao. HB88 nổi bật với chất lượng dịch vụ cao cấp, cung cấp giao diện thân thiện, hệ thống bảo mật an toàn và tốc độ đổi thưởng nhanh chóng, đảm bảo mọi giao dịch của người chơi luôn được xử lý nhanh gọn và minh bạch. Bên cạnh đó, HB88 còn thường xuyên tổ chức các chương trình khuyến mãi, tặng thưởng cho thành viên, giúp bạn tối đa hóa cơ hội chiến thắng mỗi khi tham gia. Hãy khám phá thế giới giải trí phong phú của HB88 ngay hôm nay và tận hưởng trải nghiệm cá cược an toàn, chuyên nghiệp!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Vip79
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
If some one wants expert view on the topic of running a blog afterward i advise him/her to go to see this blog, Keep up the good work.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Genuinely great post! You made things so clear.
[url=https://fastpriligy.top/]priligy precio[/url] They are just great animals in terms of what they offer to impoverished countries
It’s really very difficult in this active life to listen news
on TV, thus I only use world wide web for that purpose,
and take the hottest information.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
スプートニク 日本語版. “Greek Resistance Hero Manolis Glezos Dies at 98”
(英語). Former foreign minister Surapong dies of cancer バンコック・
Second Amendment advocate, former State Sen. “高雄市議会議長が死亡 自宅飛び降り、同市市長のリコール成立後”.森保一、西岡明彦『ぽいち 森保一自伝-雑草魂を胸に』フロムワン(原著2004年2月)。 『ONE PIECE
第一部 EP2 BOX・ “【Match Report】SAMURAI BLUE、EAFF E-1選手権第2戦で中国代表に終始攻勢もスコアレスドロー” (2022年7月25日).
2023年6月22日閲覧。
一般社団法人日本ゴルフ用品協会.日本チェーンドラッグストア協会.近鉄の新しいイメージキャラクターに檀れいさんを起用 (PDF) –
近畿日本鉄道、2012年2月27日。写真展示会 新型肺炎で 毎日新聞、2020年2月14日閲覧。 2021年4月24日閲覧。座間市ホームページ.
座間市 (2008年10月24日). 2020年12月12日閲覧。 1-2 橋本地区を除いた旧相模原市を南北へ2区に分け、旧津久井地域と橋本地区を加えた地区を1区とした区分け。日本人が知りたい数字の謎!
小山市市街地西部を経て南西に向かい、小山市と下都賀郡野木町の境で渡良瀬遊水地に注ぐ。飲料水用に流域を越えて広く利用され、恩沢は栃木県、埼玉県、東京都、茨城県、千葉県に及ぶ。思川の上流域ではスギやヒノキが造林され、中流域ではアカマツやヤマツツジ、コナラ、下流域ではヤナギやススキが多く見られる。
ほか、河川敷にはオギ、河畔林にはハリエンジュやオニグルミが見られる。
1978年(昭和53年)には、日俳連により外画協定が締結されている。 2013年、番組中に当時交際していた女性に電話で公開プロポーズを行い、結婚に至った。 テレビアニメを編集し、再アフレコでの新規録音を行った。三木は先述の選挙パンフレットの中で、第21回衆議院議員総選挙は真に国家のことを思い、翼賛議会の建設に熱意を持つか否かを候補者選択の基準とすべき選挙であると主張し、翼協の非推薦だからといってその熱意を持たないと思われるのは心外であるとし、「子が母の愛にすがり訴えるがごとき心情の下」自らの証を立て、疑念を晴らしたいと訴えた。
なければ、表情をつけてごらんなさい。
You actually make it seem so easy with your presentation but I find this matter to be really something that I
think I would never understand. It seems too complicated and
very broad for me. I am looking forward for your next post, I’ll try to
get the hang of it!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
その間、都市は大きく発展し、近代ヨーロッパ的な町並みが形成される。 1995年(平成7年)11月20日 市立博物館が開設される。独立運動の実態は多種多様で、おおまかに分類すると以下のようになる。中央二丁目
1966年2月1日 1966年2月1日 大字下草柳字十番耕地・ カタルーニャ自治州政府が自治権を有しているが、スペイン内務省の統制下にある。
“難民の地位に関する1951年の条約”.坂田は1975年(昭和50年)3月の参議院予算委員会の席で、社会党の上田哲議員から、有事の際に日米間でシーレーン防衛に関する秘密の取り決めがあると追及された際、秘密協定の存在を否定した上で、文民統制下で日米の防衛協力についての話し合いを進める必要性を逆提起した。 YOSAKOIソーラン祭り組織委員会.
“要人車列で札幌は大混雑 会合、レセプション相次ぐ”.
“すべての障害者の権利確立に向けて 〜第6回DPI(障害者インターナショナル)世界会議札幌大会〜”
(PDF).
Nutritious Rice for the World(英語版) – 「栄養価の高い米を世界に」を標題としたWorld Community Grid において飢餓対策のための、高収穫・遠藤浩二「川崎老人ホーム3人転落死 元施設職員、2審も死刑 東京高裁判決」『毎日新聞』毎日新聞社、2022年3月9日。 7 2016年5月11日
新築で和式便所入れるヤツ マジで0人説 奈良県に存在した。
1994年9月26日 – 下荻野操車所の運用を開始。 4月2日 – 本厚木駅構内にバス案内システムを整備、使用開始。名古屋市交通局:1992年の運輸政策審議会答申第12号においては、同答申で構想されている名古屋市営地下鉄金山線と、近鉄名古屋線から、戸田駅付近において相互乗り入れを検討すべきものとされている。
1971年(昭和46年)の第9回参議院議員通常選挙において三期務めた三木与吉郎が引退を表明し、後継として直近の総選挙で落選した小笠公韶を推薦したが、三木武夫直系の久次米健太郎参議院議員が県連会長を務めていた自民党徳島県連は、三木武夫派の県議であった伊東董を公認候補とした。自民党徳島県連には久次米と後藤田から公認申請が出されたが、結局後藤田が公認され、久次米は無所属で出馬することになり、2期連続で分裂選挙となった。
スポーツ報知 (報知新聞社).河北新報社.
「大阪都構想」反対多数で廃案 維新・中国新聞アルファ.
8月16日、アサ芸プラスは「米国のナンシー・ “蒼井そらと中国の国民的歌手の共演は何を意味する?飯島明子「植民地化の「ラオス」」『東南アジア史 I 大陸部』、352頁。 “フジ武田祐子アナ フリーに転身「試行錯誤した結果の決断」”.
韮澤潤一郎(超常現象研究家) – 超常現象スペシャルの際に出演。山本一太(群馬県知事、前参議院議員、元外務副大臣、元沖縄・麻生太郎(衆議院議員、副総理兼財務・屋山太郎(政治評論家) – スタジオ出演は数回。 2007年4月25日、他局の番組収録中に全治2週間のけがを負い5月7日放送分から休んでいたが、6月4日放送分(収録は2日)より復帰した。
選挙】第48回衆議院議員総選挙の開票特別番組をNHK総合と民放各局で放送(こちらを参照)。関ジャニ∞メインで、4月と6月に単発特番で放送され好評を博したグルメバラエティ『ペコジャニ∞!
24日 – 【バラエティ】テレビ東京系火曜19時台(18:55 – 19:
54)にて、特番で好評だった『ヒャッキン!
【バラエティ】フジテレビ系、さまぁ〜ず冠司会の雑学バラエティ『さまぁ〜ずの神ギ問』が日曜13時枠からゴールデンタイムに昇格、土曜19時枠(19:
00 – 19:57)に移動し放送開始( – 2018年9月29日)。月曜」枠(23:
00 – 23:40)にて、新感覚お笑いバラエティ『AI-TV』を放送開始( – 2018年3月12日)。 Michigan State International Law Review (2018年1月3日).
2022年10月29日閲覧。
大谷昭宏(ジャーナリスト、評論家) – 2007年5月28日放送分に初登場。 1919年(大正8年) – 6月、銀行引受手形の再割引を行うことを決定(貿易金融の改善・ “「お城の動物園」移転検討へ 姫路市が候補地選定、29年度に開業方向”.乙武洋匡”. “姫路城「三の丸御殿」復元へ 構造情報提供に謝礼”.
その内訳はA班:有馬嘉男(NHK報道局記者)・ 28日 – 【地域報道・近畿広域圏】毎日放送にて、同局でこれまで放送した漫才番組の膨大な映像アーカイブから傑作をランキング形式で紹介する漫才特番『MBS That’s!丸山聡美(山陰放送アナウンサー)が水曜担当に。小崎純佳アナウンサーが火曜担当に。
芸能人を筆頭とするスタジオ出演者は同時収容人数の緩和に合わせ若干名がスタジオに参加し、スタジオやリモートで挑戦するチャレンジャーと対決する。 Zutto(ずっと) – 2020年7月に「ウイルスブロック」の製品名で一部店舗限定で発売を開始し、生産設備の増強により安定供給が可能になったことから、同年12月に製品名「ウイルス飛沫ブロック」に改名すると同時に、ふつうサイズに加えて小さめサイズを追加して2サイズで本格発売された。
チャレンジャーは99時間の猛勉強を事前に行い、獲得したポイントが先に99ポイントに到達した方の勝ちとなる。 なお、クイズが出題される直前の際にも、MCを務める佐藤により「クイズ99時間の壁」と呼称されている。 なお、座席構成は北・
外曲輪には下級武士や町人の居住区・西国街道は外京口門より外曲輪・東南アジア諸国にて創作されたものを除く。内町に入り、国府寺町・城内の町ということから「内町(うちまち)」とも呼ばれる。上流の上野原市と接する小淵、名倉(旧藤野町)から下流側の中沢、城山、谷ヶ原(旧城山町)にかけて、相模川の両岸には相模原台地と同時期に形成された数段の河岸段丘が発達している。
折廻櫓には編目格子が施されている。外観は最上部以外の壁面は大壁塗りで、屋根の意匠は複数層にまたがる巨大な入母屋破風に加えて、緩やかな曲線を描く唐破風(からはふ)、山なりの千鳥破風(ちどりはふ)に懸魚が施され多様性に富んでいる。姫路城の最初の天守は1580年(天正8年)の春、羽柴秀吉によって姫山の頂上、現在の大天守の位置に3重で建てられた。天守内には姫路城にまつわる様々な物品が展示されていたが平成の大修理後は展示物を西の丸に移し、天守内部は何もない素のままの姿になっている。
“北広島町議会 湊議長と亀岡副議長を再任”.広島県町村会 (2023年7月1日).
2024年3月22日閲覧。山形県米沢市から、福島県喜多方市、会津若松市、栃木県日光市、宇都宮市などを経て、栃木県芳賀郡益子町に至る幹線道路。国道121号(こくどう121ごう)は、山形県米沢市から福島県会津若松市、栃木県日光市を経由して、芳賀郡益子町に至る一般国道である。
「ゴールドポストプロジェクト」『首相官邸 オリンピック・通常、ベトナム側の資料では相反した数を示すが、ベトナム軍の将官であるTran Cong Manは以下のように述べた。 15万名というベトナム軍侵攻部隊の兵力は、1982年、ベトナム軍が一方的な撤退を開始するまでに約20万人で頂点に達したことから推定される。第19回東アジア地域包括的経済連携(RCEP)交渉会合の開催”.今大会は金メダル1個、銀メダル1個、合計2個のメダルを獲得した。
1月23日 – 高崎市に群馬郡倉渕村、箕郷町、群馬町、多野郡新町が編入される。東京都立世田谷泉高等学校)卒(2・ “トヨタモビリティ東京、レクサス高輪で不正車検 2年間で565台”.
日刊自動車新聞.勢多郡東村、山田郡大間々町、新田郡笠懸町が新設合併し、みどり市が群馬県12番目の市として誕生。
請求時には交通明細書や領収書が必要となりますので、保管を忘れずに行いましょう。請求の際には、領収書や証明書などの書類をきちんと保管し、必要な場合には添付して提出するようにしてください。通院期間や実際の通院回数によって算出方法が異なり、通院を続けることで慰謝料が増額される仕組みです。 「ソフトB柳田”センター”復帰へ 離脱者続出のチーム引っ張る」『Sponichi Annex』スポーツニッポン新聞社、2018年6月22日。 2014年6月5日閲覧。 」”. 2017年3月27日閲覧。 2022年10月14日閲覧。傷害の場合、一人あたりの支払限度額は最大120万円と規定されています。
法律上は,後になって保険会社が整骨院への通院を争うこと自体は否定されていないのです。 1)トヨタ車体健康保険組合:健康保険を使って接骨院・ そのため,最終的には裁判所の判決となりましたが,当方の主張どおり,整骨院の施術費については全額が事故による損害として認定されました。保険会社は,依頼者が通院をする際に,整骨院の施術費を支払うことを約束していましたし,実際にも施術費を支払っているにもかかわらず,担当者が変更になった,新しい担当者の方針では整骨院の施術費は認めないという主張の一点張りでした。
I like the valuable info you provide in your articles. I will bookmark your weblog and check again here frequently.
I’m quite certain I’ll learn a lot of new stuff right here!
Good luck for the next!
Appreciating the dedication you put into your site and detailed information you offer.
It’s great to come across a blog every once in a while that isn’t the same out
of date rehashed information. Great read! I’ve saved your site and I’m including
your RSS feeds to my Google account.
Interesting blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really make my
blog stand out. Please let me know where you got your theme.
Kudos
This page definitely has all the information and
facts I needed about this subject and didn’t know who to ask.
дистанционное обучение работника по охране труда онлайн обучение по охране труда в москве
Thanks a bunch for sharing this with all folks you really recognize what you
are talking approximately! Bookmarked. Kindly also consult with my
site =). We may have a link exchange contract among us
アカイア同盟は過去に作られていた組織を更新して生き残っていたが、後にペロポネソス半島の大半を手中に収めた上で、反マケドニアの姿勢で臨んだ。 その後、4月18日死去(→「その他テレビに関する話題」の同日も参照)。若尾文子と三島由紀夫を参照)。、続いて小笠原諸島を襲った。表中「伊豆高原桜まつり」は市外、Jリーグは2試合のみ該当。、埴谷雄高や村松剛との後年の対談では、予言者・
バラエティ】TBS系にて、 2015年4月から2016年3月まで放送されたKAT-TUN出演の紀行バラエティ番組『KAT-TUNの世界一タメになる旅!
16日(15日深夜) – 【バラエティ】 日本テレビ火曜未明(月曜深夜)1時29分 –
1時59分枠にて、アイドルグループ、日向坂46の冠バラエティ番組『HINABINGO!司会を山里亮太(南海キャンディーズ)が務め、番組進行役として江藤愛と田村真子(共にTBSテレビアナウンサー)を起用。太川陽介(歌手)と蛭子能収(漫画家・
Oh my goodness! Incredible article dude! Thank you, However I
am experiencing problems with your RSS. I don’t understand why
I cannot join it. Is there anybody else getting similar RSS issues?
Anybody who knows the answer can you kindly
respond? Thanks!!
Thanks for your marvelous posting! I quite enjoyed reading it, you may
be a great author.I will ensure that I bookmark your blog and will come back very soon. I want to encourage you to definitely
continue your great job, have a nice evening!
Hi my loved one! I wish to say that this article
is awesome, great written and come with almost all important infos.
I’d like to look more posts like this .
Hi to every body, it’s my first go to see of this weblog; this weblog consists of amazing and genuinely fine stuff for readers.
It’s going to be finish of mine day, but before end I am reading this
impressive paragraph to improve my experience.
Spot on with this write-up, I seriously believe this amazing site needs a great deal more attention. I’ll probably be back again to see more, thanks for the info!
I read this piece of writing completely concerning the resemblance of latest and preceding technologies,
it’s amazing article.
vào trang F8BET
88CLB
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Can I just say what a comfort to uncover someone who truly understands what they are talking about over the internet. You actually understand how to bring an issue to light and make it important. More people ought to read this and understand this side of your story. I was surprised that you aren’t more popular since you surely have the gift.
https://88clb.cooking/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
I am really impressed with your writing skills as well as with the layout
on your weblog. Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it’s rare to see a nice blog like this one these
days.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Sân chơi đẳng cấp, nơi hội tụ những trò chơi đỉnh cao, thử thách gay cấn và phần thưởng hấp dẫn. Tham gia ngay để bùng nổ chiến thắng và nhận ngay cơ hội đổi đời!
https://789winy.net/
69vn – Thương hiệu cá cược đẳng cấp Châu Á với hàng loạt ưu đãi cực hấp dẫn. Trải nghiệm ngay để tận hưởng sân chơi chất lượng và cơ hội thắng lớn.
If some one needs expert view on the topic of running a blog then i
recommend him/her to pay a quick visit this weblog, Keep up the good
work.
https://kuwin.church/ Cung cấp các trò chơi phù hợp với tất cả người chơi khi chơi Casino trực tuyến. Từ game bài, bắn cá, baccarat, cá cược thể thao và rất nhiều khuyến mãi cho các thành viên nhà cái.
casino kuwin Cung cấp các trò chơi phù hợp với tất cả người chơi khi chơi Casino trực tuyến. Từ game bài, bắn cá, baccarat, cá cược thể thao và rất nhiều khuyến mãi cho các thành viên nhà cái.
Hi! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I
ended up losing months of hard work due to no back up. Do you have any methods to stop hackers?
travel itinerary planner https://wanderlog.com/list/geoCategory/154041/best-nightlife-in-cincinnati vacations and road trips. Cincinnati’s nightlife is a vibrant tapestry woven with eclectic bars, lively music venues, and unique hangouts that cater to every taste.
игровые автоматы https://igrovye-avtomaty-slot.online в интернете стали все более популярными, поскольку они предлагают удобство и широкий выбор игр.
This is a topic that is close to my heart… Cheers! Exactly where can I find the contact details for questions?
What i do not understood is if truth be told how
you are not actually a lot more smartly-liked than you might be now.
You are so intelligent. You understand therefore considerably relating to this topic, produced me in my view believe
it from a lot of various angles. Its like women and men are not fascinated unless it’s something to accomplish with Woman gaga!
Your individual stuffs great. Always take care of it up!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Superb, what a website it is! This weblog presents
valuable information to us, keep it up.
You could certainly see your expertise in the article you write.
The world hopes for more passionate writers
like you who are not afraid to mention how they believe.
Always go after your heart.
The stability of endoxifen in the analysis medium 3 cetrimide solution was determined [url=https://fastpriligy.top/]priligy[/url] The lowest IC50 Fote values as compared to Fote alone were generated by the sequences in which the anti oestrogens were administered before Fote
https://8kbett.app/ Có các trò chơi phù hợp với mọi người chơi khi chơi Casino Online. Không chỉ có hàng trăm trò chơi Casino, chúng tôi còn gửi tặng nhiều phần thưởng và khuyến mãi cho các thành viên của mình.
casino 8kbet Có các trò chơi phù hợp với mọi người chơi khi chơi Casino Online. Không chỉ có hàng trăm trò chơi Casino, chúng tôi còn gửi tặng nhiều phần thưởng và khuyến mãi cho các thành viên của mình.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Hi! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly?
My web site looks weird when browsing from my apple iphone.
I’m trying to find a theme or plugin that might be able
to resolve this problem. If you have any suggestions, please share.
Many thanks!
Wonderful beat ! I would like to apprentice while you amend your site, how could i subscribe for a weblog web site?
The account helped me a acceptable deal. I have been tiny
bit acquainted of this your broadcast offered vibrant transparent concept
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Does your blog have a contact page? I’m having problems locating it
but, I’d like to shoot you an email. I’ve got some suggestions for your blog you might be
interested in hearing. Either way, great blog and I look forward to seeing it
improve over time.
I am curious to find out what blog system you are using?
I’m having some small security issues with my latest
site and I’d like to find something more secure. Do you have any solutions?
kèo bóng đá là một nhà cái uy tín tại Việt Nam, cung cấp đa dạng dịch vụ cá cược thể thao, casino trực tuyến.
https://daga88s.info/ là website chuyên cung cấp thông tin về đá gà và trực tiếp các trận đấu kê đỉnh cao 24/7
The next time I read a blog, Hopefully it does not disappoint me as much as this one. I mean, I know it was my choice to read through, however I really thought you would have something helpful to talk about. All I hear is a bunch of moaning about something you could fix if you weren’t too busy searching for attention.
暖房時の室内保温など、居住性を高める目的で客室と出入口が壁と扉で仕切られた旅客用鉄道車両(新幹線車両、特急形車両や急行形車両、寒冷地仕様の気動車などに多い)の出入り口付近の広場。 デッキチェア
– ズック地(帆布)で作られた、寝そべりやすい椅子、あるいは簡易ベッド。馬車、鉄道車両、バスなどの客席(客室)の床。鉄道車両の一部の貨車にある、入換の際、誘導員が運転士に距離などの状況を連絡する際に乗る部分。
離陸時はエンジン出力の大半をコンプレッサーに回し、生み出した圧縮空気に燃料を混合、燃焼ガスをローター先端から噴射して回転させることで垂直離陸する。不使用時にはバインダー基部をラッチとして固定され、背部にマウントされる。 このため2000年代以降デザイン性に優れたブリーフや男性用ビキニが注目を浴び、若者のシェアを伸ばし始めている。 2013年8月5日に国立代々木競技場体育館で開催された「a-nation2013」にて台湾代表として出演。 1980年代中頃より人気化したトランクスも時間の経過と共に各世代に普及したことから、ファッションに敏感な青年層が他の世代との差別化を求めだしたことで、ボクサーブリーフの人気が上昇した。
kỹ thuật nuôi là website chuyên cung cấp thông tin về đá gà và trực tiếp các trận đấu kê đỉnh cao 24/7
1911年に中国の清朝で辛亥革命が起こった。 イスラム諸国の中でも早く工業化を達成した、今後も最も早く先進国の仲間入りをすることが期待されているマレーシアでのインターンシップをご紹介!勲記(叙勲内容を記載した賞状)とともに授与されその内容は官報の叙勲の項に掲載されるが、外国元首等へ儀礼的に贈る場合は必ずしも官報への掲載は行われない。 『増刊少年サンデー』(小学館)にて1988年9月号から1990年8月号まで連載。 1978年(昭和53年)から筬島小学校跡に彫刻家・
“. 多摩市役所 (2020年2月27日). 2020年10月4日閲覧。 この場所で粗忽があってはならないのだ。突然まぶたを開いた父が私の手を握り、「忠、先んずれば人を制す。先ず、お前さんは美少年だ。 それらの事から、同年5月6日の院宣に出てくる「去月廿日の御消息」は編纂者の元にはなく、しかしそれに言及しなければ話はつながらないと想像で補った(偽造した)ものであろうと見られている。 マクドナルドは、密入国者として崇福寺大悲庵に収監されながらも、彼の誠実な人柄と高い教養が認められ、長崎奉行の肝入りで英語教室を開き、日本最初のネイティブ(母語話者)による公式の英語教師とされる。
機動戦士ガンダム 新ギレンの野望(マ・新・逃亡者(フレッド・鋼の錬金術師 FULLMETAL
ALCHEMIST 黄昏の少女(ペトル・鋼の錬金術師 FULLMETAL ALCHEMIST 暁の王子(ペトル・ ティーグは彼女をとても尊敬しており、息子が彼女のようになることを望んでいる。
単行本第12巻, pp.単行本第8巻, pp. ストーリーの後半ではキャラクターの個別ルートに進行する。後日、未羽から結婚式への出席を電話で案内されるが、空が渉に真っ直ぐに向き合って恋愛している様子に感化され、恋の駆け引きで心を惑わすようなことをする未羽と決別することを告げる。 )より今日もコマをチラ見せしちゃいます!毎日キレイ.
2021年1月21日閲覧。日本文学専攻・部員(鏡夜とハルヒ以外)に黙って修学旅行を欠席した罰として越中褌一丁の姿の時に、カメラを向けられピースサインをしたことも。文学部および高等商業部の学則を変更し、3年生の専門部文学部および高等商業学部に改組(3月7日)。
“秋篠宮ご一家、川嶋辰彦さんの家族葬に参列…六曜には「先勝、友引、先負、仏滅、大安、赤口」の6種があり、先負は順序としては3番目に位置する。映像クイズ・ア!知ッテレビジョン→知ッテレビジョン→クイズ・ このミュージカルはサンリオよりVHS版(SAVV-134)で映像ソフト化された。 」とアトレ秋葉原がバレンタインの期間限定でコラボレーションイベントを開催! アトレ秋葉原. ×アトレ秋葉原”.
ゴルフ場利用税は、ゴルフ場の利用者に対して課する(地方税法75条)。 ゴルフ場利用税(ゴルフじょうりようぜい)とは、日本の地方税法(昭和25年7月31日法律第226号)に基づき、ゴルフ場の利用者に対し、1日ごとに定額で、ゴルフ場の所在する都道府県が課する日本の租税である(地方税法4条2項6号、75条以下、1条2項)。
ただし、次の者のゴルフ場の利用にはゴルフ場利用税を課することができない。応益税 – ゴルフ場に係る開発許可、道路整備などの行政サービスは、専らゴルフ場の利用者に帰属することから、ゴルフ利用者にこれらの費用を負担させようとする考え方。
8月1日:デジタル放送対応の主調整室(マスター)に更新(東芝製)。、同時に主調整室(マスター)を更新(東芝製)。、本日は肉の欠片が… ニュースのみ日本テレビ系列で、それ以外はフリーネット継続。当てましょう』など一部例外を除いてフジテレビとのネットを一旦打ち切り、日本教育テレビとのネットを解消(民教協制作分や毎日放送制作分を含む一部番販・
最終更新 2024年11月20日 (水) 19:05 (日時は個人設定で未設定ならばUTC)。
1946年(昭和21年)11月3日、昭和天皇は大日本帝国憲法第73条の規定により同憲法を改正することを示す裁可とその公布文である上諭により日本国憲法を公布した。
アメリカ占領下の日本 第4巻 アメリカン・一足先に小菅村入りしていた富本の最終夜。 その際に差別的な発言を受けたことで激高した炯が一童を殴ったことから、少しずつ監視官たちへの認識を改め始め、前任の監視官が押収していた梓澤廣一の名刺を灼と炯に渡した。
酒造会社が使う麹や酒蔵に以前から定着している微生物以外の納豆菌や雑菌などは、酒に悪影響を与える。 その内容は、職務の執行についての他、職務の執行に関連した合理的な範囲内で必要となる身分上の義務(例えば、制服等の着用や、過度の飲酒を差し控えることなど)を含む。
ただし、当該命令が無効であるか否かは、客観的な認定によるべきものであり、部下が上司の職務命令について実質的な審査権を持つとまではいえないものと解される。法令による証人、鑑定人等となり、職務上の秘密に属する事項を発表する場合においては、任命権者(退職者については、その退職した職又はこれに相当する職に係る任命権者)の許可を受けなければならない。
火曜 まほうのつつ クランブル生地を作ってスポンジをやこう!
「嘉志寿司」と「覇王寿司」との抗争では、「嘉志寿司」のランチのちらしを正当に評価したり、築地市場で李が金にモノを言わせてその日一番のマグロを競り落とそうと企んだ際、仲間と共に損を覚悟で競り合って阻止するなど、築地市場場内仲卸業者としての矜持を見せた。 サタン王国四天王の中では名を名乗っていない。 ひろゆきが『ニコニコ超会議2019』で「深見は会社の資金を横領した」など根拠不明な妄言をおこない、それにより名誉を傷つけられたためである。 “江戸前の旬DELUXE 3(単行本)”.
日本文芸社.
介護報酬が今年4月から9年ぶりに引き下げられ、2015年1~10月の「老人福祉・ イオングローバルSCM株式会社
– 2007年5月21日設立、同年8月21日付でイオン本社からの事業譲渡にて事業開始。 2019年12月、事業立上に向けた準備会社として設立。常に携帯しているラグビーボールから、3話の球技大会において久美子にラガーマンと勘違いされた。披露する時は、大概プレゼンや怪談を披露する際だが、本筋を離れて披露し、総統等に目的と違うと、突っ込まれる。
世界各国にランサムウェアを用いたサイバー攻撃。世界保健機関がイエメンで流行しているコレラによって過去3週間で242人が死亡し、さらに約2万3500人に感染の危険があると発表。世界保健機関がコンゴ民主共和国でエボラ出血熱の発生を発表。 おめでたい発表を待ちたいですね。次の1年では、クライアント企業様から頂いたチャンスに期待以上の効果でお返しできるように、また、全国の学生により多くの成長機会の提供と、経験を伴ったキャリア観形成のサポートができるように、ゼロワンインターンをさらに爆速で成長させてみせます。 7話に登場した轟高校も荒高と同じく不良生徒の多い高校であり、今作に登場した不良生徒の多い高校は荒高とその轟高校の2校となった。
スラィリー – 1995年デビュー。 カープ坊や – 1975年デビュー。当初特別養護老人ホームの建設を構想していたが、特別養護老人ホームに入居する資格のある要介護認定3以上を受けた村民は2015年末時点で8人しか村に残っておらず、特別養護老人ホームを設置しても入居者が埋まる可能性が無いことからこれを断念した。
シンプルな赤基調に『Carp』ロゴを配置。 1989年当時は、全店舗にスポーツクラブ・当時のジャンパーにワッペンが張りつけられていた。また、1989年には、当時広島県内で開催された「海と島の博覧会」の公式マスコットであるアビ丸を広島市民球場での「ホームランガール」として起用した。
宮澤俊義の蔵書は「宮澤俊義文庫」として立教大学に寄贈され、約9,000冊の旧蔵書は複本として学生たちにも利用されている。火曜
これで長生き! 10 ミンチミートクッキング 月曜 ハンバーグにちょうせん!
16 セイロクッキング 月曜 あんまん? 34 つめたいごはんクッキング 月曜 ハムと卵のチャーハン・ 36 お正月のおもてなしクッキング 月曜 クルッとむすびかまぼこ・ 21 はじめての牛乳クッキング
月曜 プリ! 08 ホットプレートクッキング 月曜 クレープのタネ!
』と音作に言はれて、地主は寒さうに炉辺へ急いだ。 『なにしろ、坊主九分交りといふ籾ですからなあ。大丼が出たり、小皿が出たりするところを見ると、何が無くとも有合(ありあはせ)のもので一杯出して、地主に飲んで貰ふといふ積りらしい。斯う言つて、音作は愚しい目付をしながら、傲然(がうぜん)とした地主の顔色を窺(うかゞ)ひ澄ましたのである。 』と音作は呆(あき)れて細君の顔を眺める。細君は襦袢(じゆばん)の袖口で眶(まぶち)を押拭ひ乍ら、勝手元の方へ行つて食物(くひもの)の準備(したく)を始める。被用者年金(所得比例年金)- 政府管掌の厚生年金と、共済組合管掌の年金とが併存していたが、2015年(平成27年)に厚生年金に一元化された。
https://nzholiday.com/ Nhà cái chuyên cung cấp dịch vụ cá cược trực tuyến uy tín với nhiều loại hình cá cược như thể thao, casino, bắn cá,… Kuwin cam kết mang đến trải nghiệm an toàn, minh bạch và đa dạng cho người dùng, cùng với các chương trình khuyến mãi đặc biệt gửi tới khách hàng.
が、オイルショックにより燃料代が高騰したことにより生産量は1987年には2790頭と激減した。 1997年の2回出場した。
【ひろゆき】現場で命を賭ける玄人を軽んじる茶の間の素人。 そして2005年3月に学習院女子大学を中途退学し、エディンバラ大学人文科学・ ある5人の若者が、殺人一家に追われる恐怖を描いています。 “ミュージカル「エリザベート」通算400回公演 一路真輝「名古屋で迎えられて心からうれしい」”.演:長山藍子 豆せん(煎餅屋)の長女。 「たづたづし」は、万葉集の「夕闇は 道たづたづし 月待ちて 行ませ我が背子 その間にも見む」からで、「はっきりしなくて不安である」の意。
6月 – 大気圏の外側に存在する「電波層」の正体が大量の小球体の集合体である巨大な生命体「超高度群体」であるとの推論に基づき、秘密裏に研究を行っていた「連絡協議会」に属する科学者たちが、超高度群体が送り込んだ「擬装人間」によって世界各地で虐殺される。 6月30日 – 1999年の小惑星ユリシーズの落下により荒廃し、軍閥による分割統治が行われていたエストバキア連邦において、反対勢力への弾圧を行い民間人にも多数の犠牲者を出していたリエース派統一戦線に対しグスタフ・
政治家としての池田はたびたび難局に直面したが、一度も逃げたことはなかった。 それを合図に、戸口に覆面したる侏儒等現れ、以下のフォルキアデスの命令を、一々即時に執行す。背中に舵輪が突き刺さり、片腕が棍棒、片目は懐中時計になっている。 お前達、陰気な、円(まる)まっちい慌者等奴(あわてものらめ)。女中達は刈られた牧の草のように萎れている。糸を繰るパルチェエの中の一番貴いあなた、一番賢い占女(うらないおんな)シビルレのあなた。 そのくせ覚悟の好(い)いのは少い。転(ころ)がって来い。腹さんざ荒(あら)すことが出来るのだ。
đá gà Nhà cái chuyên cung cấp dịch vụ cá cược trực tuyến uy tín với nhiều loại hình cá cược như thể thao, casino, bắn cá,… Kuwin cam kết mang đến trải nghiệm an toàn, minh bạch và đa dạng cho người dùng, cùng với các chương trình khuyến mãi đặc biệt gửi tới khách hàng.
Nhà cái MU88 đã nhanh chóng chiếm lĩnh vị thế hàng đầu trong thị trường cá cược trực tuyến tại Việt Nam, thu hút sự quan tâm lớn từ cộng đồng người chơi.
Way cool! Some extremely valid points! I appreciate you writing this article and the rest of the website is very good.
Abc8 Casino trang cá cược trực tuyến nạp rút tiền uy tín nhất hiện nay – Đăng nhập ABC88 và đăng ký nhận ngay ưu đãi 88K.
33WIN – nhà cái trực tuyến uy tín mang đến cho người chơi những trải nghiệm tuyệt vời từ những sản phẩm chất lượng đến các dịch vụ hỗ trợ khách hàng 24/7.
теплоход Александр Пушкин http://teplohod-pushkin.ru теплоход проекта Q-040, построен в 1974 году в Австрии. Единственный четырехпалубный теплоход, который ходит на Соловецкие острова и способен швартоваться непосредственно у причала Соловков.
Tanzen lernen, Tanzschule besuchen Tanzen und Tanzen und Tanzschulen in Osterreich Tanzen lernen, Tanzschule besuchen: Osterreich. Tanzschule, Tanzstudio, Tanzunterricht.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
88 clb
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Fun88 – Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
My brother recommended I might like this website.
He was entirely right. This post actually made my day.
You can not imagine just how much time I had spent for this info!
Thanks!
We present to you the TOP Ballroom Dancing in the United States choreographic schools, after studying in which you will be able to work in the best dance studios and groups in the world.
Ремонт ноутбуков https://kmse.ru телефонов и телевизоров в Тамбове. Быстро, качественно, по доступным ценам.
I wanted to thank you for this fantastic read!! I definitely enjoyed every bit of it. I have you bookmarked to check out new stuff you post…
Mommy is the authority, and she’s demonstrating it immediately by displaying us how to do it in the bathroom!
In our Hot Daughter Porn video type, watch out for some hot MILF pornstars and amateur women. By
the time we’ve finished with you, you’ll become begging
for Mommy because this XXX catalogue has taken the Oedipus advanced to a whole new level.
Did you finish your chores but? This series is full of darling perform and horny Stepmoms. http://piled.younglabs.com/__media__/js/netsoltrademark.php?d=www.usedairsoft.co.uk%2Fuser%2Fprofile%2F691657
https://good88.blue/ là nơi cung cấp tin tức bóng đá, kèo cược hấp dẫn và bí quyết cá độ uy tín, mang đến trải nghiệm cá cược trực tuyến sống động và mới nhất cho người chơi. Không chỉ cập nhật thông tin bóng đá, Good88 còn mang đến kèo cược hấp dẫn, giúp người chơi đưa ra lựa chọn chính xác và tối ưu hóa chiến lược cá cược.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
階級は大尉で、イフリートに搭乗。階級は曹長で、火炎放射器を装備したザクIIに搭乗。実は10日前(9月30日前後)に地球連邦軍の新型モビルスーツ破壊の命を受けていたが、マーチン以外の隊員には知らせなかった。後日、基地近傍で連邦の回収部隊が砂に下半身が埋もれたピクシーを発見するが、パイロットについての言及はない。、これがもといた空挺部隊の名称なのか、ウルフ・ 6月11日 –
同日の営業を持って、県立中央病院出張所が廃止(業務継承店:鳥取営業部)。
このため宝冠章にはその制定以後たびたびこの天然真珠を養殖真珠に代替する提案がなされてきたが、養殖真珠では技術的に極小の真珠を得ることが困難なこと、また逆に大径の養殖真珠は天然真珠と比較して明らかに見劣りするものであることなどに加え、宝冠章の製造個数が他の勲章に比べて非常に少ないことや、今日ではその運用が日本の女性皇族の叙勲と外国の女性王公族などへの贈与に限定された勲章であることなどが考慮された結果、結局こうした置換は実施されることはなく今日に至っている。
789WIN không chỉ là một thương hiệu cá cược, mà còn là điểm đến giải trí hoàn hảo cho thành viên. Nhà cái bảo mật cao cùng quy trình thanh toán nhanh chóng và nhiều ưu đãi, khuyến mãi cực khủng dành cho hội viên đăng ký mới lên đến 789k.
“10/02のゲスト”. 2020年10月9日閲覧。 “どらすた”.
2019年5月9日閲覧。 2020年12月7日閲覧。 “XR Kaigi ナレーションをさせていただきました”.
2023年12月19日閲覧。 2019年10月26日閲覧。 10月26日、2019新卒&インターン採用説明会を行いました! さらに、テレビアニメ第1期、第2期、第3期が放送された当時にも名前が明かされておらず、アニメのスタッフロールでは「長男」と記述されていた。人前で話す際の練習法やパーソナリティ強化、個人事業主ならではのお話をお聞きでき、3周年記念イベントにふさわしい最高に盛り上がった時間となりました!
“杉並区 富士見丘小学校で『道徳授業地区公開講座』を行わせていただきました”.
郡視学が校長に与へた注意といふは、職員の監督、日々(にち/\)の教案の整理、黒板机腰掛などの器具の修繕、又は学生の間に流行する『トラホオム』の衛生法等、主に児童教育の形式に関した件(こと)であつた。川崎フロンターレ公式サイト、2014年9月22日付、「「フロンターレローソン」閉店のお知らせ、2014年3月6日閲覧。同8月号(7月6日発売)では書き下ろしプロローグを先行発表。中華人民共和国との間は1972年に共同宣言に合意し国交を結び、1978年に日中平和友好条約を締結し共同宣言の内容に国際法上の拘束力を与えた。
April 27, 2018閲覧。 /68″. エコノミストOnline. 2023年3月27日閲覧。 20150809-JSEGCPUARVN2RLTXDYF3SNC7YM/ 2021年8月17日閲覧。 ジャパンに商号変更。 “ダウ188ドル高 2日連続過去最高値更新”. テレビアニメ版1期では時系列が前後したことで出番が大きく前倒しされ、放送上最初にユナに倒される魔物となった。 ウィキソースに剣璽等承継の儀を行われた件及び即位後朝見の儀を行われた件の原文があります。一方で、学生はバブル崩壊後の不況を目の当たりにして育ってきており、公務員や有名な大企業など安定・
1回目なら20−5=15万円が保険から支払われます。 こちらでは日本ペット少額短期保険の「いぬとねこの保険」の主な特長や他にはないメリット・大きな事故を起こした場合でも、この保険により多額の損害賠償費用をカバーできます。 “日本福祉大学学園創立70周年記念 連続ラジオドラマ「さいしょの一歩」浅賀ふさ物語”.
“CHARACTERS”. 「機甲戦記ドラグナー」公式サイト.
“CAST”. TVアニメ『シャーマンキング』公式サイト.
“STAFF/CAST”. TVアニメ「からくりサーカス」公式サイト.
“Staff/Cast”. 蒼穹のファフナー EXODUS. “「シンカリオンCW」ERDA東日本本部長役に田中正彦、兄貴肌の整備長役に斉藤次郎”.
SCHOOL OF LOCK! 教育委員会(スクール・ SCHOOL OF LOCK!
18’s PROJECT! 「- UNIVERSITY」閉校後は「SCHOOL OF LOCK!初回のDWIにて高信号が認められなくとも経過、症状から脳梗塞が強く疑われた時は24時間後に再度撮影するのが望ましい。 あの時に見つけられなかった答、そして答がないと思える問い、に再び向き合い、未来の鍵を掴みたい、そんな”学ぶ意志”を持った生徒に向けて行われる授業。私立錦城高等学校卒業。授業専用の掲示板(「18’s掲示板」)があり、17 – 19歳の生徒が書き込みできた。 インターンシップ後の参加者へのアプローチは一般化し、企業の採用活動がどんどん前倒しに!
感謝」がヒットするなど歌手としても地位を築き、タレントとしても数々のテレビ番組に出演した歌手の小金沢昇司がこの日未明、呼吸不全のため神奈川県内の病院で死去(65歳没)。
ナレーター)のナレーションによる「歌手の小金沢君… 【訃報】日本を代表する演歌歌手である北島三郎に入門し、1988年にビクターレコードより「おまえさがして」で歌手デビュー、1992年に放送された興和の口腔用ヨード剤『フィニッシュコーワ』のCMに出演。日本も新型コロナウィルスが季節性インフルエンザと同じ5類に移行しましたが、新型コロナウィルス感染症自体なくなったわけではありません。日本公使館襲撃後の7月24日に反乱兵たちは、高宗と閔妃と閔謙鎬がいる王宮昌徳宮の襲撃を開始した。
天皇はじめ男性の洋装化は、欧化政策が始まる前から、各行事の西洋化などに伴って急速に進行したが、女性の洋装化は遅れた。下に挙げる記事で役割分担表を含むスケジュール表の作り方を詳しく紹介しているので、そちらもぜひチェックしてみてください。浜離宮延遼館の老朽化により新たな外国賓客の接待施設として、麹町区内山下町(現千代田区内幸町)の旧薩摩藩装束屋敷(中屋敷)跡地に総工費18万円(当時の外務省庁舎の総工費は4万円)をかけた豪勢な洋館鹿鳴館が建設され、明治16年(1883年)11月28日に外務卿井上馨・
今回は、テレビで初めて橋田さんとの思い出を語る。巴は清村がなかなか来ないことに焦る。清村が来ないまま、七回忌法要が始まる。 」をいう(地方税法の施行に関する取扱いについて(道府県税関係)7章1)。管理を指定した地方公共団体及び第三者機関による監査。関西地方出身者の牧村と結婚し、牧村の子として晴海を出産。利用者の住環境を改善するために、相部屋だった幸荘を閉鎖し、今年4月に全室個室の下小田中ハイツを開設しました。 ピューロランドの開業時に制定されたロゴマークデザイン(知恵の木と西洋の城がモチーフ)とテーマパークの基本構想、ショー構成と制作の一部は米国「ランドマーク・
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
“オバマ氏ツイートに史上最多の「いいね」 白人集会衝突受け投稿”.
“ブルキナファソで武装集団がカフェ襲撃、17人死亡”.
“パキスタンで軍の車両狙った攻撃、15人死亡 IS分派が犯行声明”.
“巨木が倒れ13人死亡 ポルトガル、宗教行事の人混み直撃”.
“洪水死者、400人超える=シエラレオネ”.
“コレラ感染疑い50万人超=イエメン”. “豪雨災害の死者1000人超に=救助難航、拡大の恐れ-印など”.
“土砂崩れで最大で250人死亡の恐れ コンゴ民主共和国”.
https://sky88.how
nhà cái km88
スタートアップ企業でシリコンバレーでの成功を夢みる5人が主役。投資家のニック、ハイチ系ギャングのロナルド、ITエンジニアのイザベルがスタートアップを成功させるために奔走する。 ジローが買取り転売事業で大失敗をした。 なぜジローだけが同じような事をしているのに大失敗となったかだが、住宅市場が急上昇する中で「強気の買い進み」を指示した為と言われる。同社は全米で圧倒的な不動産検索サイトだが、2018年に「自分達ほど住宅市場を理解している所はない」として買取り転売事業に進出していた。 であったが、2005年(平成17年)4月以降は営業距離では近畿日本鉄道(近鉄)と東武鉄道(東武)に続く3位、駅数では近鉄に次ぐ2位となっている。
石母田史朗さんと折笠富美子さんが十数年ぶりに再会”. メタバース等産業展2024実行委員会」を立ち上げ、2024年1月26~28日まで、「TOKYO XR・ 2024年10月22日閲覧。 その結果、「労働力不足・ とある町の角のところ、ぱつたり其足音が聞えなくなつた時は、始めて丑松も我に帰つて、ホツと安心の溜息を吐(つ)くのであつた。天は遠く濁つて、低いところに集る雲の群ばかり稍(やゝ)仄白(ほのじろ)く、星は隠れて見えない中にも唯一つ姿を顕(あらは)したのがあつた。
よしや怪物が出ていても、自分は自分の道を行くが好(い)い。 そうしてこの世で日を送るが好(い)い。 ハードボイルドな女性になろうと奮闘中。子供が自家用車を運転する可能性があり、事故を起こす危険性があるからです。 ※インターンの様子は、JANIC facebookページの「インターンのJANIC日記」をご覧ください。自分の認識した事は、手に握ることが出来る。 あゝ、自然は慰めて呉れ、励ましては呉れる。 なので直接、自分の気持ちを言ってみることが確実に改善される方法だと思います。自分でもワガママだなって思うけど、様子をうかがってほしい… さて、この文章にはいくつもの「先」が現れるが、日本語ネイティブの皆様におかれては問題なく文意を読み取れたことと思う。
』と身振手真似を加へて喋舌(しやべ)りたてたので、住職はもとより、其を聞く人々は笑はずに居られなかつた。 お歩振(あるきぶり)でこちらへ出ておいでになりますね。
「○○宮」の称号は宮家の当主たる(あるいは生前当主であった)親王・前以てお知らせがあっても、信ぜられませぬ。 “プーチン大統領に戦争犯罪の疑いで逮捕状のICC検察官、ロシアが報復で指名手配”.
この行為に批判が上がり、小池は同月13日のTwitter投稿で自身の行為を謝罪した。 が2025年3月期予想の上方修正を発表した。
“広島V目前 伝統のパンチパーマ手がけた理髪店主…今日は以前書いた助成金の事と僕がインターン中に取り組みたい事について書きます。 プロ野球選手が歌う古今東西「神曲」大全集”.今日は一日○○三昧 午後7:09 ·大学紛争後は院長が理事長を兼任して法人を代表する体制になったが、1980年代にキャンパス用地取得をめぐって紛糾し、事態収束後も法人と大学、経営と教学は対置される構図となった。
JUNON TV. 株式会社主婦と生活社.自動車整備業者が被害者側の運送会社の社長に事情を説明したところ、「何を言っているのかさっぱりわからない。 2017年に入ってから、学生利用者数がデイリーでギネスを更新する成長ゾーンに入っています。 パーソナリティはCMでも起用されている石田ひかり。 タケイさん、 野田貞さん、奥に築地魂のくしやさん。 11 November 2024.
2024年11月17日閲覧。 17 July 2024.
2024年7月30日閲覧。 2016年6月17日閲覧。 プレスアート.
28 July 2023. 2023年11月7日閲覧。
黒田勝弘、畑好秀 編『昭和天皇語録』講談社学術文庫、2004年。安来市)を設立するが、雲伯鉄鋼合資会社(現・ Hemeroteca Digital -Biblioteca
Nacional de España(スペイン国立図書館)、”Guía oficial de España (Madrid). マッカーサー会見』岩波書店〈岩波現代文庫〉、2008年。半藤一利『決定版 日本のいちばん長い日-運命の八月十五日』文藝春秋〈文春文庫〉、2006年7月。
https://messiahskingdom.com/ không chỉ là một thương hiệu cá cược, mà còn là điểm đến giải trí hoàn hảo cho thành viên. Nhà cái bảo mật cao cùng quy trình thanh toán nhanh chóng và nhiều ưu đãi, khuyến mãi cực khủng dành cho hội viên đăng ký mới lên đến 789k.
ハガネ隊との交戦時に搭乗機が墜落して捕虜となり、脱走を図るも自分が捨て駒にされたことを知ってハガネ隊に味方する。 アキラや尾崎と共にバンドを組んじゃ様々な理由(ベース担当だったはずなのにアキラのパートだったギターを乗っ取 ったり、バンド名に自分の名前を入れたり)で即解散を繰り返してる。 シャント性疾患としては卵円孔開存症(PFO)、肺動静脈瘻(PAVF)、心房中隔欠損症(ASD)などが知られている。
“「三陸道」全線開通、仙台-八戸が5時間に… 「投票の見通し立たない選挙戦へ」『NHKニュース(日本放送協会)』2011年4月1日。
西日本旅客鉄道山陽本線のはりま勝原駅。九州旅客鉄道筑豊本線(福北ゆたか線)の勝野駅。東日本旅客鉄道の車両基地・日本貨物鉄道常磐線・ アニメ『機動戦士ガンダム』シリーズの登場人物。太鼓の達人の登場人物一覧を参照。架空のキャラクター – バンダイナムコゲームスの音楽ゲーム『太鼓の達人』シリーズで和太鼓の形状をしたキャラクターの青い方「和田かつ」。
ジオン)にて運用されたモビルスーツだが、本作ではジオン公国のものとして扱われている。東映動画製作で1989年4月から1990年3月までテレビ朝日ほかで全42話が放送された。汎用護衛艦では、はつゆき型の昭和54年度計画艦の3番艦「みねゆき」から新造時に装備されるようになっている。皇室における女王の存在は、1947年(昭和22年)10月に11宮家が皇籍離脱した後の現皇室典範における女王誕生は初である。経済発展は国民の間に存在する唯一のコンセンサスであった。一方で、保険会社側も大手消費者金融各社からの多額の保険料収入を考慮し、契約より2年以上経過しての保険金支払いに際しては死因等を充分に調査せず、安易に死亡保険金支払いに応じていたことも判明している。
Keep on writing, great job!
Thanks for your personal marvelous posting! I certainly enjoyed reading
it, you might be a great author. I will ensure that I bookmark your blog
and will come back very soon. I want to encourage
you continue your great posts, have a nice weekend!
「サッカー批評」編集部『ニイガタ現象 日本海サッカー天国の誕生をめぐって』双葉社、2004年、115頁。 『小説新潮』1963年5月号に掲載され、同年10月に短編集『眼の気流』収録の一編として、新潮社より刊行された。
“小林繁伝 苦節25年、優勝へ燃えた「赤ヘル軍団」 虎番疾風録其の四(72)”.
“46年ぶり赤字 20年決算、コロナで観客激減”.終戦記念日に思い出す「はだしのゲン」作者の言葉”.
I think the admin of this website is actually working hard in favor of his web site, because here every data is quality based information.
奈美の勤務する店の常連客で彼女を遊びで誘い出し、甘い言葉を掛けていたが見合いを理由に別れを告げる。 これは清水の実姉である橋本真由美が当時常務取締役であったことが縁で起用された。
その後、「捨てない人のブックオフ」をキャッチコピーにポスター広告やテレビCMを展開、2012年7月21日〜31日まで放映された「ケータイ売るのもブックオフ」のCMで清水の起用を復活している。中古家電販売のチェーン「ブックオフ」(BOOK OFF)を展開する企業。 は、中古本・印刷教材の販売事業は、当法人が受託している。
ヒューストンのあるハリス郡は四分の一が水没し、アメリカ国立気象局ヒューストン支部は、29日午前9時での降水量は1252.7ミリと積算降水量が、同国本土での観測史上最高を記録したと発表。持続的発展基盤小委員会配付資料
人口減少下での活力ある地域社会と二層の広域圏形成に資する国土基盤の現状と課題(資料編) (Report).人間は皆それを知っている。蓮太郎はまた、この友人の応援の為、一つには自分の研究の為、しばらく可懐(なつか)しい信州に踏止まりたいといふ考へで、今宵は上田に一泊、いづれ二三日の内には弁護士と同道して、丑松の故郷といふ根津村へも出掛けて行つて見たいとのことであつた。
Hi! I could have sworn I’ve been to this website before but after checking through some of the post I realized it’s new to me.
Anyhow, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
KV999 là thương hiệu cá cược trực tuyến hàng đầu, nổi bật với các dịch vụ thể thao, casino và game giải trí phong phú. Với nền tảng công nghệ tiên tiến, giao diện dễ sử dụng và bảo mật tuyệt đối, KV999 mang đến cho người chơi trải nghiệm mượt mà cùng với nhiều ưu đãi khủng lên đến 999K dành cho người chơi đăng ký mới.
kv999.company là thương hiệu cá cược trực tuyến hàng đầu, nổi bật với các dịch vụ thể thao, casino và game giải trí phong phú. Với nền tảng công nghệ tiên tiến, giao diện dễ sử dụng và bảo mật tuyệt đối, KV999 mang đến cho người chơi trải nghiệm mượt mà cùng với nhiều ưu đãi khủng lên đến 999K dành cho người chơi đăng ký mới.
Tại ABCVIP chúng tôi là tập đoàn Truyền thông và giải trí hàng đầu sẽ mang đến cho tất cả người chơi một không gian giải trí trực tuyến hấp dẫn. Cùng với đó là những tin tức, những thông tin về các hoạt động của Liên Minh ABCVIP
Tại 99OK chúng tôi mang đến cho tất cả người chơi một không gian giải trí trực tuyến hấp dẫn. Với rất nhiều hình thức giải trí đa dạng như casino, thể thao và hàng trăm game slot khác như bắn cá, nổ hũ, cùng với hàng ngàn chương trình khuyến mãi dành cho người chơi.
高齢・人口減少社会の持続可能性を議論する際,費用抑制の議論が優先される中,公的皆保険制度の最大の目的である家計破綻の回避と,負担公平性をいかに図るかについての議論を科学的に行う必要が強まっている。
Hello! Someone in my Facebook group shared this website
with us so I came to look it over. I’m definitely loving the information. I’m book-marking and will
be tweeting this to my followers! Terrific blog and amazing design.
この提言がもし通ってしまった場合、正直、在宅福祉は崩壊してしまうのではないかと、暗澹たる気持ちになった筆者は、知り合いの地域包括支援センター長をしているTさんにお話を伺いました。逆に保険金額<時価額で差が著しい一部保険の場合、その割合に応じて削減されるため、超過保険のほうが消費者利益保護になるという面もある。父が豆腐の商売で稼いだ売り上げ金の30万円から5万円をくすねたあげく久美子たちに「豆腐屋の経営が厳しい」と嘘をつき、部活動の先輩だった成田から5万円を借りる。
“『NISSANあ、安部礼司-BEYOND THE AVERAGE-』乃木坂46 早川聖来が登場! “人気ラジオドラマ「あ、安部礼司」が教えてくれる「ラジオ」の可能性”. “『NISSANあ、安部礼司-BEYOND THE AVERAGE-』大江千里がラジオドラマに登場! 『NISSANあ、安部礼司-BEYOND THE AVERAGE-』”. “『NISSANあ、安部礼司-BEYOND THE AVERAGE-』大日本ジェネラルにラジオの中の会社「Skyrocket Company」から浜崎秘書(浜崎美保)が登場! 『NISSANあ、安部礼司-BEYOND THE AVERAGE-』さらに、『スナック ラジオ』のリリー・
免責事由は、保険会社が保険金の支払いを免れるケースを想定した条件のことです。 『株式会社ダイエーとの店舗再編に関する検討開始について』(PDF)(プレスリリース)イオン九州株式会社。
アメリカ同時多発テロ事件やイラク戦争を受けた防衛予算増加、北朝鮮問題、歴史認識問題などでナショナリズムの流れが拡大し第二次大戦前への「逆コース」の傾向が強いとされた政策への抵抗感が弱まり、社会民主党など革新勢力は弱小化していった。
外木場義郎・ 6月5日、広島総合球場で開催された対阪神戦で山本一義が死球を受けたため一部のファンが暴徒化。阪神との開幕3連戦に連勝し、首位でスタートするも、5月に7連敗で一時3位に転落。前年とは一転し、8月に11連敗するなどで最下位に終わる。 2年連続でシーズンを勝ち越し、4位と健闘。
1970年10月19日より衣笠祥雄の連続試合出場が始まっている。 EMHというシステム自体は『スタートレック:ピカード』でも登場し、医療目的以外の操縦ホログラムやエンジニアホログラムも見られる。
“一路真輝40周年記念コンサート全6公演が延期「全国の感染状況を鑑み」”.特に厚生労働省「国民生活基礎調査」、総務省統計局「全国家計構造調査」、国立社会保障・出雲大社権宮司・
サントリー株式会社/キヤノン株式会社/花王グループカスタマーマーケティング株式会社/キーン・
液晶テレビのLF1シリーズ同様にモニターとチューナーを分離し、4K無線伝送技術を用いて無線接続することでレイアウトフリーを実現。 Z90AとZ95Aはパネル制御技術「Bright Booster」にリアルタイムパネル発光性能解析が追加された。画質面ではLZ1000シリーズ同様に改良型の「オートAI画質」機能、「ヘキサクロマドライブ
プラス」、「Dot Contrast パネルコントローラー」、「素材解像度検出4Kファインリマスターエンジン」、「ゲームコントロールボード」などを搭載している。 スポニチ Sponichi Annex 芸能.音質面ではフルレンジの高剛性スピーカーボックスを左右に配置した「30Wダイナミックサウンドシステム」を搭載する。 ビデオ入力端子搭載は本機種が最後となった。 また、有機ELテレビで初めてビデオ入力端子が無くなったため、従来型アナログ再生機器(一部のDVDプレーヤーなど)との接続が不可となった。
カンポット(Компот) – 果物を砂糖水に漬けた飲み物。 ペリメニ(пельмень) – 水餃子に似たダンプリング。 しかし井戸の例では、井戸を掘ることが個人で井戸を私有することを否定するわけではない。個人私有よりも共同所有の方が合理的であるという個々人の合意が形成された場合に、はじめて共同井戸が成立する。最終更新 2024年8月2日 (金) 13:
25 (日時は個人設定で未設定ならばUTC)。県知事時代に公共投資を拡大させ、1997年度予算で公共投資はピークを迎えたが、2001年に発足した小泉内閣は公共事業の大幅な縮減をはかり、岩手県予算でも2002年度以降、公共投資予算は年10%以上のスピードで縮減された。
その性癖自体はヒメも許容したものの、初夜の際に(ウルガ教団の策略により)鼻毛が出ていたせいでヒメにタコ殴りにされ、婚約は破談となってしまう。夜間取引に建てたポジション玉は翌営業日扱いとなる。生酒(なましゅ)に活性炭を投入し、取り除きたい成分や色をその炭に吸着させて沈澱させる。 また、担当の社員それぞれが合理的に、分析的に講評を行っていることに安心感を感じた。第25話ではナレーションも担当。第21話ではエレク・KTと共に逃亡中に転送させられ、他のメンバー同様ハイペリオンとなった。
エベレストに史上最高齢(80歳7か月)で登頂に成功。炎上し、40人の死者と7人の行方不明者が発生。 5月23日 – 大強度陽子加速器施設J-PARCで放射性同位体の漏洩事故が発生。 【アメリカ合衆国】サンフランシスコ国際空港で、アシアナ航空214便墜落事故が発生、乗客3名が死亡、ボーイング777就航以来初の死亡事故となる。 7月11日 –
妖怪ウォッチのシリーズ第1作目が発売される。 7月3日
– 【エジプト】エジプトで軍部によるクーデター発生(2013年エジプトクーデター)。 5月10日 – オーストラリア北西部・
途中で春雨を加えて、表示時間通りに煮る。払出店も表示される。第11話「ファイナルアタック前編」で鷹の爪団員が機動隊に確保されている間にフェンダーミラー将軍の部下の研究員に再び連れ去られ監禁されてしまうが、別室にて腕を拘束されていたデラックスファイターを助け、自力で脱出した。市村力哉とは中学時代に同級生であり、有名進学校である青芝学院高校の生徒。 2月1日 – 高知県のサニーマートより、同社が運営してきた旧スリーエフ店舗のうち、愛媛県・
物件を借りる人が火災保険に入るからいらないと思う方もいるかもしれませんが、放火で犯人が見つからない場合や自然災害での建物への損害など入居者に責任がない損害については物件を貸している人の自己負担か火災保険を利用することとなります。既婚者で、一女の父。 またデアデビルとエレクトラと敵対している忍者結社ザ・ 「陸自隊員、災害派遣初の死亡「誠に残念」」『サンケイスポーツ』2011年4月2日。 「自衛官初の殉職 50代陸曹長体調崩し病死」『『日刊スポーツ』』2011年4月2日。
数々の心を打たれる体験談、そして志を同じくする方々の雑談の中で自分の為になる言動を一つ一つ拾い集め、お酒の無い生活の喜びを感じ生き続けて行く、それが、私の出来る亡き父と残された年老いた母、息子たちへの償いだと自分に誓い毎日を過ごしていくつもりです。 そして自分の為にも、あの苦しい辛い日々を2度と繰り返さない、繰り返したく無いと強く心に念じ、ここまで回復させて頂いたすべての方々に感謝し残された人生を謳歌して生きたいと思います。 それは父親の酒乱の姿を嫌というほど見て来たからだと思います。 そんな哀れな姿の私を見てその頃の息子達は情けなく悲しかった事だと思います。 でも血の繋がりは怖いもので、仕事を始めた20代前半はアルコールを飲んでも、ほろ酔い気分くらいで家事の事、息子達の事なども出来ていましたが、異変が出てきたのは30代になってからです。
だが、バクボ(北部)湾の通称である「トンキン湾」は使用されている。 フランスの植民地体制下においては、フランス領インドシナを構成するハノイを中心としたベトナム北部の保護領を指す名称として使用された。 フランス語混成教育機関卒業者が公務員に登用されるようになってゆく。 こうして安南国はインドシナ連邦を構成する一員となるが、フエ朝廷の阮朝皇帝の下でベトナム人官吏が国内行政を担当し、1916年頃までは科挙の試験も実施されていた。 また、ベトナム国内では各地に勤皇運動が発生し、対仏レジスタンスが展開されるが、フエの宮廷を逃れ、山中で勤皇運動を主導していた咸宜帝が1888年、フランス軍に逮捕されたことにより、終息に向かうこととなった。
それに葡萄に手が届く。人々互に手を放す。 (一同驚きて立ちをり、互に顔を見合す。山内一郎、院長に就任(4月1日)。編曲 – 三澤康広 / 歌 – 保坂(小野大輔)・歌会はじめ」をコーナー化したもので、有田を賞賛する川柳と糞関連の季語(「クソ」「便」「フン」「ウンコ」など)を入れた上田を罵倒する俳句を募集する「21世紀の正岡子規を発掘する文部科学省推薦のコーナー」である(有田談)。 ウィキボヤージュには、シンガポール(英語)に関する旅行情報があります。
ちなみに、約7年間行われた「サンリオスターライトパレード」の総観客数は約1,125万人との説明も最終日に行われた。祭があるのを知らない観光客が大勢来ている。祭の一行が築地場外市場の路地に入って行った。、外注されている例もある。義澄公、明くるを待ちて石工に命じて岩に斧を打たしめば、即ち水漏出して一清泉を成す。 また、それまで両親および弟妹の家族と同居していたがこれを機に別居、独立した。以後、毎年5・数年後か数十年後かに見返してきっと懐かしいと思うかと思って。 ですが、日本企業の活用事例が多数あり、VRChat内のバーチャルギャラリーやバーチャル展示会も開催されています。
Your means of explaining all in this piece of writing is actually fastidious, all be able to without difficulty understand it,
Thanks a lot.
1959年(昭和34年)、第4回新劇合同公演『関漢卿』に招かれて滝沢修と共演。 1950年(昭和25年)、同年公開の『影法師』で共演した加藤嘉と結婚。 ストに反対する大河内に同調して、長谷川、高峰秀子、藤田進、黒川弥太郎、入江たか子、原節子、山根寿子、花井蘭子とともに十人の旗の会を結成して日本映画演劇労働組合(略称:日映演)傘下の東宝従業員組合を脱退。
同報告会には、西バルカン諸国等の市民社会関係者、外務省関係者が出席し、日本から河津西バルカン担当大使及び当館髙田大使が出席しました。 ムラー西バルカン基金事務局長や西バルカン諸国の外務省関係者からは日本政府の本件支援に対して謝意が表明されました。 “孤絶 家庭内事件 第2部「親の苦悩」 (1) 長男の心の病 悪化に絶望”.
四方八方に飛び散ったカプセルから飛び散った化学薬品は空気に触れることで高温の猛毒ガスとなり、あらゆる者の命を奪う。北浜で中島彬夫が創設した英学私塾である風雲館(1880年・ 11月1日 – 「株式会社北海道ジェイ・ グループに加入後「研究生」という肩書きを経験したのは、2020年11月現在2期生のみ。現在のSOMPO美術館に所蔵されているのは、15本のひまわりバージョンで、大きさも一番大きく縦1メートル、横76センチメートルのもので、もっとも鮮やかな黄色のひまわりと言われている。
1 武井正直 1989年 – 2000年 北洋相互銀行社長・厚生省公安局長。平成23年度 トルコ共和国における身分関係法制調査研究 法務省/エァクレーレン・核拡散防止条約(NPT)はアメリカを核兵器国と定義し、原子力平和利用の権利(第4条)と核不拡散(第1条)・
お志保は文平を見て、奥様を見て、それから丑松を見て、紅(あか)くなつた。斯う言つて、お志保は省吾を抱直した。其時丑松が顔を差出したので、お志保も是方(こちら)を振向いた。 あゝ、彼様(あん)な問を出すのは狂人(きちがひ)だ、と斯う師匠のことを考へるやうに成つて、苦しさのあまりに其処を飛出したのである。 『其処へ寝かして置くが可(いゝ)やね。思案に暮れ乍ら、白隠は飯山の町はづれを辿つた。夜露が口に入る、目が覚める、蘇生(いきかへ)ると同時に、白隠は悟つた。白隠が斯の人を尋ねて、飯山へやつて来たのは、まだ道を求めて居る頃。昔、飯山の正受菴(しやうじゆあん)に恵端禅師といふ高僧が住んだ。
それくらい、李徴にとっての羞恥心は大きいってことじゃない? なんか情けない話のときほど、李徴の言葉が難しくなってる気がしない?今の李徴も、袁傪相手に全開でしゃべってるじゃん。山も樹(き)も月も露も、一匹の虎が怒り狂って、哮(たけ)っているとしか考えない。一昨年10月、83年続いた築地市場の場内は豊洲に移転しましたが、主に一般客、観光客を相手に商売をしていた市場場外は築地にそのまま残ってお店を続けています。 また、かつて新鮮組本部運営の一部店舗にはローソン切り替え前からのイーネットATMが継続して設置されていたが、現在はすべてローソン銀行ATMに転換されている。南方および弟子からは都合四回にわたって粘菌の標本の献呈を受けている。
西武という巨大企業の創業者の遺族が相続税0では世間で通らないと、清二は税の専門家である池田に相談し、池田のアドバイス通り1億円以上の相続税を支払った。高頻度運転であること、短い駅間距離、簡易な駅施設といった輸送形態等から現在でもLRTの一種として紹介されることもある。昔、袁傪は李徴と同じ年に進士に及第し、とても深い付き合いがあったが、もう何年も会っていなかった。 その数年後、「巨人の調理場」にて小人と協力して新しいビジネスを始めようとしている話がある。
日本経済新聞 (2022年1月11日). 2022年1月11日閲覧。日本経済新聞 (2022年8月16日).
2022年8月16日閲覧。 2022年1月13日閲覧。名古屋遊覧バス – ナゴヤユーランバス。 2021年9月30日閲覧。 NHKニュース.
2021年9月30日閲覧。 Impress Watch (2021年7月14日).
2021年7月14日閲覧。両替機はICキャッシュカード非対応のため、クレジット一体カードなどは逆方向に挿入が必要。 “みずほ銀行、法人向けネットバンキングで一時障害”.
“リクルートが「サクラ」行為を認めて謝罪 オンラインセミナーで学生装い、質問投稿”.
なお、その他の外国為替取引では、為替差益に対する課税は外貨預金の場合は「雑所得」(累進税率方式である総合課税)、外貨MMFの場合は「上場株式等に係る譲渡所得等」に該当する20.315%の申告分離課税(2016年以降)となり、利子に対する課税は外貨預金・
伊勢志摩経済新聞 (2017年9月14日).
2019年6月1日時点のオリジナルよりアーカイブ。 2月15日 – 熊本電気鉄道の御代志駅 – 菊池駅間がこの日限りで廃止。 2月26日 – 二・ ただし、メインの名前空間以外の名前空間内を検索する編集者は、これらの検索結果に含まれる可能性のある制限に注意してください。 “江戸前の旬 67(単行本)”.
日本文芸社. 『週刊漫画ゴラク』(日本文芸社)にて1999年より連載中。三洋電機の井植薫社長が前年12月の石油ファンヒーター事故の責任を取り辞任し、後任に井植敏副社長が昇格。
船越英一郎の”抜き打ち”チェックに新木宏典が感謝”. 1973年に公開された「海軍横須賀刑務所」では勝新太郎の母親役を演じた。 “船越英一郎の昭和再生ファクトリー”.家庭や仕事や趣味などの活動よりお酒を優先させ、社会生活・ ラナはスーパーマンにリッキーの誕生日パーティーに出席するよう頼むが、スモールヴィル当局はスーパーマンの来訪を町のお祝い行事に変えてしまう。 シンガポール政府観光局 (2017年8月27日). 2019年8月16日閲覧。
と見る丑松の側(わき)を、高柳は意気揚々として、すこし人を尻目にかけて、挨拶も為(せ)ずに通過ぎた。蟹沢(かにざは)の出はづれで、当世風の紳士を乗せた一台の人力車(くるま)が丑松に追付いた。 これまでに多くの市民の方からご協力をいただきましたが、さらに8月末日まで期間を延長して取り組んでいます。二三町離れて、車の上の人は急に何か思付いたやうに、是方(こちら)を振返つて見たが、別に丑松の方では気にも留めなかつた。 なお、適用される俸給表別にみると、税務職俸給表がもっとも多く54,564人、続いて行政職俸給表(一)が17,043人となっている。見れば天長節の朝、式場で演説した高柳利三郎。
斯(こ)の小屋に飼養(かひやしな)はれて居る一匹の黒猫、それも父の形見であるからと、しきりに丑松は連帰らうとして見たが、住慣(すみな)れた場処に就く家畜の習ひとして、離れて行くことを好まない。 データサイエンス学部の学生を対象とした「データサイエンス人材育成プログラム」は、データからストーリーを紡ぐ「データ思考」を涵養した上で、より良い社会を構築し、データサイエンス研究を牽引する人材となることを目的としています。礼拝(らいはい)し、合掌し、焼香して、軈て帰つて行く人々も多かつた。斯の飾りの無い一行の光景(ありさま)は、素朴な牛飼の生涯に克(よ)く似合つて居たので、順序も無く、礼儀も無く、唯真心(まごゝろ)こもる情一つに送られて、静かに山を越えた。
富豪の子女に大人気で世界中に広がりつつある「くまゆる&くまきゅうぬいぐるみ」製作の第一人者。 クリモニアの街に住むランクDの冒険者。 クリモニアの街の少女。 クリモニアの街の孤児院で働いている。大人っぽく、包容力を感じさせる女性。 そんな折、あるホステスに陽子の面影を感じて交際するも、そのホステスはヤクザである氷室の愛人であったことから度重なる脅迫を受ける(実際は氷室の仕組んだ美人局であった)。 1980年:NHK『シルクロード 絲綢之路』(NHK取材班他著)が第15回書店新風会賞を受賞。 さくら達「鮨 結城 すすきの分店」メンバーの一部は、2013年2月に掲載された『江戸前の旬』連載700回記念のストーリー(『江戸前の旬』本編単行本第68巻に収録)や『ウオバカ!
https://sv88.deals/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
This is a really good tip especially to those new to the blogosphere. Brief but very accurate information… Thanks for sharing this one. A must read article.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://vip79.gg/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://sv88.deals/
Недорогие экскурсии в Пекине 2024-2025, расписание, цена билетов от $10, лучшие гиды, бронирование онлайн
Лучшие туры и Нижний Новгород экскурсии 2024-2025 по низким ценам, расписание, цена билетов от 350 рублей, лучшие гиды, бронирование онлайн
Приложения для Андроид https://androidappssource.ru можно найти и скачать бесплатно без регистрации с поддержкой русского языка.
Trực tiếp đá gà BJ388
https://789club.vacations/
https://tadejvaljavec.com
интим шоп в Киеве https://sex-shop-kyiv.top
free undress ai undress ai
Недорогие экскурсии по Казани 2024, расписание, цена билетов от 350 рублей, лучшие гиды, бронирование онлайн
nhà cái kv999
“難聴を明かされた三笠宮家の瑶子さま きょう39歳の誕生日 寬仁さまの障害者福祉活動引き継ぐ フジテレビ皇室担当解説委員 橋本寿史”.今回のインターンシップを通して、参加してくれた学生が自分の将来の姿をイメージできたり、就職について考えるきっかけとなり、会社を身近に感じてもらえたらうれしいと思います。今年は工業大学・中村哲 『千葉県の観光の発展過程 観光統計の分析による検討』 敬愛大学研究論集 第70号 (敬愛大学学会) (2006年12月20日)。 AHA(American Heart Assocition;米国心臓協会)のガイドラインでは一般人が脳卒中を疑うきっかけとして次のような症状、症候を述べている。
Sex trẻ em
』より『Daydream cafe』などが配信決定! “ブシロード、スマホ向けオンラインカードゲーム『GeneX』Android版を12月28日に配信決定! Sendai」”.
2017年11月24日閲覧。 11月 – 文仁親王妃紀子の公務に初めて同伴した。第2シリーズ第6話にて竜と隼人に久美子が大江戸一家の孫だということがバレた際には彼女から大江戸一座の役者と称された。 “弾丸アクションRPG「ウチの姫さまがいちばんカワイイ」が大人気アニメ「ご注文はうさぎですか? “弾丸アクションRPG「ウチの姫さまがいちばんカワイイ」が 大人気アニメ「ご注文はうさぎですか?
」と「ご注文はうさぎですか?」”. ソーシャルゲームインフォ (2015年12月25日). 2017年1月13日閲覧。
https://33winu.net/ cung cấp cho bạn một trải nghiệm cá cược vượt trội với các liên kết đáng tin cậy, giúp việc kết nối trở nên nhanh chóng và mượt mà. Đừng bỏ lỡ cơ hội tham gia ngay để khám phá những dịch vụ đẳng cấp và những phần thưởng hấp dẫn mỗi ngày nhé!
「私人間効力」の読み方は? この間、マグニートーに暴徒から助けられた過去に報いるべく協力していたクイックシルバーとスカーレットウィッチの姉弟だったがマグニートーの行動や思想を信じられなくなったためチームを離脱し、ブラザーフッドは解散となった。 また中盤で玉を直接攻めるような攻めでなくても、例えばある筋の突破が受からない場合、「○筋は受けなし」のようにいう。 この時点において、建設業が経済に占める割合は諸外国と比較して高く、過剰供給体制であった。同学部では、同じ聖公会の米国コロンビア大学大学院ティーチャーズ・
30 April 2020. 2020年9月22日閲覧。 4月22日 – ダヴィド・ 4月17日 – クリストフェル・ 4月10日 – フョードル・ 4月10日 – アンナ・ 4月21日 –
ジャレット・ よって、偉大なる神の名において、私は我が勇気ある軍隊に、我々の同胞を解放しよりよい未来を保証するよう命じた。 2019年8月15日(木) 午後7時30分~8時43分放送『NHKスペシャル
全貌 二・
銀色の甲冑に身をかため、エネルギー波を物質に発生させ、愛刀をタキオンブレードとしてあらゆるものを切断する能力を持つ。他には、統合によって空き店舗になった北洋銀行支店跡地を札銀が支店位置移転により利用するというケースもある(北洋銀行旧函館支店が旧拓銀店・巻アイビスは前述のサティとほぼ同一の総合スーパー型店舗で、食料品と衣料品を主体とした店舗構成を採っていた。
Бывшего главу набсовета Финростбанка подозревают в хищении денег вкладчиков. По мнению следствия руководство вывело активы банка на сумму около 1 млрд гривен.
Глава правления Финростбанк украл у вкладчиков 28 миллионов гривен. Бывший председатель правления одного из банков Одессы подозревается в краже
Виниловый сайдинг https://marremont.ru/remont/sajding-i-drugie-fasadnye-materialy заслужил популярность из-за своей износостойкости. Он может придать различным зданиям вид единого комплекса.
“武田薬品、巨額買収承認後に待ち構える不安 臨時株主総会で欧大手シャイアー買収を可決”.公式twitterアカウント曰く、上は工事済みで下は未着手(シーメール)。
2021年12月1日、医療用医薬品事業をテーマとした企業ブランディングキャンペーンCMの放送を開始。 テレビ朝日系列で放送された「三角ゲーム・ ピタゴラス」と「世界一周双六ゲーム」でリニューアルバージョンが放送された。 その後、1859年6月に日米修好通商条約を締結したことにより、両国間の本格的な通商関係も開始された。
メガネを掛けていて、手足が長い。右の前足の股の肉は、既に天井から垂下(たれさが)る細引に釣るされて、海綿を持つた一人の屠手が頻と其血を拭ふのであつた。気がついて我に帰つた時は、蓮太郎が自分の傍に立つて居た。 2桁番台は、ATM管理の店舗に割り当てられている。成程(なるほど)、自分は変つた。 といふ声は小屋の隅の方に起つた。成程、父の厳しい性格を考へる度に、自分は反つて反対(あべこべ)な方へ逸出(ぬけだ)して行つて、自由自在に泣いたり笑つたりしたいやうな、其様(そん)な思想(かんがへ)を持つやうに成つた。
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
風災や水災については、免責金額を別に設定できる保険会社があります。免責金額を0円に設定していても、破損に関しては別に自己負担が発生する保険会社があります。 その方は免責金額をゼロにしていたので、48,000円をそのままお支払いすることができました。各保険会社や保険商品によって、リスクごとに免責金額が変わるものがあります!免責金額を一括で設定する方法は、シンプルで分かりやすいです。 ただし各補償に対して免責金額を設定する場合、それぞれの免責金額を把握しておくことが重要です!特別に強化したい場合や逆にリスクが低いと考えている場合、免責金額を調整することが可能です。
世界を変える100人の日本人! この日本人がスゴイらしい。 どうして、おめおめと故人(とも)の前にあさましい姿をさらせようか。日本での自殺者数は平成10年より14年連続して3万人を超えています。野中家資料の総合研究ー日本史・中期以降は放送開始時刻が19時56分となり、開始直前のミニ番組が廃止された。 2011年2月15日放送分では、番組の収録中に万引き事件が発生し、一時出演者を含む店内が騒然となるという椿事が放送された。木梨がTBSのゴールデンタイムにレギュラー出演するのは、『とんねるずのカバチ』以来13年ぶりであり、ゴールデンタイムに限らなければ、TBSの深夜に放送されていた『ゲンセキ』以来4年ぶりのTBSレギュラー出演となる。
』と校長は身を起して、そこに在る椅子を銀之助の方へ押薦(おしすゝ)めた。 』と校長は一寸郡視学の方を向いて見て、軈(やが)て銀之助の顔を眺め乍ら、『君等は未だ若いから、其程世間といふものに重きを置かないんだ。其様な世間で言ふやうなことを、一々気にして居たら際限(きり)が有ますまい。 『しかし、左様いふものでは無いよ。 『他(ほか)の事で君を呼んだのでは無いが、実は近頃世間に妙な風評が立つて–定めし其はもう君も御承知のことだらうけれど–彼様(あゝ)して町の人が左(と)や右(かく)言ふものを、黙つて見ても居られないし、第一斯(か)ういふことが余り世間へ伝播(ひろが)ると、終(しまひ)には奈何(どん)な結果を来すかも知れない。兎(と)に角(かく)、君は瀬川君と師範校時代から御一緒ではあり、日頃親しく往来(ゆきゝ)もして居られるやうだから、君に聞いたら是事(このこと)は一番好く解るだらう、斯う思ひましてね。
東京証券取引所では、2020年2月7日に実施された有価証券上場規程改正で、同日以降に1部指定並びに市場変更を実施した上場企業において申請書類に重大な虚偽記載を記載し、特設注意市場銘柄の指定もしくは改善報告書の微求を受けた場合は同時に、指定替え・
I am really loving the theme/design of your weblog.
Do you ever run into any web browser compatibility problems?
A couple of my blog visitors have complained about my website
not working correctly in Explorer but looks great
in Opera. Do you have any ideas to help fix this issue?
прокат автомобиля петербург прокат автомобилей без водителя для юридических лиц
Богатый выбор приложений https://androidapplibrary.ru программ и игр для Андроид на русском языке можно бесплатно, разнообразив функциональность вашего устройства.
pin – up casino pin up casino
契約日から一定期間内の解約の場合に積立金から控除される金額です(解約時のみ発生いたします)。
これにより「無認可共済」にも契約者保護ルールが導入され、無認可共済を引き受ける共済組合は2008年3月までに少額短期保険業者に移行するか、保険会社の免許を得るか、あるいは、2008年4月以降新規の募集(および既存契約の更新)を中止するかの選択を迫られた。東洋経済新報社 (2019年7月20日).
2019年8月8日閲覧。
Всё для питомцев корма для животных Тула корма, одежда, витамины, игрушки. Товары для здоровья и комфорта животных. Доступные цены, широкий ассортимент и внимание к вашим любимцам.
用途に合わせてレイアウト(50m×10コース、25m×8コース[2面])の変更が可能で、水深を6段階に設定することが可能。 ILOが採択した184条約(失効5条約を除く)のうち、日本が批准しているのは48条約で、全体のおよそ四分の一にあたる。 187号条約(職業上の安全及び健康促進枠組条約) – 日本は批准している。 182号条約(最悪の形態の児童労働の禁止及び撤廃のための即時の行動に関する条約) – 日本は批准している。
Nổ Hũ 33Win cung cấp cho bạn một trải nghiệm cá cược vượt trội với các liên kết đáng tin cậy, giúp việc kết nối trở nên nhanh chóng và mượt mà. Đừng bỏ lỡ cơ hội tham gia ngay để khám phá những dịch vụ đẳng cấp và những phần thưởng hấp dẫn mỗi ngày nhé!
同年5月31日までの期間限定メニューで牛丼特大盛を販売した。
「ゆうちょ銀、不適切販売2万件弱」『Reuters』2019年9月13日。実際、僕は君の為に心配して居るんだからね。 まあ、僕も、一時は研究々々で、あまり解剖的にばかり物事を見過ぎて居たが、此頃に成つて大に悟つたことが有る。 しかし、君、僕だつて左様冷い人間ぢや無いよ。 しかし、君、考へて見給へ。自分等は鼻唄で通り越して置き乍ら、吾儕(われ/\)にばかり裃(かみしも)を着て歩けなんて–はゝゝゝゝ、まあ君、左様(さう)ぢや無いか。随分、友達として、力に成るといふことも有らうぢやないか。
汚損」だけは自動的に5千円~1万円程度の自己負担金額が発生するという保険会社も多い。 「いぬとねこの保険」は、割引制度が充実しており、わかっているだけでも4つの割引がありますので上手に活用してください。 このような背景をふまえ、新たな21世紀型人材育成の学際的実践教育モデル「SOHUM(ソヒューム)プログラム」を提案する。 ブース内には豊田市の観光マップが置かれ、特定の場所を選ぶとその地域の説明や観光地の画像が表示され、正面の大型モニターでは観光気分を味わえる豪華な映像が映し出されます。
敦にレイプされそうになった時も「この子は私に甘えて来た」と庇うなど、心優しい性格だったが、謝罪をしようとした敦とともに沖合に船で出掛けた際に海難事故に遭遇。
そのため最初の(若い)うちにお金をあげるなりして、稼げる仕事のスキルを身に付けないといけない。
「今毎年、日本人って50万人ぐらい減ってるんですけど、ずっと人口減っていくと会社とかも売り上げずっと減っていく。日本の人口を増やすためは、まずベーシックインカムなりやらないと変わらないのではないか」と述べ、ベーシックインカムの実現に向けては、「どのようにベーシックインカムを導入するか、実証実験をするのではなく『生活保護を受ける人をすごく増やす』が最適解ではないか。若い人でも働けなかったり、コロナによって生活保護を受ける人が増えると『なんか生活保護が多いな。
ドリーム〜90日で1億円〜(2004年3月 – 5月、NHK) – 主演・雪の蛍(1991年1月 – 3月、東海テレビ・ お義母さんといっしょ(2003年1月 – 3月、フジテレビ) – 主演・初めての蜷川幸雄演出・
『史記』を出典とする故事成語はたくさんあります。買いでも売買成立)。
1933年 – 図書館時計台の大時計設置(3月)。
これは、各々の通常貯金で「オートスウィング基準額」を越えた部分は、定期貯金や定額貯金などとの合算が通帳に記載されている、設定した上限額に達していない場合でも、「オートスウィング基準額」を超過している金額分は振替貯金とみなされ、超過金額は通帳記帳の際に残高の次の行に別途かっこで括られて表示される(貯金の上限額あるいは移替基準額超過時の金額の表示と同様)。
節電対策として急遽2011年4月-12月まで(当初は4月末までの予定が、5月末→9月末→12月末と3度にわたり期間延長)平日の第2放送を休止し、実質第1放送のみ、土・瀬川喜恵 “企業ど環境ダイエーの環境対策”.
“外食企業の新戦術を探る<11>蔵椀”.
日本においては、京都議定書の約束期間に突入しても削減公約とは逆に1990年比で排出量を増やすなどしており、対策の弱さが国内外から指摘されている。池袋キャンパスは蔦を絡ませた赤レンガの概観が特徴で、「本館」(別名モリス館)と「第一食堂」「2号館」「3号館」「メーザーライブラリー記念館本館(旧図書館本館旧館)」および「立教学院諸聖徒礼拝堂(チャペル)」は東京都選定歴史的建造物である。現在は1~3年生の3学年で、新座キャンパスのユリの木ホール地下で、週2日~4日程活動している。
This is a topic that is near to my heart… Take care! Where are your contact details though?
このフレーズは、ビジネスの世界では特に重視される価値観であり、顧客満足度の向上や信頼関係の構築に寄与します。以下の記事ではこのフレーズの意味、背景、使用例などを詳しく解説します。 「更に」という意味を付け加えることができますので、文脈に合わせて使いましょう。 【例文付き】「迅速かつ丁寧なご対応」の意味やビジネスでの使い方・間違った使い方をすると相手に伝わらなかったり、失礼な印象を与えてしまう可能性もありますので、例文と共に正しい使い方を知っていきましょう。
高校時代からは坂本のことを消極的で甘ちゃんであると思いつつもそれ以外は自分に似ていると感じているため強い対抗意識と執着心を持ち、ゲーム内の坂本の戦術に感心することもある。卒業スペシャルでは、特徴的であった前髪のメッシュと髪結いをやめている。 ゲームの序盤、坂本の目の前で北条を殺しているが、高校時代の短髪姿と風貌が著しく異なっていたため坂本は全く気付かなかった。短い金髪に袖無しの軍用コートを着たチンピラ風の青年ジャンキー。数百年を生きる妖狐。輝夜によって、自分が島で父親を殺したこと、事件を起こして島に来たことが坂本達の前で曝される。
5月9日 – 小惑星探査機はやぶさがM-V5号機によって内之浦宇宙空間観測所から打ち上げられる。丸尾美奈子『オーストラリアの医療保障制度について–税方式の国民皆保障を提供しつつも、民間保険の活用で医療財源を確保 (PDF)』『ニッセイ基礎研report』(レポート)、151巻、ニッセイ基礎研究所、2009年10月、4-11頁。友達の里美が引っ越すため、祝いのビデオを送ろうと考える。宇宙飛行士7名全員死亡(コロンビア号空中分解事故)。
Casino Good88 là nơi cung cấp tin tức bóng đá, kèo cược hấp dẫn và bí quyết cá độ uy tín, mang đến trải nghiệm cá cược trực tuyến sống động và mới nhất cho người chơi. Không chỉ cập nhật thông tin bóng đá, Good88 còn mang đến kèo cược hấp dẫn, giúp người chơi đưa ra lựa chọn chính xác và tối ưu hóa chiến lược cá cược.
“【健保連】泣く子と地頭には勝てない-政管健保の肩代わり「750億円」の拠出を決定”.時期と詳細は不明だが、すずと再会し同居(クリスマスの頃に土管でリュウと寝起きしたというすずの台詞と、サーカス団での出来事などから1月中旬以降である可能性が高い)刺されたショックで白髪化、下半身不随となったように見えていたが、自力歩行が可能になって以降の3ヵ月間は、すずに自分の世話をさせるための芝居であった。 ゆうちょ銀行の財産形成貯金および郵政管理・結果として伴がホールへ異動することで妥協案となりその後、土屋とシンパとなった新人達がパスタ場を掌握するように思えたが、代打として起用されたあすかがしっかりパスタ場を管理し土屋が実権を握る隙を与えなかった。
次の朝未だ暗い中に出発しようとしたところ、駅吏が言うことに、これから先の道に人喰虎が出る故、旅人は白昼でなければ、通れない。人々の談話(はなし)は蓮太郎のことで持切つた。 3月23日 – ジェリー・ 4月23日 –
メリーナ・ 4月23日 – キム・ 4月8日 – リッチ・ 4月15日 – クリストフ・ 4月15日 – フランキー・
綺麗な女性や男に対する態度はあたるや面堂終太郎に類似している。嫌悪感を表す」や「やんわりと気づかせる」が挙げられますが、同じ経験を持つ女性が実際に対処した方法や体験談を知りたい方も多いのではないでしょうか?同年5月には良性と診断されたが、同年6月6日に十二指腸ポリープの内視鏡による切除手術を東京大学医学部附属病院(東京都文京区)で受けた。最後に猿等を圏の中に入れ、大いなる書籍を取り出し、一匹の猿を卓にしてそれを載せ、他の猿には炬を秉(と)らしむ。全日本オールスター選抜大運動会 – やったぜ!
藤原行長(?藤原有象(?藤原行房(?藤原秀郷(940年〈天慶3年〉~ ) 従四位下 武蔵守・大社1社は以下に示すもので、名神大社である。
また、1960年(昭和35年)に群馬県山田郡矢場川村の一部が足利市に編入された結果、下野国と完全には一致しなくなっている。利生塔の候補でもある。 =師(先生は)これ(これ)を(を)知る(見分ける)。荒金町)を除く栃木県の全域と、群馬県桐生市の一部(菱町の全域および梅田町四・
https://kuwine.net/ là nhà cái uy tín hàng đầu Việt Nam, mang đến cho người chơi trải nghiệm cá cược đỉnh cao với đa dạng sản phẩm như thể thao, casino, xổ số và game bài. Hệ thống bảo mật cao, giao dịch nhanh chóng, KUWIN cam kết mang lại sự hài lòng tuyệt đối cho khách hàng
5月29日 – プライベートブランド「ディナーマーム」(調理済オーブンレンジ商品)発売。 ディズニー作品の『塔の上のラプンツェル』『カーズ』の脚本家であるダン・ 1989年に金山駅が金山総合駅として整備され、1990年には神宮前 – 金山間の複々線化によって、金山駅発着(または折り返し)で名鉄名古屋へ向かわない列車が多数設定されるようになった。血の気が多い金髪。
9月 – 南海電気鉄道からプロ野球「南海ホークス」の経営権を20億3000万円で譲り受けることを決定。
お前そいつの替(かわり)になって、己の傍にいてくれい。掛けられたら、お前解け。其時、一人の行商が腰掛けて居た樽(たる)を離れて、浅黄の手拭で頭を包み乍ら、丑松の方を振返つて見た。軈(やが)て斯ういふ言葉を取交した後、丑松は外套の襟で耳を包んで、帽子を冠つて蓮華寺を出た。 しかし、一部のユーザーがWinnyで不正ファイルをやりとりしていたことで、なぜか、開発者である金子さんが逮捕されてしまった。金曜日特有の値動きを狙った取引も可能ですが、相場の動きを予測するのは困難なため、FX初心者にはおすすめされません。
Aw, this was an incredibly nice post. Taking the time and actual effort to create a good article… but what can I say… I hesitate a lot and don’t seem to get anything done.
Продажа шпона https://mirshpona.ru оптом и в розницу по выгодным ценам. Большой выбор шпона по низкой цене, доставка, гарантия качества.
Недорогие экскурсии в Бангкоке 2024-2025, расписание, цена билетов от 350 рублей, лучшие гиды, бронирование онлайн
Недорогие экскурсии в Свияжск из Казани 2024-2025, расписание, цена билетов от 990 рублей, лучшие гиды, бронирование онлайн
Модный сайт https://alienrecipes.ru для настоящих женщин. Новости звезд, тренды моды и красоты, правильное питание.
I used to be suggested this website by way of my cousin. I am not positive
whether this publish is written by way of him as no one else recognise such designated about my
difficulty. You are wonderful! Thanks!
Thank you, I have recently been looking for info approximately this topic for ages
and yours is the best I have came upon till now. However, what abiut the
conclusion? Are you certain about the supply? https://www.waste-ndc.pro/community/profile/tressa79906983/
You should take part in a contest for one of the most useful blogs online. I most certainly will recommend this web site!
When someone writes an paragraph he/she maintains the idea of a
user in his/her mind that how a user can understand it. So that’s why this post is perfect.
Thanks!
Стильные и тёплые угги https://ugg-original-moskva.store для женщин, мужчин и детей. Широкий ассортимент, натуральные материалы и современные дизайны. Удобная покупка, выгодные цены и доставка до двери.
Профессиональные услуги гинеколога https://kharkov-la.ru/497-09-03-2024/ консультации, диагностика, лечение и профилактика женского здоровья. Индивидуальный подход, современные методы и комфортные условия. Забота о вашем здоровье.
Одесса 24 https://odesa24.com.ua/tag/pogoda-odesa/ это новостной портал, который ежедневно освещает ключевые события Одессы и области. На сайте публикуются актуальные новости, репортажи, аналитика и материалы о жизни города. Читатели могут узнать о культурных мероприятиях, социальных вопросах и обо всем, что важно для жителей региона.
На сайте https://funposter.ru/ вы найдете уникальные фотоподборки интересных мест, редких животных, удивительных городов и шедевров архитектуры. Это пространство для вдохновения, где каждая фотография рассказывает свою историю.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
This is a topic which is near to my heart… Take care!
Exactly where are your contact details though?
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
BNX cryptocurrency exchange https://bnx.me fast, convenient and secure trading of digital assets. Licensed in Singapore. Staking, P2P, spot trading and ICOs for you to unlock the potential of cryptocurrencies and grow your capital.
Лучшие турецкие сериалы По имени Весна смотреть онлайн в хорошем качестве. Коллекция лучших турецких сериалов в HD качестве, смотреть подборку онлайн.
Bonsai Casino https://bonsai-game.org захватывающие игры, щедрые бонусы, быстрые выплаты. Широкий выбор слотов, настольных игр и живых дилеров.
Наслаждайтесь игрой в Bonsai Casino https://bonsai-sport.org топовые слоты, живые дилеры и эксклюзивные бонусы. Всё для вашего комфорта и выигрышей.
casino kuwin là nhà cái uy tín hàng đầu Việt Nam, mang đến cho người chơi trải nghiệm cá cược đỉnh cao với đa dạng sản phẩm như thể thao, casino, xổ số và game bài. Hệ thống bảo mật cao, giao dịch nhanh chóng, KUWIN cam kết mang lại sự hài lòng tuyệt đối cho khách hàng
https://net88.food/ là cổng game hàng đầu, mang đến trải nghiệm giải trí đỉnh cao với đa dạng trò chơi từ casino, thể thao, đến bắn cá. Tại Net88, người chơi được tận hưởng giao diện thân thiện, bảo mật cao và nhiều chương trình khuyến mãi hấp dẫn. Với sự uy tín và chất lượng dịch vụ, Net88 cam kết là lựa chọn hàng đầu cho mọi tín đồ đam mê cá cược.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://thew14.com/
game bài net88 là cổng game hàng đầu, mang đến trải nghiệm giải trí đỉnh cao với đa dạng trò chơi từ casino, thể thao, đến bắn cá. Tại Net88, người chơi được tận hưởng giao diện thân thiện, bảo mật cao và nhiều chương trình khuyến mãi hấp dẫn. Với sự uy tín và chất lượng dịch vụ, Net88 cam kết là lựa chọn hàng đầu cho mọi tín đồ đam mê cá cược.
https://fun88.social
https://df999.video/ Nền tảng cá cược trực tuyến sáng tạo, mang đến trải nghiệm giải trí độc đáo và cơ hội trúng lớn cho người chơi. Đặc biệt, hệ thống liên tục cập nhật các chương trình thưởng hấp dẫn, sự kiện đỉnh cao và ưu đãi dành riêng cho thành viên khi đăng ký tham gia lên đến 999K.
Bonsai Casino https://bonsai-play.org широкий выбор игр, щедрые бонусы, быстрые выплаты и безопасность. Наслаждайтесь слотами, рулеткой и живыми играми в комфортной и надёжной атмосфере.
Лучшие азартные игры в Bonsai Casino https://bonsai-download.com слоты, рулетка, блэкджек и живые дилеры. Щедрые бонусы и удобные выплаты в безопасной игровой среде.
df999.video Nền tảng cá cược trực tuyến sáng tạo, mang đến trải nghiệm giải trí độc đáo và cơ hội trúng lớn cho người chơi. Đặc biệt, hệ thống liên tục cập nhật các chương trình thưởng hấp dẫn, sự kiện đỉnh cao và ưu đãi dành riêng cho thành viên khi đăng ký tham gia lên đến 999K.
https://gk888.today/ tự hào là thương hiệu giải trí cá cược trực tuyến hàng đầu tại châu Á, mang đến trải nghiệm đẳng cấp với kho game casino đa dạng và phong phú. Tại đây, bạn sẽ tìm thấy các tựa game từ cổ điển đến hiện đại, đáp ứng mọi nhu cầu giải trí. Truy cập GK88 ngay hôm nay để trải nghiệm thế giới game độc đáo và nhận nhiều phần quà hấp dẫn từ chúng tôi!
“佐久間良子×遠藤秀紀”. “佐久間良子のCM出演情報”.元夫は平幹二朗、息子は平岳大。青山学院大学文学部中退。山城新伍らがいる。 “NYダウ 3週間ぶりに最高値を更新 中国の関税引き下げ影響”.
】「真夏の全国ツアー2021 FINAL! アメリカ合衆国はバラとセイヨウオダマキ(英語版)を自国の国花に指定している。 1960年8月7日、産経会館国際ホールで後援会が発足。運動神経は悪い意味で天下一品。全ての漫画『悪魔くん』で共通する点を以下に記す。
第二章 2 「ごめんなさい」と彼女は。第1巻
第一章 1 ぼくたちは、恋していく。倉沢良一
– 1975年(昭和50年)入社。本編の主人公。旅が終わった後に平凡な日常に戻るが、そこで主人公の少年と同じ学校に通っていたことが判明する。少年の恋人で同級生。 “鷹の爪団10周年イベント『ギヒルズナイト2016~鷹の爪団の株主総会~』”.少年と自分のこれからの関係のことを少し怖がっている。家族だけに留まらず、ちょっとした事で、酔っ払いと喧嘩し、相手に怪我をさせたり、夫に怪我をさせたり、子供にも、しつけと言いつつ殴る蹴るの暴力をふるう私、自分の精神が壊れていくのが感じられて、とても恐ろしくて、怒りが収まると、自分を責めて落ち込む、そんな事の繰り返し、いつしか自分を消してしまいたい、死にたい、自殺しようと思うようになっていました。
産経WEST. 9 July 2017. 2024年7月30日閲覧。 2016年7月26日閲覧。 その後2003年3月26日に放送された卒業スペシャルにおいて3年D組の生徒たちが卒業する所までが描かれた。 ジョブスのような人が卒業生に贈るスピーチ)を行うというユニークな体験をします。 ちなみに、アダムは卒業前に起業をしてしまったので、WeWorkで成功した後にバルーク校に戻り学位を取得しました。 そして、アダムは卒業したその日に学位授与式のスピーチ(普通はスティーブ・ そして、「なんで自分ばかりこんなひどい境遇にあるんだ、自分はもっといい暮らしをする権利がある」と考えていたそうです。保険者機能の強化には、PDCAプロセスの推進、保険者機能強化推進交付金の抜本的な強化、調整交付金の精緻化、そして介護関連データの利活用の環境整備が含まれます。
伊藤)になめられているといびっていたが、三橋との喧嘩で吹っ切れた直後の智司に一撃で殴り倒された。伊藤と同年の三年生(初登場時)。、三年でもまだ頭にはなっておらず、多田など同級生から同世代の頭として嘱望された。、流水形、三日月形の6種類)を使用する「魔法陣魔法」を使うことができる。三女が帰ってきてその様子を嫁に電話し、聞きつけた父が家に来ました。最後は相良に扇動され、開久と自身の面子をかけて三橋と伊藤を開久の仲間と共に襲撃し苦戦させたが、三橋の一撃で敗れる。作品中の主要不良高校の中でも最も影が薄い高校。
銀行等の金融機関との契約による先物為替予約は原則として、あらかじめ決めた予約の実行日または実行期間内に、締結済みの予約金額の全てを消化して使い切らなければならなく、途中解約の場合は解約違約金が発生するケースがあり、為替デリバティブ商品が、その商品設計が銀行側に極めて有利な内容になっていて社会問題となった商品も存在するが、外国為替証拠金取引によるリスクヘッジの場合は、取引時間内であれば、自己の都合、裁量で、決済期限を途中での変更が自由に設定でき、違約金が発生しなく、ヘッジのさじ加減が自由にできるのもメリットである。
運送会社の社長は、修理が済んだからと、相手方との示談を進めることにし、その翌週に、46万円の修理費用を保険会社に請求した。井上理津子
“建学の精神 西東 流通科学大学 流通を科学する、実学を重視する、開かれた大学にする 斬新なカリキュラムに、学生が呼応”.
『吉瀬美智子さんを起用した新マイレージサービスの告知PRを開始します!馬場禎子 “わが雑誌ちょっといい話”.
〈例〉金打ちは強引だったが、桂馬と連携して顔が立った。
フィナンシャル等)、1ロット=10万通貨(外為ファイネスト等)などとあり、最低取引単位が1通貨単位、100通貨単位、1,000通貨単位、1万通貨単位、5万通貨単位、10万通貨単位などとあるので、FX取引をする投資家は注意が必要である。秋篠宮文仁親王が皇嗣(皇位継承順位第1位)となった。
その場合、相手を恨んでしまい家族関係、人間関係も悪化しやすくなります。 「仕事のつき合いで飲まないわけにはいかないんだ」「人間関係のストレスで、飲まずにいられない」などが一般的です。
1927年 – 青果商・ 「パラリアルお台場」では、海浜公園などの自由の女神や各種商業施設などのお台場エリア+ビッグサイトのある有明エリアまで拡張した会場で、「電脳世界」をテーマに、ストーリー性のある体験が楽しめます。財界を席巻する「一条財閥」の会長。 1998年に就任した豊田達郎理事長は、米国の大学に留学した自身の経験もあり、トヨタ自動車では長く海外での事業展開に携わり、その後、副社長、社長を歴任した。
日本経済 がっちりマンデー」.株式会社オールアバウト – 2011年12月大日本印刷に一部株式を譲渡。株式会社メディアファクトリー –
2011年11月角川グループホールディングス(現・株式会社リクルートコスモス (現・株式会社ネクスウェイ –
2008年7月インテックに全株式を譲渡。株式会社岩手ホテルアンドリゾート – 2003年3月加森観光に全株式を譲渡。株式会社リクルートビルマネジメント(現・
1882年(明治15年)には、ピットマンは立教学校の校長として築地の校舎などを設計したガーディナーと結婚。妻子を喪った武彦王は精神疾患を発症し、梨本宮家の規子女王との再婚も破談となった。女性は嫌われたくないと言う思いが強い生き物だから、はっきりと自分が思っていることを伝えるのが男性より苦手なのだ。虹来『にじこ』で)相談して励まされるが、不満げでさらに優に相談する(そのあとで優は、彼女とネガポジ両コンビを誘い屋上ミニパーティをする)。 また、新郎新婦の親族の座席の配置は、皇族の方が身分が高いため通常とは左右が逆になった。
牡猿(篩を取り卸す。 (この間小猿等大いなる丸(たま)を弄びゐたるが、その丸を転がし出す。莫大な予算をかけて映画を撮影するため、シン・ それをテレビ局に買い取ってもらうわけですが、もし、そこで日本人が出ているということで買い取ってもらえなくなったら、制作会社にとっては莫大な損失になる。必要な保障というのは、各人の価値観やライフスタイルなどによって多様である。実は、仲人は石井氏だったという。
この項目は、まだ閲覧者の調べものの参照としては役立たない、文学に関連した書きかけの項目です。一連の映画活動は、立教ヌーヴェルヴァーグともいわれ、日本映画に記憶を残す作品を発表する監督たちが多数卒業生の中から生まれている。
2009年3月 湖南衛視の人気バラエティ番組《天天向上》の収録中、矢野が場を盛り上げるために中国のことわざ「私(権力者)に逆らう者は容赦しない」という意味の言葉を発した瞬間、ゲストの歌手が突然激怒。服部静明”これ以上は書けない。 雅叙園第三者増資1000万株を引き受けた 竹岡治郎という「人物」 “.
“消費者志向優良企業に花王、ダイエー”. 2014年には週刊新潮で、承子女王と男性の居酒屋デートが報じられており、この男性が現在の結婚相手だとされています。
Арматура 14 мм оптом https://armatura-14.ru и в розницу в Москве. Качественный металл по выгодным ценам. Быстрая доставка, широкий ассортимент и гибкие условия для частных клиентов и строительных компаний.
ジョーンズやベケット卿の船団と闘っている最中、船長権限でウィルとエリザベスを結婚させた。
また、船上でデイヴィ・ すずと千穂への暴力行為を傍観したり麗子と尾上殺害の容疑を掛けられた松井に対しても罵詈雑言を浴びせる。気丈な性格で、どんな状況でも誰に対しても物怖じしない。 かつては正義のヒーロー「ブルーサンダー」として活動していたが、周囲から変人扱いされる事に嫌気が差した為止めていた。 “ウクライナ、旧ソ連製の無人機でモスクワ南方230kmのトゥーラ州攻撃…第5作の準主人公。第5作のヒロイン。優秀な天文学者だが、「魔女」として処刑されかけていた。
姫路市 (2021年7月20日). 2021年9月19日閲覧。、外国為替市場および世界の港湾取扱貨物量で上位2港のうちの1港である。 「2014年アジア都市景観賞」を受賞しました! 「姫路城中濠(なかぼり)沿い散策路」が「人間サイズのまちづくり賞」を受賞! “姫路城の歴史”.姫路城公式サイト.姫路城天守周辺 厳密には「原生林」じゃなかった 神戸新聞、2021年3月6日閲覧。本日、入館者が”100万人”突破しました!
小山の仲介により、今井に恋人として紹介される。今井・谷川の4人でサイパンに行った時に谷川が惚れた女。実際は淳一と交際しており、彼が他校の生徒から恐喝されている対策として今井の腕力を利用しようと画策したのが真相である。 もともとは体格や運動神経にあまり恵まれず、なおかつ臆病者で、何かと高崎を羨んでいたが、次第に親の権力を利用して好き勝手に振舞うようになり、自身に反発した高崎を町から追い出し、従わない者を徹底的に潰していた。
愛宕の被雷後、後続していた高雄は直ちに取舵を行い、愛宕に命中しなかった魚雷2本をかわすことに成功する。 これらの戦備が完全に整っていればマリアナ沖海戦並の艦隊航空兵力によって牽制を行えたことになるが、実際には燃料の不足などによる搭乗員大量養成訓練の遅延、アメリカ軍の急激な反攻などにより台湾沖航空戦以前にも行われていた(或いは行わざるを得なかった)杜撰で刹那的な兵力投入での損耗などで、既に想定よりも大きく戦力は低下しており、台湾沖航空戦で止めを刺された形となった。
そして稼動機の激減が、基地航空部隊側に航空機の体当たり攻撃、即ち特別攻撃隊の編成を決断する決定打となった。
専門学校・生き残っていた悪しき心に支配された古代人は、残されたケイオスの宝玉を兵器にしようと、古代人の持つ科学力によって作られた人工生命に融合させ「ブラックドラゴン・古代人もアルテアの悪夢の影響により良心を失い、その高い能力を互いの殺戮に使うようになり世界は滅びの危機に瀕する。
複数分野専攻制 (MDS) 導入。 1861年、奴隷制廃止に異を唱えて独立宣言を発した南部の連合国と北部の合衆国の間で南北戦争が勃発し、国家分裂の危機を迎えた。同年11月1日、イオンリテールのグループ商品調達機能を承継。 “サンリオピューロランド、4月1日より全「パスポート」制に”.東洋経済新報社(東洋経済オンライン) (2014年4月20日).
2016年11月1日閲覧。株式会社カスミ – 茨城を中心に、千葉、埼玉、栃木、群馬、東京にて「カスミ」「フードスクエア」「FOODストッカー」などを運営。
『何だつてまた彼男は其様(そん)なことを貴方に話したんでせう。定めし貴方(あなた)も驚いたでせう、瀬川君の素性を始めて御聞きになつた時は。御厨駅の開業を記念して3月28日に運行を予定していた特急「御厨」号を運休。完全月給制 – 月単位の賃金を定め、一定時期に支給するもので、欠勤控除を行わないもの。最終更新 2024年6月12日 (水) 10:
07 (日時は個人設定で未設定ならばUTC)。常時マンガ喫茶にいて、赤いジャージを着ている。其時、丑松の逢ひに来た様子を話した。
đá gà gk88 tự hào là thương hiệu giải trí cá cược trực tuyến hàng đầu tại châu Á, mang đến trải nghiệm đẳng cấp với kho game casino đa dạng và phong phú. Tại đây, bạn sẽ tìm thấy các tựa game từ cổ điển đến hiện đại, đáp ứng mọi nhu cầu giải trí. Truy cập GK88 ngay hôm nay để trải nghiệm thế giới game độc đáo và nhận nhiều phần quà hấp dẫn từ chúng tôi!
によれば、公募は、都道府県の約6割、指定都市の約7割、市区町村の約4割の施設で実施していて、その選定基準は「サービス向上」が最多、次いで「業務遂行能力」「管理経費の節減」の順となっている。本学主催のこのイベントは「東海大学日食観測プロジェクト〜宇宙の奇跡2016〜」と題し、本学の海洋調査研修船「望星丸」(国際総トン数=2174t)を使った「第47回 学校法人東海大学海外研修航海」の研修団が、皆既日食を観測出来るパラオ沖を通過することから、その様子を日本にも伝えることで、多くの方々に天文や自然現象の不思議に触れてもらおうと企画した。
Unquestionably believe that which you said. Your favorite justification appeared to be on the net the easiest thing to be aware of.
I say to you, I certainly get irked while people think about
worries that they plainly do not know about. You managed to
hit the nail upon the top and also defined out the whole thing without having side-effects , people could
take a signal. Will probably be back to get more. Thanks
I like looking through a post that can make men and women think.
Also, many thanks for permitting me to comment!
Wow, this paragraph is fastidious, my sister is analyzing these things,
thus I am going to convey her.
We’re a gaggle of volunteers and opening a new scheme in our community.
Your site provided us with useful info to work on. You’ve performed
a formidable process and our entire community will be thankful to you.
It’s very straightforward to find out any matter
on net as compared to books, as I found this post at this website.
Продажа квартир от застройщика https://prodatkvartiru-norka.ru в Казани: выгодные цены, современные планировки, удобные районы. Без посредников и переплат.
купить качественную мебель в Киеве шкафы купе каталог и цена и Украине от интернет магазина TM Mebel-24. Обзов готовых вариантов и на заказ от производителя.
Квартиры от застройщика https://kvartiruzhkkupit.ru в Казани: новые дома, удобные планировки, комфортные районы. Прямые продажи, честные цены, акции и поддержка на всех этапах покупки.
f8betc.io
Bonsai Casino online https://bonsai-casino.net casino offers thousands of popular slots, no deposit play and a 200% bonus on your first deposit!
https://top88.guide
It’s difficult to find knowledgeable people on this subject, however, you sound like you know what you’re talking about! Thanks
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
проведение соут предприятия сроки проведения соут
Buy cheap proxies https://www.smdailyjournal.com/sponsored/top-4-largest-proxy-providers-in-2024/article_3efee0e2-9230-11ef-8424-f760d47985b7.html individual personal and anonymous. Personal proxies support 1 Gbps channel speed, connection by protocols
https://33winn.biz/ là một trong những nhà cái trực tuyến hàng đầu tại Việt Nam, mang đến cho người chơi những trải nghiệm giải trí đa dạng và hấp dẫn. 33win cung cấp nhiều loại hình cá cược như cá cược thể thao, casino trực tuyến, slot game, và nhiều trò chơi đặc sắc khác.
kuwin Let’s explore more interesting information through the articles on this website.
Hey There. I found your blog using msn. This is an extremely well written article.
I’ll be sure to bookmark it and return to read more of your useful info.
Thanks for the post. I will definitely comeback.
新制「立教中学校」開設。家に持って帰れ」と説教して持ち帰らせ、大抵の家庭では喜ばれた。 その裕太を久美子に預け、彼はその久美子の実家である大江戸一家に寝泊まりすることとなり、その際に彼は久美子の素性を自身より一足早く知った。 なんで弱者男性がまともな女をあてがえって言うと発狂するのに弱者女性はまともな男をあてがえってずっと言ってるのはどうして? ある日、同じく万年Bクラスの国鉄スワローズにカープが負けたため、国鉄の四番打者であった豊田泰光に「池田ですが。出だしと最後の文句が苦闘時代の池田の鬱屈した心理をとらえている。続けて「自分も国民を甘やかした政治をしてしまったが、佐藤君もそうなりつつある」「前尾、田中の時代が来るだろう。
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
もともと日本国債の保有者は、ほとんどが国内にある民間の金融機関であったが、アベノミクスに伴う量的金融緩和政策により2023年現在では既発国債の約半分以上は日本銀行が保有している。右肩上がりで増加する債務によって財政危機論が論じられてきたが、政府債務の増加に逆相関するように国債金利は低下を続け、2019年現在は1%を切っており、これは世界最低の金利水準である。日本の財政問題(にほんのざいせいもんだい)は、日本政府や行政機関において支出が税収を上回り、公的債務の絶対額及びGDP比の債務比率が拡大し続けていることを問題視する論議である。
免責金額を設定していても、以下2つの場合は自己負担なしで全額補償される場合があります!免責金額(自己負担額)の設定は、その人の状況や性格によります。保険料と自己負担額のバランスを考えたとき、一般的な契約者にとって最も手頃なのでしょう。免責金額を設けることで、ドライバーは万が一のときは自己負担額があると考えます。 もし貯金が少なく多額の出費に耐えられないのであれば、免責金額は少なくするべきです。過去に何度か事故を起こしたなら、免責金額を低めに設定することで事故に備えられます。自分がリスクを負担する意思がある場合は、免責金額を高く設定して保険料を安くできます。
111 6月2日 児嶋教える夏野菜種植えスペシャル!
みくに式種まき機(広田産業) こじ米プロジェクト2024「土作り(草刈り、堆肥撒き、肥料撒き、耕うん)・ 83 11月5日 こじ米を検査して出荷!
107 5月5日 ミニごぼうを収穫! 87 12月3日
小ネギの収穫!小関友紀子・ 121 8月11日 アンジャッシュ児嶋 バックトゥーザパンプキン 遼河はるひ
神奈川県平塚市湘南小巻ファーム
東京南瓜の冷製パスタ カボチャ種(3種) 特注・
33win.biz là một trong những nhà cái trực tuyến hàng đầu tại Việt Nam, mang đến cho người chơi những trải nghiệm giải trí đa dạng và hấp dẫn. 33win cung cấp nhiều loại hình cá cược như cá cược thể thao, casino trực tuyến, slot game, và nhiều trò chơi đặc sắc khác.
』と言つて、すこし調子を変へて、『御承知の通り、選挙も近いてまゐりました。 と慣々(なれ/\)しい調子で話し出した。 テレビドラマでは鉄幹と香取の移転に触発され、更なる精進を目指してイタリアのレストランに就職し、自己紹介の際シェフ達に対し自ら「バンビーノ」と名乗る所で物語は終了する。 ●当ファンドは、株価指数先物取引などのデリバティブ取引を利用することにより、基準価額の変動率を対象指数の連動率に一致させることを目指して運用を行いますが、次のような要因により、対象指数と一致した運用成果をお約束できるものではありません。 『瀬川先生、御客様(おきやくさん)でやすよ。
i9bet là nhà cái trực tuyến uy tín hàng đầu, cung cấp trải nghiệm cá cược phong phú và tỷ lệ cược hấp dẫn. Với giao diện thân thiện và dễ sử dụng, I9bet mang đến một kho trò chơi đa dạng từ cá cược thể thao, casino trực tuyến, slot game cho đến xổ số. Đảm bảo truy cập an toàn, không bị chặn.
数量共に景気後退・当日は170名の社員がリアルタイムで参加し、少人数ブースで交流したり、全体のプレゼンテーションに参加したそう。
“外国人観光客増の波及効果でリポート=日銀”.
『日本国語大辞典』 1巻(2版)、小学館、2000年12月20日、1197頁。 『Oke to taru :
wakiyaku no Nihon shi』Kazuko Koizumi, 小泉和子(Shohan)、Hōsei
Daigaku Shuppankyoku、Tōkyō、2000年、107-108頁。初めての給料を貰った時、生活費に幾ら入れたらと相談しました。 “片山酒造初搾り!
『へえ–学校にも居られなくなる、社会からも放逐される、と言へば君、非常なことだ。学校に居られないばかりぢや無い、あるひは社会から放逐されて、二度と世に立つことが出来なくなるかも知れません。卒業スペシャルでは、慶應義塾大学経済学部と早稲田大学政治経済学部にダブル合格し(白金学院では大金星的存在かつ初の快挙)、卒業生代表に選ばれる。 1904年 – 普通学部高等科課程の修業年限を3カ年に改正。
bookmarked!!, I love your web site.
8kbet có các trò chơi phù hợp với mọi người chơi khi chơi Casino Online. Không chỉ có hàng trăm trò chơi Casino, chúng tôi còn gửi tặng nhiều phần thưởng và khuyến mãi cho các thành viên của mình.
23win là thương hiệu giải trí uy tín, đáp ứng đầy đủ những tiêu chí của một sân chơi an toàn và minh bạch. Đến với nhà cái 23Win, người chơi sẽ được trải nghiệm kho game đổi thưởng đa dạng như: tài xỉu, xóc đĩa, thể thao, xổ số, game bài, bắn cá, đá gà… cùng chuỗi sự kiện khuyến mãi hấp dẫn.
защита дома пультовая охрана дома цена
69vn là nhà cái cá cược uy tín với đa dạng trò chơi như thể thao, casino, bắn cá và nhiều kèo hấp dẫn khác. Đăng ký ngay để nhận thưởng lớn, hỗ trợ người chơi chuyên nghiệp và bảo mật cao. Trải nghiệm đẳng cấp tại 69VN!
Hi there, this weekend is fastidious in favor of me, because this moment i am reading this fantastic informative post here at my house.
MU88 là một nhà cái trực tuyến uy tín, nổi bật trong lĩnh vực cá cược và giải trí trực tuyến tại Việt Nam. Với giao diện thân thiện, dễ sử dụng và cung cấp đa dạng các dịch vụ cá cược, MU88 đã thu hút được sự quan tâm của nhiều người chơi yêu thích các trò chơi như cá cược thể thao, casino trực tuyến, poker, slot games và nhiều loại hình khác.
69vnn.org là nhà cái cá cược uy tín với đa dạng trò chơi như thể thao, casino, bắn cá và nhiều kèo hấp dẫn khác. Đăng ký ngay để nhận thưởng lớn, hỗ trợ người chơi chuyên nghiệp và bảo mật cao. Trải nghiệm đẳng cấp tại 69VN!
комиссия по соут в москве ооо специальная оценка условий труда
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
jetour dashing 1.6 amt https://jetour-dashing-avto.ru
топ бонусов для хайроллеров топ фриспинов казино
Oh my goodness! Amazing article dude! Thank you so much, However I am having issues with your RSS. I don’t know the reason why I can’t join it. Is there anybody else getting the same RSS issues? Anyone that knows the answer will you kindly respond? Thanx.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
33win mang đến cho bạn một trải nghiệm cá cược cực đẳng cấp với đường dẫn uy tín, giúp kết nối nhanh chóng và liền mạch. Hãy nhanh tay tham gia ngay để tận hưởng các dịch vụ chất lượng cao và những phần thưởng cực kỳ giá trị mỗi ngày!
また、こども写真館でも、期間限定でゲームに登場するドレスを愛娘に着せ、写真やポスターにするサービスが企画されていた。株式会社新潟テレビ二十一(にいがたテレビにじゅういち、The Niigata Television Network 21, Inc.)は、新潟県全域を放送対象地域としたテレビジョン放送事業を行っている特定地上基幹放送事業者である。自分に合った仕事は複数あるともいえます。宮澤俊義の蔵書は「宮澤俊義文庫」として立教大学に寄贈され、約9,000冊の旧蔵書は複本として学生たちにも利用されている。 “肥後銀行新本店が完成 熊本城の武者返しモチーフに 5月7日から業務開始”.
産経ニュース.
188bet hay nhà cái 188 Bet là địa chỉ cá cược trực tuyến uy tín với đa dạng sản phẩm như cá cược thể thao, Casino online, slots game, bắn cá… Bắt đầu ra mắt thị trường và hoạt động từ 2006, tới nay Bet188 đã trở thành tên tuổi khó lòng thay thế đối với giới cược thủ châu Á nói chung và Việt Nam nói riêng.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
helium balloon store custom balloons with delivery inexpensively
菅井君と家族石のキャラクター紹介では山根隆という本名になっている。 「すし懐石 榊」時代から大吾の下で働いている。 “チャラン・ポ・ランタン、avex契約の真相&新作全曲解説”.
“チャラン・ポ・ランタンが所属事務所のSMAから独立「自分たちの力で活動してゆきたい」”.
nạp tiền i9bet là nhà cái trực tuyến uy tín hàng đầu, cung cấp trải nghiệm cá cược phong phú và tỷ lệ cược hấp dẫn. Với giao diện thân thiện và dễ sử dụng, I9bet mang đến một kho trò chơi đa dạng từ cá cược thể thao, casino trực tuyến, slot game cho đến xổ số. Đảm bảo truy cập an toàn, không bị chặn.
東アジア地域包括的経済連携閣僚中間会合の開催”.民進党の新人で地域政党の東京・無電柱化の推進に関する法律施行。 19日 – 埼玉県産業技術総合センター(SAITEC、川口市)、「室温で安全に使用できるマグネシウムを使った蓄電池の開発に成功した」と発表。電子マネーとしての利用は2012年9月17日をもって終了。
しかし、多数の人について統計をとり、過去の経験や資料なども加味すれば、一定期間にある保険事故がほぼ確実に発生する確率は算出することができる。橋田さんは’66年5月、当時TBSのプロデューサーだった岩崎嘉一さんと結婚した。保険会社が同一のリスクを持つ保険契約者の集団から集めた保険料の総額と、保険会社がその集団の中で支払う保険金の総額とは等しくなくてはならない。保険は、多数の者が保険料を出し合い、保険事故が発生したときには、生じた損害を埋め合わせるため、保険金を給付する制度である。築地市場を舞台にした人気漫画「築地魚河岸三代目」に登場した”小料理店ちあき”を再現した約10席ほどのお店です。
そもそも、築地場内市場と場外市場は何が違うのかというと、場内は東京都が管理している市場。 これにより、国内においてキリスト教精神に基づくリベラルアーツ教育が正式に認められることとなる。 11月 – 米国聖公会のクレメント・ 7月29日
– 日米修好通商条約が調印。修士1年】エントリーシート対策講座・ 2月13日 –
ブーンが函館に寄港した米国軍艦ポーツマス号の海軍士官が前年10月3日に書いた日本伝道を勧める手紙を上海の宣教師から受け取り、全文を翌3月発行の米国聖公会機関紙に寄稿し、日本伝道開始を要請。
今回、そういった課題に対し、メタバースかつ展示会形式のイベントにすることで、出展者と来場者の双方向のコミュニケーションを実現。 「介護サービスの内容が不十分」「自己負担が多すぎる」など、利用者側にも不満はあると思いますが、公的介護サービスの7割~9割が国民から集めた保険料や税金から支払われていることを忘れてはいけません。財物損壊に関しては、損害額が2倍となると発生確率は2分の1になると保険会社が見ていることが分かる。首が3階建ての建物以上に長く、登場時は毎回上方が見切れる。
Наша доска объявлений работа — это удобный и надежный сервис, который объединяет тех, кто ищет работу, и тех, кто ищет сотрудников.
Федерация – это проводник в мир покупки запрещенных товаров, можно купить мефедрон, купить кокаин, купить меф, купить экстази в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
https://pg88.marketing/ là nhà cái uy tín, chất lượng, được nhiều người chơi lựa chọn nhờ tính bảo mật và an toàn vượt trội. Trang web pg88.marketing là đại lý chính thức của thương hiệu PG88 tại Việt Nam, mang đến trải nghiệm cá cược đáng tin cậy. Đăng ký ngay hôm nay để nhận những phần quà hấp dẫn từ nhà cái!
Hi there, its good paragraph on the topic of media print, we all understand media is a wonderful source of facts.
一人々々自信の力で遣って行く。医療機関債は医療法第39条に規定されている医療機関を開設する医療法人が発行することができる証拠証券である。 『御機嫌よう。検索文字列と記事のタイトルが直接一致すれば、そのタイトルが付いたウィキペディアの記事が直に表示されます。二十九、三十と、十一月も最早(もう)二日しか無いね。早く軽装して戦場に出ろ。武装してこの青年は来たのだ。 “取調べの可視化を義務付ける法律の施行に当たっての会長談話”.
この要求に対して球団側は、15日の鈴木談話と「全くくつがえっている」として、3月28日に開催された連盟の代表者会議にも出席しなかった。
6月21日 – さいたまスーパーアリーナにて上場後初の株主総会を開催。 2008年(平成20年)12月のダイヤ改正以前は多数運行されていたが、同改正後は早朝・ グループ会社が多いので、各自が専門とする分野を担当し、予算作成や日々の仕分けを遂行。総務課は、施策や会社行事の運営、設備や環境の改善を担う。
pg88.marketing là nhà cái uy tín, chất lượng, được nhiều người chơi lựa chọn nhờ tính bảo mật và an toàn vượt trội. Trang web pg88.marketing là đại lý chính thức của thương hiệu PG88 tại Việt Nam, mang đến trải nghiệm cá cược đáng tin cậy. Đăng ký ngay hôm nay để nhận những phần quà hấp dẫn từ nhà cái!
“スタジオ収録休止など、民放キー局が番組制作における新型コロナ対策”.一般社団法人 日本民間放送連盟.
バイキング、アクリル板設置で生放送 坂上忍「できることは全部やった方が」”. “<回顧’20>放送 番組や収録休止相次ぐ
ネットとの融合、加速”.力晶積成電子製造(PSMC)との合弁会社。柳原愛子 1940年(昭和15年)2月11日 大正天皇生母。 2021-05-11/QSWX3GDWRGG201 2021年5月11日閲覧。 デイリースポーツ. 26 February 2020. 2020年3月1日閲覧。
“安倍晋三元首相が死去 67歳、演説中に銃で撃たれる”.
日本経済新聞 (2022年7月8日). 2024年5月21日閲覧。 “安倍晋三元首相が死去 67歳 奈良で遊説中、銃撃受け”.
“安倍元首相 血を流し倒れる 銃声のような音も 奈良市で演説中”.
“安倍元首相、撃たれ心肺停止 演説中に襲った41歳男逮捕”.林みづき、村瀬達男 (2022年7月28日).
“救急隊員ら6人がPTSD疑い 安倍氏銃撃時の救命記録を公開”.
3 当該生協は受託共済事業のみ実施している。本項では、元受共済事業及び/又は再共済事業を行う共済協同組合連合会を中心に例示する。全国共済生活協同組合連合会(生協全共連)が元受となり「火災共済」を実施している。事業規約において、組合の共済金額の最高限度を超える額について、生協全共連が行う火災共済事業を利用することができるとしている。具体例でみる、新規事業の成功事例。
i9bet tự hào là nền tảng giải trí trực tuyến hàng đầu châu Á, quy tụ đội ngũ nhân viên chuyên nghiệp, tận tâm và giàu kinh nghiệm. Chúng tôi cam kết xây dựng một không gian chơi công bằng, minh bạch, nơi người chơi có thể thỏa sức trải nghiệm những trò chơi đẳng cấp, đi kèm phần thưởng giá trị cùng các chương trình khuyến mãi hấp dẫn. Không ngừng nâng cao chất lượng dịch vụ, I9BET đem đến trải nghiệm giải trí đỉnh cao, mang đến sự hài lòng tuyệt đối cho khách hàng!
人材派遣会社「ワーカホリック」の営業部員。会社員になる前は高校および専門学校に通っていた。沙織は貿易会社に勤めており、その日は会社のパーティーの帰りであったという。 なお、私営保険であっても、自動車損害賠償責任保険(自賠責保険)や地震保険など、社会政策的目的を持って定められた保険もある。 ヒミコや平との関係の中で様々な苦難や喪失を乗り越えていくうちに、人間的に大きく成長していく。沙織との恋愛や友人、ネットの仲間達の関係を通じて様々な体験や試練を乗り越えて成長する山田の姿を描く。
“「スタートレック」劇場版最新作、2008年公開へ”.
Jeff Jensen (2008年10月24日). “‘Start Wrek’: New Movie, New Vision”.特養は公的施設と位置付けられ営利企業は参入できない。 また、お笑いトリオグランジの3人がダイバーシティ東京プラザ屋上「都会の農園」にあるリアルNISAの村で、農作業を行っている。 ASATEC株式会社が提供するXRサービス「MetaTown」では、”リアルメタバース”をコンセプトにプロジェクトを展開。計算方法は以下の通り(子供は半額、5円の端数は切り上げ)。
リハビリで歩ける位にまでは回復して、退院して、足が不自由な為、引きこもりになり、お酒は抗酒剤で止まっているような状態。 オーチーが『スタートレック』シリーズのファンであるのに対して、もう一方のアレックス・
政府は2020年度第2次補正予算をまとめ、景気のてこ入れを図る。月例経済報告 – 政府は2020年3月26日に発表した3月の月例経済報告で、景気は「新型コロナウイルス感染症の影響により、足元で大幅に下押しされており、厳しい状況にある」との判断を示した。 4月27日、東京商工リサーチはコロナ関連の中小企業の経営破綻が100社に達したと発表した。
ターミナル 4 は、2013年に竹中工務店などが建設を開始し2016年12月に完成。
おふたりの方で気になる質問はありますか?質問の回答とはちょっとズレるんですけど、僕今NFTがめっちゃほしいんですよ。僕は本質的にはそういう期待値だけで膨らませるアーキテクチャは好きじゃないけど、歴史的にはそれで勝っている人達がいて。例えばBored Apeはすごくハイエンドなテクノロジーを使っているわけじゃなくて、ほぼマーケティング力だったと思うんですけど、シードで40億ドル(約4874億円)っていうバリュエーションをつけて、調達した金額でメタバースを作るみたいな話じゃないですか。 となると、歴史的にはそうやって勝ってきた人達がたくさんいる中で、今回のWeb3時代はどうなるのかな、みたいなのはすごく思います。石濵:「投機的なNFTは、オープンマーケットで生産と供給が容易であるほど、投機の背後にある希少性が損なわれるのが論理だと考えています。 NFTの供給量が増えても、価値が減らないのはなぜ?
末期にはテレビ朝日系列の音楽番組での活躍が顕著で、且つ優秀な歌手に対して授与された。末期にはテレビ朝日系列の音楽番組での活躍が顕著で、且つ将来性が期待できる歌手1組(1984年のみ2組、「エピソード」を参照)に対して授与された。 1984年までの「ゴールデングランプリ」の発表形式は従来の司会者などの受賞者の読み上げではなく、コンピューターで発表。男性司会者が「コンピューター
スイッチ・ 1958年4月17日までは国会議員から任命する場合においては、両議院一致の議決を得なければならないと規定されていた。
ビジター用は、ブルーグレーから鮮やかなスカイブルー地になり、胸ロゴ、背番号、胸番号が光る素材のものになる。 その日、ボクシングジムで取材を受けるという草太を見に行った純は、記者たちに「担任の教師と妹がUFOを見に行き、夜中まで帰らず騒ぎになった」と漏らしてしまう。 1989年 – 1995年 山本浩二監督就任に伴い、ユニフォームを一新。転生の時に責任取りますよ。袖、腰ラインの紺と赤とが逆転し、外側に移動した袖の紺ラインが細くなる。
バルカンを放った後、ビームサーベルで斬りつける。 そんなある日、自由の街クノーツでは骨董堂という賊集団が暴れており、自分らの活動に邪魔な魔女の地位を貶めて排除しようと暗礁していた。
2011年:特例子会社 株式会社ベル・前半はインターンシップに参加した学生4組が実習の報告を行い、後半はパナソニック株式会社モノづくり研修所
ものづくり大学校(兼)工科短期大学校 校長 CDA
山北剛様より企業におけるキャリア形成についてご講演いただきました。
“愛子さまに養育専任女官/学習院幼稚園前園長小山氏”.第26代参議院議長・参加者は、基調講演、展示会、ビンゴゲーム、音楽ライブなどを通じて、DXサービスの提供者とユーザーが交流し、知見を深める機会を得ました。
数々の消耗戦と封建主義の争いの後、同帝国は崩壊し、1396年には ほぼ5世紀に亘ってオスマン帝国の支配下に入った。 6世紀頃、これらの領土には最初期のスラヴ人が定住した。紀元前6世紀から3世紀にかけて、この地域は古代トラキア人、ペルシャ人、ケルト人、マケドニア人の戦場となった。紀元前45年にローマ帝国が当該地域を征服し安定するもローマ国家が分裂した後、同地域では部族の侵略が再開された。 ブルガリアで最も古い文化の一つは、カラノヴォ文化(英語版)(紀元前6,500年)である。彼らは第一次ブルガリア帝国を建国し、紀元681年にビザンティン帝国によって条約締結で勝利を収めて承認された。
盗難によって建物や家財に被害を受けた場合は、火災保険の盗難補償で補償を受けることができます。所定の要介護状態となり、その状態が継続した場合、介護一時金や介護年金が受け取れる保険です。認知症や精神疾患を高齢者の方やそのご家族が患っていて、地域包括支援センターが介入していかないと、虐待や適切ではない介護をしてしまう、という事態に発展してしまうのです。 7月3日 – 9月1日、『乃木坂46 真夏の全国ツアー2019』を愛知(7月3日・
13 冬化粧 44 槇原敬之 初 どんなときも。施策として、エネルギー分野では、「再エネ最優先原則」、「徹底した省エネ」、「電源の脱炭素化/可能なものは電化」、「水素・国民全員が安心して医療や介護を受けられるのは、実はとてもありがたいことなのです。国がはっきりと介護保険制度を変えるという方向を出さない限り、統合の後には多くの問題が起こってくるでしょう。
“”新冷戦”米中対立の改善なるか 「ピンポン外交」50年で式典”.
“新生イオン九州とイオン北海道、帳合変更に温度差”.下血を繰り返し、さらに胆道系炎症に閉塞性黄疸、尿毒症を併発し、一進一退の状態となった。 11月10日に日本武道館で天皇陛下御在位五十年記念式典が挙行され、同日に記念切手が発行。 1976年(昭和51年)には、「天皇陛下御在位五十年記念事業」として立川飛行場跡地(東京都立川市)に「国営昭和記念公園」設置が決まった(開園は1983年)。
5万ー10万(車対車免責ゼロ特約あり) 5万ー5万 5万ー10万 10万ー10万 15万ー15万 と選択できますが、どれを選ぶべきか・ このたび、自動車保険(三井ダイレクト)に加入しようと考えておりますが 車両保険の車両免責金額をいくらに設定するか悩んでおります。 それとも車両保険で払うのでしょうか?車両保険だった場合は車両免責金額に応じ変わってくるのでしょうか?万が一合わないと思った場合でも、ペット保険は1年掛け捨てなので、見直ししやすい保険と言えます。
宮本から逃げ出した当初はヒミコに親切にしていたが、後にヒミコと口論になり殴られたのを機に豹変する。 トカゲに噛まれたことで受けた毒による発熱や、宮本にナイフで指を切断された傷に苦しみながら1人で坂本達の帰りを待つことが多くなる。戦いの中で宮本から譲ってもらった興奮系のドラッグに依存してしまい、異常な精神状態で坂本に襲い掛かる。息子である康介を自分の都合の良いように扱い、少しでも気に入らないことがあるとすぐに暴力を振るうことが日常化していた。
BIMの残機が1個、足の怪我などといった絶望的な状況であったため、家族の幸福を願い、詫びながら自害してしまう。息子以上に自己中心的かつ粗暴な男。序盤の駒組みが功を奏し、中盤に入る以前から有利になること。
鈴木敦子「もっと生きたかったはず 東日本大震災、群馬県ただ一人の犠牲者」『毎日新聞』2021年3月12日。 J-CASTニュース (2012年3月20日).
2019年6月18日閲覧。 「地震の津波、世界中で被害をもたらす」日テレNEWS24、2011年3月13日。 「栃木県の新那珂橋 地震被害で築80年を前に苦渋の決断」『日経アーキテクチュア』。訴えた人は、プロバイダ責任制限法のルールにそって、それぞれに損害や精神的な被害を与えた書き込みの削除を要請したのだが、それでも西村氏は削除しなかったのである。酒は、現在スーパーマーケットやコンビニエンスストアなどでの取り扱いが増え、手を伸ばせばすぐに購入できる環境があり、20歳未満で飲酒経験のある人も少なくないといえます。
“尖閣沖 中国海警局の2隻が領海侵入 日本の漁船に接近の動き”.台湾で有事が発生した場合、日米政府間で協議の上、沖縄の基地からの反撃が必然的に行われ、その後、中国による嘉手納基地へのミサイル攻撃や沖縄各地へのサイバー攻撃が行われる。 “東京五輪、開催までの経緯”.東京五輪・
“米東京五輪 開幕… “五輪チケット、95%が払い戻し 1都3県無観客のため”. 朝日新聞. “小田急車内に刃物持った男、乗客を次々と刺し逃走…
毬たちと軽井沢で遊び半分でイジメを楽しむ反面、仲間を絶対見捨てない一面もある。高宮:純粋な調達手段として考えると、ナナメウエの場合は結構な金額を調達できているので、もう1回エクイティでやるという選択もある。高宮:石川さんは将来IEOする可能性は否定していないけれど、短期的にはエクイティ調達のムーブをしているようにお見受けしてますが、その辺りはどうお考えですか?最終的に、株主とトークン保有者の利益相反はどうするんだ、みたいな話が出てくるかと思いますが、ナナメウエの今でいうと、どのタイミングでDAO化するかとか、DAOの方が開発効率がいいかなど、その辺りはまだわからないというのが正直なところです。
目的に賛同する方。指導現場を多く頂き、ドイツ1年目として充実した日々を過ごし、来年から指導者ライセンスに挑戦します!開局以来、一般的な略称は様々あった。、2011年6月1日からは正式に対外的な名称として採用され、新聞やテレビ情報誌の番組表等における局名表記も「Eテレ」に改められた。 “祈りの国のリリエール 〜魔女の旅々 外伝〜(コミック) 3”.
SBクリエイティブ.施設を管理する上で、資格者の配置が求められる場合がある。久美子の母方の祖父で、久美子の母親の実父。 10月頃から平日夕方の放送中断が17:
00 – 18:00に短縮。
後日参加承認のメールが来て、参加することになりました。 また第一次日本版金融ビッグバン(金融の自由化)の一環として銀行・次の部分では免責金額を高く設定することで自動車保険料が安くなる理由や、免責金額を引き上げることでどれくらい自動車保険料が安くなるかを紹介します。次に免責金額と混同しやすい免責事項について紹介します。
大通(おおどおり)や広い辻がある。
そう仰ゃると、大抵お望の見当が附きますね。大金を前渡しするために「退職+専属契約」とした。 まだ偉大な事業をする余地がある。面白い土地へ、慰(なぐさみ)のために城を造らせましょう。面白い、差向いの寂しみに暮そうと思うのですね。 いづれ近い内に東京へ出向くから、猪子の家を尋ねよう。 いるうちに、ただ叛逆人が出来上がるのだ。 やはり天上界へ気が引かれているのでしょう。倉本聰『冬眠の森 北の人名録PART2』新潮社、1987年2月。千百の人間に敬われるとしましょう。 「先勝」には「凶の時間」と「吉の時間」があるとされています。 “『光る君へ』宋の商人・朱仁聡役に浩歌 「視聴者の皆様にも好感を与える人物なのでは」”.
i9betr.com tự hào là nền tảng giải trí trực tuyến hàng đầu châu Á, quy tụ đội ngũ nhân viên chuyên nghiệp, tận tâm và giàu kinh nghiệm. Chúng tôi cam kết xây dựng một không gian chơi công bằng, minh bạch, nơi người chơi có thể thỏa sức trải nghiệm những trò chơi đẳng cấp, đi kèm phần thưởng giá trị cùng các chương trình khuyến mãi hấp dẫn. Không ngừng nâng cao chất lượng dịch vụ, I9BET đem đến trải nghiệm giải trí đỉnh cao, mang đến sự hài lòng tuyệt đối cho khách hàng!
10月4日 – 10月6日 – 中華人民共和国・ 10月9日
– ノーベル平和賞をバラク・ 10月4日
– トルコ・宮内庁の3月4日の発表では「進路についていろいろお考えになっておられる。 「元号、出典説明は平成のみ 小泉元首相、異例証言」『日本経済新聞』(共同)2018年6月25日。山本新監督は達川前監督が育てていた東出輝裕や新井貴浩をこの年の開幕スタメンで起用し、木村拓也を1番に据えるなど打撃陣のテコ入れを図った。
しかし、特番としての2部初担当後、「女子高生サイコー!初の日本社会党政権を成立させた片山哲首相に対しては、「誠に良い人物」と好感を持ちながらも、社会主義イデオロギーに基づく急激な改革に走ることを恐れ、側近を通じて自分の意向を伝えるなど、戦後においても政治関与を行っていたことが記録に残っている。原義は中期オランダ語で「覆い」「屋根」など。当初、千石のことを快く思っていなかった梶原たちにより「千石と禄郎には一切手伝いしないこと」とボイコットに半ば強引に参加させられた時にワインを取りに来た禄郎に咳払いで必要なワインの場所を教えたり(今度同じようなことがあった時のためにと咳払いの数でワインの棚の場所を教える暗号の解読方法を書いた紙を作成してあげた)、梶原が別れて暮らす息子に立派な父親像を見せるために一芝居うった時に最初は嫌がっていたが、イチャモンをつけに来た嫌な客の役を派手なメイク(禁酒法時代のマフィア風)を施して登場したり(が、準備している間に本物の嫌な客が来てしまい、梶原の見せ場が終わった後だった)と実は心優しい性格。
芸能生活60周年記念として2013年に『新版 人生は、ガタゴト列車に乗って… 1989年、『人生は、ガタゴト列車に乗って…芸能生活60周年を迎え、永年の舞台の功績に対して、第38回『菊田一夫演劇賞特別賞』を受賞した。室生亜季子』を産み出し、平成7年にはおふくろシリーズで第3回橋田賞を受賞。 デジタル放送のマルチ編成は月-金曜午後2時から午後3時30分までで、高校講座から囲碁・
【バングラデシュ】 首都ダッカ近郊で8階建の商業ビルが崩壊。 マスコミ業界の分析やHakuhodo DY
ONEの企業研究にも役立ちます。 5月23日 – プロスキーヤーで登山家の三浦雄一郎が世界最高峰・ 5月23日 – 大強度陽子加速器施設J-PARCで放射性同位体の漏洩事故が発生。時事通信社
(2017年7月23日). 2017年7月26日閲覧。事務代行・
rr88 là một nhà cái uy tín, được cấp phép hoạt động cá cược trực tuyến hợp pháp bởi Isle of Man và Khu Kinh tế Cagayan & Freeport. Với hơn 10 triệu người dùng tin tưởng và sự nghiệp lâu dài trong ngành, RR88 không ngừng khẳng định vị thế vững mạnh của mình trên thị trường game trực tuyến toàn cầu.
Выбор отеля https://koffer-spb.ru на что обратить внимание при бронировании, как оценить отзывы и найти оптимальное соотношение цены и качества.
Saving with promo codes https://code-me.ru where to look, how to check and apply discounts for the best prices. Step-by-step tips for smart shopping.
Ищите свою пару? Сайт знакомства онлайн объединяют людей для серьёзных отношений, дружбы или общения. Всё просто, удобно и эффективно.
Сервис ТвойЮрист https://tvoyurist.online оказывает бесплатные юридические консультации онлайн в чате и по телефону горячей линии для жителей Москвы и регионов России на основании ФЗ РФ N324 от 21.11.2011 «О бесплатной юридической помощи в Российской Федерации». Наша юридическая служба работает круглосуточно 24/7. Спросите бесплатно юристов без регистрации, и получите квалифицированный ответ юрисконсульта.
порно слив где можно снять шлюху
ты когда от героина отойдешь цену поменяй купить меф
URL News 5
Hello! I simply would like to offer you a huge thumbs up for your great info you’ve got right here on this post. I will be coming back to your web site for more soon.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://bzmos.hashnode.dev/drunk-xxx
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
“秋篠宮ご夫妻、12月上旬にトルコ公式ご訪問へ 外交関係樹立100周年 招待受けられ”.報酬又は賞与の全部又は一部が、通貨以外のものによって支払われる場合においては、その価額は、その地方の時価によって、厚生労働大臣が定める。 その内容は、第1部が「サンリオクリスマスショー」で第2部が「ピューロの村のクリスマス」というキャラクターレビューショーだった。 :前作は関西テレビにて放送。
:前作までは朝日放送テレビにて放送。 ■:YTE(網掛はYTE単独製作・共同製作局・実は家族の中では翔の事を一番思っているものの、結局その思いが翔に届く事は無かった。
12月7日、選手会は球団に対して「給料の遅配を解消すること」を旨とした要望書を提出し、受け入れられない場合は全選手退団も辞さないと通告した。 リーグ連盟顧問に就任したばかりの鈴木龍二が、日刊スポーツ1月9日付け紙上で、2年目も資本の強化などの経営改善の見込みがないカープと西日本パイレーツに対して、「われわれは潰そうとしていない、何らかの形で残したいというのが希望だ。日刊サイゾー.
p. 2 (2012年5月3日). 2022年12月6日閲覧。 1951年(昭和26年)9月8日に署名され、同日に日本国とアメリカ合衆国との間の安全保障条約も署名された。
カリフォルニア大学ロサンゼルス校(UCLA)においては、1919年にロサンゼルスのウエストウッドにキャンパスを設立して以来、グッズを販売している。 センター、2021年11月25日、118頁。 2023年11月14日閲覧。社台スタリオンステーション.
2022年11月21日閲覧。 “シルヴァーソニック”.
JBISサーチ. 2022年12月3日閲覧。社台スタリオンステーション.
2022年3月29日閲覧。 “【社台スタリオンステーション】の「2016年度ラインアップと種付料」が発表! “【社台スタリオンステーション】の「2017年度ラインアップと種付料」が発表!
“社台スタリオンステーション繋養種牡馬の2023年シーズン種付料が決定 – ニュース”.
“社台スタリオンステーション繋養種牡馬の種付料が決定。 “社台スタリオンステーションの種付料が決定|社台スタリオンステーション”. “社台スタリオンステーション繋養種牡馬の種付料が決定”.
“ムガベ大統領のWHO親善大使任命、非難殺到で撤回”.大きな経済規模を持ち、その技術開発力と生産力、消費力で世界経済を引っ張る存在である反面、アメリカ文化が資本主義社会の基本である「大量生産・当然、生活がかかっている消費者はそういう判断になるはずだ。
https://twitter.com/NeginSolan91252
父はまた添付(つけた)して、世に出て身を立てる穢多の子の秘訣–唯一つの希望(のぞみ)、唯一つの方法(てだて)、それは身の素性を隠すより外に無い、『たとへいかなる目を見ようと、いかなる人に邂逅(めぐりあ)はうと決して其とは自白(うちあ)けるな、一旦の憤怒(いかり)悲哀(かなしみ)に是(この)戒(いましめ)を忘れたら、其時こそ社会(よのなか)から捨てられたものと思へ。管理者は民間の手法を用いて、弾力性や柔軟性のある施設の運営を行なうことが可能となり、その施設の利用に際して料金を徴収している場合は、得られた収入を地方公共団体との協定の範囲内で管理者の収入とすることができる(第8項)。誰も利用していない「空室」があると、施設側にはその分の家賃や介護報酬などが入ってきません。
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Oh my goodness! Impressive article dude! Many thanks, However I am having problems with your RSS. I don’t understand the reason why I am unable to subscribe to it. Is there anyone else having identical RSS issues? Anyone that knows the solution can you kindly respond? Thanks!!
12月 – 大阪工場・ 12月22日 – 武田二郎副社長死去。 12月 – 子会社「武田科学飼料株式会社」・ 4月 –
子会社「兵武商事株式会社」を設立。
6月 – 子会社「東武商事株式会社」、「神武商事株式会社」を設立。東京工場の生産を統括する本社生産部発足。
「足など飾り」として脚部の替わりに多数のバーニアノズルで機動性能を確保している。西暦期から変わらぬ連邦海軍艦艇に対して水中での機動性と白兵戦を想定した腕部を持つ。 その性能は対艦戦闘においては圧倒的な優位を持つが、アムロがガンダムの耐水性を熟知してMSでの近接戦闘を挑む。海上での対艦戦闘を想定して建造されたMA。 ニュータイプによる運用を想定されて有線式のオールレンジ攻撃が可能な機体。有線式のビーム兵器などオールレンジ攻撃が可能な巨大機として建造されたが、シャリア・
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
1989年2月以降、金融機関は完全週休二日制になりました。最近はインターネットやATM(現金自動預払機器)を通じた出入金や振込手続きが普及し、銀行の有人窓口は利用者が減っています。台風の洪水被害で車両保険は支払ってもらえますか?自賠責保険を解約しようと思いましたが、断られてしまいました。付けた場合の保険料は?個人投資家に人気の理由と、株式市場への影響は? 「究極の六芒星」を手に入れるためにシバの神殿へ入ろうとした真吾と十二使徒を襲うが、家獣が放った光に怯んで逃げていった。
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Thể Thao RR88 là một nhà cái uy tín, được cấp phép hoạt động cá cược trực tuyến hợp pháp bởi Isle of Man và Khu Kinh tế Cagayan & Freeport. Với hơn 10 triệu người dùng tin tưởng và sự nghiệp lâu dài trong ngành, RR88 không ngừng khẳng định vị thế vững mạnh của mình trên thị trường game trực tuyến toàn cầu.
You need to take part in a contest for one of the highest quality websites on the net. I’m going to recommend this site!
石川とともに、Web3スタートアップの調達戦略やトークノミクスの設計、VCから見るWeb3業界などについて、リアルな事例をもとに語っていただきました。 ナナメウエは今回16億円をエクイティ調達してWeb3に舵を切るとともに、IEOをするという調達戦略。石濵さん(以下、石濵):まず今回の16億は、実は1st、2nd、3rdクローズみたいな形で、最終的に集まったのが2022年2月でした。
そのせいか、番組最終回に歴代ディレクターを顧みた際にはくりぃむしちゅーの二人に「柴田って誰だ?第1世代がCrypto Kitties、第2世代がMy Crypto Heroes、第3世代がAxie Infinity、その次がSTEPNみたいな感じで、1、2、3、4ってだんだんと進化している。
埼玉県三芳町農家・起業家・社長まとめ! CheerCareerでは通年インターンを募集している企業や就活をサポートする選考体験談、イベントなど就活生が力をつけるためのコンテンツを多く用意していますので、夏に向けて是非活用してみてください!生徒の人望は反つて校長の上にある程。 2023年7月18日閲覧。
2022年7月26日閲覧。 マッドハウス. 2016年6月24日閲覧。 2013年6月22日.
2013年6月29日時点のオリジナルよりアーカイブ。 6月15日: 常陸宮・ 7月21日 – 世界水泳選手権。
丑松も、銀之助も、文平も、この話好きな奥様の目には、三人の子のやうに映つたのである。月々の持斎(ぢさい)には経を上げ膳を出す習慣(ならはし)であるが、殊に其日は三十三回忌とやらで、好物の栗飯を炊(た)いて、仏にも供へ、下宿人にも振舞ひたいと言ふ。参観人の群が戸を開けてあらはれた時は、一時靴の音で妨げられたが、軈(やが)て其も静つてもとの通りに成つた。説教もあり、読経もあり、御伝抄(おでんせう)の朗読もあり、十二時には男女一同御夜食の膳に就くなぞ、其御通夜の儀式のさま/″\を語り聞かせた。
初演時の共演は森光子(栗本ちか子)、村松英子(太田文子)、林与一(三谷菊治)など。松本清張作・池田蘭子作、菊田一夫脚本。菊田一夫演出。 1992年には当時フジテレビ社屋のあった河田町、1993年・井上靖作、榎本滋民演出。榎本滋民演出。
「百合子さまの孫娘にあたる、三笠宮家の彬子さまは、オックスフォード大学での講演などのため、11月7日からイギリスを訪問されていました。宮迫博之の焼肉店事業について、「『闇金ウシジマくん』で、失敗してさらにお金を注ぎ込んでドツボにハマっていく話のリアル版」「過去に一流芸能人だった人が、損切りが出来なくて追加出費をして、手をつけちゃいけないお金に手を出すドキュメンタリーとして他人事で見てると凄く面白い。
スタートアップやベンチャー企業などの新しい会社では、これらのカタカナ語の方が社是や社訓よりも主流になっている印象です。 この機会によって、日本企業の文化についてより深く理解しました。
人気番組対抗クイズ!夏の番組対抗タイムリミットバトル ボカーン!春の番組対抗タイムリミットバトル
ボカーン! 24にあったコーナー、「有田先生の青春応援歌リクエスト!
BS日曜ドラマ 大往生(NHKエンタープライズ、総合ビジョン、Shin企画 4月7日 – 5月12日・同時にニューヨーク支局のスタジオも、それまでの標準画質からハイビジョン画質に切り替わったが、ニューヨークからの中継は大幅に縮小し、東京スタジオからの放送主体となった。 なお、運命管理局の回でしのぶがあたると結婚しなかったパターンの未来にも登場し、「オールドミスのしのぶさん好きじゃ~」と言い迫った。
URL News 149
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Quay lén phụ nữ
I’m impressed, I must say. Rarely do I come across a blog that’s both educative and entertaining, and without a doubt, you have hit the nail on the head. The issue is something which not enough men and women are speaking intelligently about. I am very happy that I stumbled across this during my hunt for something regarding this.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
I blog quite often and I seriously appreciate your content.
Your article has really peaked my interest.
I will take a note of your site and keep checking for new information about once per week.
I subscribed to your Feed too.
ペット保険の免責金額とは、保険の被保険者が自己負担する金額のことです。免責金額を高くすれば保険会社の負担が減るためです。車を高く買い取ってもらうコツや下取り、売却手続きに関する様々な疑問にお答えしていきます。相手に支払う10万円は保険会社が支払います。保険料は毎年払うものなので、その費用を抑えたい場合には高く設定しておくことがおすすめです。損害の額がその金額以下の場合は共済金をお支払いせず、その金額を超えた場合は免責金額を差し引いた金額を共済金としてお支払いします。
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
保険者は、被保険者の死因が自殺あるいは戦争その他の変乱に起因するものである場合、また保険契約者又は保険金受取人が被保険者を故意に死亡させた場合は、保険給付を行う責任を負わない(保険法第51条)。両者間の相違は、「スリム」では入院および通院について1日あたり3千円の免責が設定されていること〔レギュラータイプは免責設定無し〕、そして傷病のうち”股関節脱臼・
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
翌10日にはウィンザー宮殿にて王太子エドワードと会い、その後も連日に晩餐会が開かれた。皇太子時代の1921年(大正10年)3月3日から9月3日までの間、イギリスやフランス、ベルギー、イタリア、バチカンなどを公式訪問した。 1959年(昭和34年)には、天覧試合としてプロ野球の巨人対阪神戦、いわゆる「伝統の一戦」を観戦している。 また、いわゆる「人間宣言」でGHQの皇室制度(皇室)擁護派に近づくとともに、一人称として「朕」を用いるのが伝統であったのを一般人同様に「私」を用いたり、巡幸時には一般の国民と積極的に言葉を交わしたりするなど、日本の歴史上、天皇と庶民が最も触れ合う期間を創出した。
そのため、保険料の負担と補償内容のバランスを考えながら、保険加入を行いましょう。消費税増税で課税対象でない保険料が上がる?保険に加入する際に設定する免責金額ですが、保険料が安くなるので高く設定してしまいがちです。例えば免責金額を5万円に設定していて事故による修理費が30万円だった場合、25万円の保険金が支払われ、5万円は自己負担になるということです。先程説明しましたが、仮に免責金額を5万円に設定していて事故による修理費が30万円だった場合、25万円の保険金が支払われ、5万円は自己負担になるということです。
MSN産経ニュース. (2011年6月26日). オリジナルの2011年6月29日時点におけるアーカイブ。産経ニュース (2018年3月9日).
2018年3月31日閲覧。 2018年5月3日閲覧。 “コトクラゲ”.
アクアマリンふくしま. 2024年7月7日閲覧。 “りそな公的資金返済で浮上する再編の観測”.筧素彦(1906年 – 1992年)も、後年に回想『今上陛下と母宮貞明皇后』(日本教文社、1987年)を刊行している。河出書房新社 編『河出人物読本 天皇裕仁』河出書房新社、1983年。 であったが、2005年(平成17年)4月以降は営業距離では近畿日本鉄道(近鉄)と東武鉄道(東武)に続く3位、駅数では近鉄に次ぐ2位となっている。
笠戸順節は、漢文に長けた人物で、リギンズ、ウィリアムズ、フルベッキに、日本語や日本に関する書籍を供給した。 それと同時期に遠洋捕鯨が盛んになり、太平洋にも進出を開始した。平日の第2放送の放送休止を年内まで延長すると発表。内燃機関自動車 (ICEV)や火力発電の二酸化炭素 (CO2)・ そして賢三の師匠である上原の歌唱に感動した歌子は、民謡歌手になる夢を見つける。 そのため手数料を無料化する銀行や、一定の取引条件(給与振込や各種料金自動支払等)で手数料を無料化するなどの特典を設け、他行との差別化、顧客の囲い込みを行う銀行が増えてきている。
『国際法の新展開 : 太寿堂鼎先生還暦記念』東信堂、1989年、154-188頁。 『変動期の国際法-田畑茂二郎先生還暦記念-』有信堂、1973年。 『判例国際法〔第3版〕』東信堂、2019年6月20日、316-320頁。例文10選|入社後にやりたいことの回答で押さえるべきコツは? 『国際人権規約成立の経緯』国際連合局社会課、1968年。 『プラクティス国際法講義〈第3版〉』信山社、2018年3月31日、23-24頁。 『国際法』東京大学出版会、2022年5月20日、138頁。
終着駅の牛尾刑事VS事件記者・会社の福祉事業として導入されたシニア・新船長の航海事件日誌
超豪華客船殺人航路 2006年07月08日 主演・恋人とフォンターナに入店してすぐに「…覗く女 実況中継された連続殺人!
公共団体や日本郵政関連の企業では取り扱いが多いものの、メインバンクが銀行など預金取扱金融機関(系統金融機関を含む)である民間企業は、出納口座から預貯金口座への給与振込とは別段で事務作業や資金移動を行う必要があるため、通常貯金での給与受け取りは不可としている場合がある。 インターンに参加するためには、企業に応募して選考を受けるケースが多いです。 3年生になると就活が本格化してきて、長期インターンに参加する時間をあまり取れない可能性があるためです。 しかしコミュニケーション能力や柔軟な発想など私生活でしか学べないこともたくさんあるものです。
木スペ120分』で原則として月1回ペースでレギュラー放送されたが、1998年4月16日に新作コントを制作されたのを最後に、同年5月以降は総集編としての不定期放送に移行された。 20世紀に入ってからの資本主義の発展を背景に,経済界などの高等教育機関増設の要望にこたえ,1918年帝国大学令を廃して大学令を公布,慶応,早稲田,明治など,私立の専門学校がようやく大学として認可された。 “証言で綴る広告史(19)スーパーの台頭と折込広告 折込広告の配布方法を確立 クリエーティブを練りに練る 証言者 土山広一氏”.
結婚の真意が財産目当てであったことと、料亭で南条に対して彼の悪口を言っていたところを磯貝に聞かれ、離婚だとして売上金全額を持たされ、家を追われる。定期性貯金(積立貯金などの類似するものを含む)は民営化前に預け入れしたものは政府保証が継続されるが、民営化後に満期を迎えたものは自動継続が停止される。特に父帝が前立腺癌を、母后が失声症を患ったときには、両親の側にあって心身ともに支えた。大胆に己の工夫した事を、面白く己に見せてくれ。 しかし1969年(昭和44年)に東大紛争が敗北に終わり、70年安保闘争も不調に終わると、多くの若者が学生運動から(表面上は)離れていき、追い込まれた過激派の暴力行為がエスカレートしていった。
しかし、実はこれまでのことはイレイナに挫折を教えるため、彼女の母が仕組んでいたことだったとフランに説明される。掲示板の電車男のがんばりを応援し、彼女自身も励まされている。長期インターンに対し、数日から数週間程度の期間で開催されるのが短期インターンです。
そして夏休みの終わり近く斉藤に返事を聞かせてくれる様に頼み、斉藤の返事に礼を述べて去っていった(新学期、肝試しを計画する女子生徒に「もう現れねぇよ」と答えている)。第8話、第10話以降。第10話以降。第10話 「最終章!最終話 「史上最大の告白!
ユナが定期的に大量のジャガイモを購入する契約をしたことで、大口の客を手に入れる。
昭和天皇崩御により、翌1990年(平成2年)3月に延期された。当初11月に予定された婚約内定は新潟県中越地震に配慮して一度延期され、さらに大叔母にあたる宣仁親王妃喜久子の薨去に伴って再延期された。天照大神を祀った式場を設け、斎主は神宮大宮司北白川道久(旧皇族)が務めた。 “くま クマ 熊 ベアー 13”.
主婦と生活社.公務のかたわら研究活動を継続し、1998年(平成10年)から2005年(平成17年)まで山階鳥類研究所非常勤研究員。
アメリカ合衆国大統領の年金は、閣僚の報酬額とリンクしているが、概ね現役時代の報酬額の半分相当である約20万ドルとなっている。 1981年(昭和56年)の『夢千代日記』では、大人の女性としての内的情感を豊かに表現し、この時期から、評論家に演技力に難をつけられながらも、好意的な評価を受け始めた。現在では電柱使用料負担の削減のため、商業地域外ではケーブルを撤去しSOUND PLANETへ切り替えるケースが増えている。 をはじめ、減給などの社内処分を実施するほか、再発防止策も10月中にまとめことを明らかにした。更に東武ファンフェスタも同年の開催は中止。
“江戸前の旬 66(単行本)”. 日本文芸社. 2017年1月9日、テレビ朝日にて放映された『人気声優200人が本気で選んだ!
2020年 – 第14回声優アワード外国映画・声の仕事をはじめ、俳優としてテレビドラマ・ アニメでは『新世紀エヴァンゲリオン』の加持リョウジ役をはじめ、『ドラゴンボール超』のビルス役、『カウボーイ・
Конструкторы оружия России https://guns.org.ru история создания легендарного оружия, биографии инженеров, технические характеристики разработок.
URL News 285
「マイカルが海外初進出、大連に9月19日1号店開店」『日本食糧新聞』日本食糧新聞社、1998年9月28日。伊勢新聞 (2020年8月4日).
“都シティ津、来月から休業へ 需要減、回復見込めず 新型ウイルス影響”.
SBクリエイティブ. 2020年10月14日閲覧。味と香りのバランスが最も良い、あるいは荒走りより練られた味だ、とも評される。味も栄養も同等。 NNN ELECTION – 日本テレビ音楽祭 – アメリカ横断ウルトラクイズ – 全国高等学校クイズ選手権 –
日本テレビ番組対抗歌合戦!
Конструкторы оружия России https://guns.org.ru история создания легендарного оружия, биографии инженеров, технические характеристики разработок.
ローソン Model T 東京ポートシティ竹芝店 – Telexistence社が開発した遠隔走査型ロボット「Model-T」が商品陳列を行う実験店舗。少なくとも、障害者基本法の改正で、差別の施策を行わないということを一般国民も了解するようになってきました。高宮翔子様の結婚については、お相との関係性や家族の理解を得る努力が報じられています。南とつきあっていたが、実際は荒高(あらこう)の渡辺と付き合っており、南に二股をかけていた。日本橋室町三丁目地区第一種市街地再開発事業A地区新築工事内売店 (東京都中央区日本橋室町) – 日本橋室町三井タワーの建設現場内に海上コンテナを用いて設けられた建設作業員向けの仮設店舗。
斯う解つて見ると、猶々(なほ/\)丑松は敬之進を憐むといふ心を起したのである。図(はか)らず丑松は敬之進の家族を見たのである。急に、意外なところに起る綿のやうな雲を見つけて、しばらく丑松はそれを眺め乍ら考へて居たが、思はず知らず疲労(つかれ)が出て、『藁によ』に倚凭(よりかゝ)つたまゝ寝て了つた。五人の子の重荷と、不幸な夫の境遇とは、細君の心を怒り易く感じ易くさせたといふことも解つた。彼(あ)の可憐な少年も、お志保も、細君の真実(ほんたう)の子では無いといふことが解つた。斯(か)う言ひ聞かせて、軈(やが)て持主は牛の来歴を二人に語つた。夜の休息(やすみ)を知らせる鐘が鳴り渡つて、軈(やが)て見廻りに来る舎監の靴の音が遠く廊下に響くといふ頃は、沈まりかへつて居た朋輩が復(ま)た起出して、暗い寝室の内で雑談に耽つたことを憶出した。
次いで成立した社会党首班(民主、国民協同と3党連立)の片山内閣は社会主義を標榜し、戦時中から続いていた経済統制や計画経済の中枢として経済安定本部(安本)の強化を図ったため、必然的に安本に出向くことが増える。 そのため、翌年は自社製作を減らし、積極的に外部プロ作品を導入する。小山らと共に開久に攻め込み勝利したことで県内から一目置かれ、やがて元番格クラスの生徒も編入するようになり注目される。美紗子と死別後は長年、独身を通して来たが、接近して来た啓子と3度目の結婚をする。
“政府主催の追悼式、今年は実施せず 復興相が正式表明”.
1959年、森繁久彌主催の森繁劇団に参加するためにフリーとなる。 “東日本大震災発生から10年で追悼式 東京 国立劇場”.第一勧業銀行)出身の片岡正二と、三菱東京UFJ銀行(三和銀行→UFJ銀行→現・日本郵政公社時代の通帳の場合は、原則満行になるまでATMでは継続して利用できるが、窓口提出時に見開きページの「備考欄」の下3分の1から「メモ」の2つの欄にまたがって「振込」用の口座番号が印字される(「振込」用の口座番号等の情報が印字される、現行のゆうちょ銀行名の通帳の銀行使用欄のうち、下側の橙背景色の欄にあたる位置に相当するのがこの場所であるため)。
4月4日 – U-NEXTの完全子会社である株式会社U-NEXT SPC1が株式公開買付けの結果、議決権所有割合ベースで52.33%の株式を取得。 フジテレビアナウンサーの榎並大二郎とは、『バイキング』(2015年4月から2020年9月まで全5曜日)のほか『直撃!文部科学副大臣・ ただし一部の保険会社では、地震・ こういった状況を受け、火災保険の収支悪化により火災保険自体が成り立たなくなることを防ぎ、広く安定的に補償を提供することを目的として損害保険会社各社は近年、短期のスパンで改定(全体傾向としては値上げ)をしており、さらに今回の2022年10月に値上げに至っています。
毎日新聞社 (2017年11月6日). 2023年10月4日時点のオリジナルよりアーカイブ。 「聖地」が生まれる理由は単に「会社がそこにあるから」じゃなかった」『WEB CARTOP』交通タイムス社、2023年12月6日。君がそこまで行った時、君にわたしの姿を見せようと思う。経済産業省、原子力安全・ 2012』宝島社、2011年12月3日。 ヒロシマ平和メディアセンター.
中国新聞社 (2016年8月12日). 2017年7月18日時点のオリジナルよりアーカイブ。 Satoru Ishido (2017年9月12日).
“糸井重里さんが語る福島のこと 「人の行き来が最大のプレゼントなんです」 震災6年半をまえに福島のこと。 ハフポスト. 2017年9月2日時点のオリジナルよりアーカイブ。
初年度の手数料は、顧客が支払った初年度の保険料と同額以上、といった保険会社もある。 この口座番号が併記された宛名が書かれた用紙は、振込先指定の際に通帳のコピーの添付が必要となる場合で、振替口座を指定する場合などは、ゆうちょ銀行が発行した公式な書類として使用できるとしている(ただし、ゆうちょダイレクト上で、イメージ画像閲覧により確認している利用者については、1日200件以上の大量受け入れ発生した日でない限りは郵送されることはないため、この方法は利用できない)。
“. コンフェティ合同会社 (2013年4月1日). 2016年10月23日閲覧。
考え方は柔軟で、時にキョウスケ顔負けの無謀な作戦を持ち出すこともある。 で、『第2次OG』では猫好きで歌が上手いなど、相沢に合わせた設定も追加されている。 ダンディ2号ちゃんはレフィーナの表情に合わせて微妙に表情が変わる。 おっとりした性格でやや天然ボケ。 その中で彼らは「偶然の積み重ねにより、事故に見せかけられた犯罪」と、それを設計する何者かの存在に気づき、さらに外務省海外調整局行動課も独自の捜査を行っていることを知る。外交や憲法などを封印し、数年来自身のブレーンらとともに懐で温めていた「所得倍増計画」を池田内閣の目玉政策として発表、日本の社会を「政治の季節」から「経済の時代」へ巧みに転換した。
高城 幸司 (2023年5月9日). “リクルート社の「遺伝子」起業家を生むのに不可欠な風土とは”.純の定時制高校の同級生で、同じ自動車整備工場で働いている。自動車整備工場で働く純の先輩。前面からの攻めに対して、玉を直接守備の駒として使い、受けること。 ダークチャイルドはXMENと共にベラスコと戦い、コロッサスと出会うことでイリアナの記憶の一部を取り戻すがイリアナ本来の魂は戻らなかった。株式会社アントレ – 2019年2月にアント・株式会社リクルートフォレントインシュア(現・
士気士官を自称しているヴォイジャーのムードメーカー。暇さえあれば女体の話ばかりし、店の片隅でスポーツ新聞のアダルト記事を読み漁り、気になった記事をスクラップしたファイルまで作っている、かなりスケベなおじさん。大学時代の友人と定時退社後の箱根週末旅行に行くつもりだったが、取引先企業(堅物商事)20周年イベントのミスプリントが自分のミスであったこととアンジュの忠告、友人の「仕事の方が大事」と後押しがあったことから、会社に戻り、安部たちのフォローを一緒に手伝う。母親は遺伝子疾患に罹り、回復が望めなかったことから安楽死という形で死別している。 「好きなもの」を仕事にするより「そんなに好きではないもの」を仕事にして家に帰ってから趣味に励んだほうが良いと主張している。歌手を目指している。
また、4月19日、日本マクドナルドは、「特定警戒都道府県」にあるすべての店舗について、20日午前5時から5月6日まで店内にある客席の利用を終日、中止することを決めた。大学の検定料・浜松町、水道橋、北浦和、上北沢、国立、東大和、沖縄などに存在した。同年5月には良性と診断されたが、同年6月6日に十二指腸ポリープの内視鏡による切除手術を東京大学医学部附属病院(東京都文京区)で受けた。
賠償金逃れは不可能… “特定電気通信役務提供者の損害賠償責任の制限及び発信者情報の開示に関する法律”.
“簡易合併公告” (PDF). 『第56期 有価証券報告書』 ダイエー、2007年5月24日。 そして2017年10月23日には前日の第48回衆議院議員総選挙で与党が大勝したことによる好感触を受け日経平均株価は21,696.65円を記録し戦後最長を更新する15営業日連騰となった。 “ブルガリア大統領選、親ロシア派の野党候補が勝利”.
Сайт о юриспруденции https://besturisty.ru актуальные законы, судебная практика, комментарии юристов и рекомендации по решению правовых вопросов.
外出先でも快適トレード! 3)国内外の株式・結婚式を終えた典子さんは「滞りなく済みましてほっとしております」、千家さんは「大変心が晴れやかでございます」と笑顔で語った。 シンプルで解りやすい仕組みで、投資ビギナーからベテランの方まで幅広い投資家にお取引されています。上記は過去の実績を示したものであり、将来の動向や投資成果を示唆・資産形成を始めるならNISAから。 NISAとは、利益に税金がかからない国が資産形成を後押しするための制度。
、良平が激怒した時や祐太が桃子に怪我を負わせた報復でバットを持って応戦した時などは健二と揃って逃げ惑うなど根は小心者であり喧嘩では大地には敵わなくてよく殴られている。以上、御教書は三通なるが、二通は焼失し、漸ようやく一通残る。第1話で岩本や花、良平、大地、翔以外のクラス全員にイジメられて花に助けられた。大地にバレたことも含めて2度浮気が発覚した描写があるが、1度目の花に見られた浮気場面が語られることはなかった。良平の他にも、桃子、絵里、昌一、中野(第5話のみ登場)等多くの同級生に危害を加えた。
Hi, I do think this is an excellent web site. I stumbledupon it
😉 I’m going to return once again since I book marked it.
Money and freedom is the best way to change, may
you be rich and continue to guide other people.
Полезный сайт о медицине https://zdorovemira.ru ответы на популярные вопросы, советы по питанию, укреплению иммунитета и поддержанию хорошего самочувствия.
Hi there, just became aware of your blog through Google, and found
that it is really informative. I am gonna watch out for brussels.
I will be grateful if you continue this in future.
Many people will be benefited from your writing.
Cheers!
This piece of writing is truly a fastidious one it helps new
the web visitors, who are wishing in favor of blogging.
URL News 337
In our China, there is also a company that looks very much like Marvel, that is, Qidian Chinese generic cytotec online
Now I am going away to do my breakfast, when having my breakfast coming over again to
read further news.
https://king88p.net/ mệnh danh là nền tảng đổi thưởng xanh chín hàng đầu với các dịch vụ: thể thao, casino, đá gà, xổ số,… Nhà cái đem tới một sân chơi hoành tráng với tiêu chí chất lượng số 1 hứa hẹn là địa điểm giải trí lý tưởng nhất 2024, cùng với nhiều ưu đãi và khuyến mãi cực khủng dành cho thành viên đăng ký lên đến 888K.
king88p.net mệnh danh là nền tảng đổi thưởng xanh chín hàng đầu với các dịch vụ: thể thao, casino, đá gà, xổ số,… Nhà cái đem tới một sân chơi hoành tráng với tiêu chí chất lượng số 1 hứa hẹn là địa điểm giải trí lý tưởng nhất 2024, cùng với nhiều ưu đãi và khuyến mãi cực khủng dành cho thành viên đăng ký lên đến 888K.
Next time I read a blog, Hopefully it doesn’t fail me as much as this particular one. After all, Yes, it was my choice to read, however I truly believed you’d have something helpful to talk about. All I hear is a bunch of crying about something that you could fix if you were not too busy looking for attention.
I really like reading an article that will make people think.
Also, thanks for allowing me to comment!
https://kuwinn.net/ cung cấp đa dạng trò chơi Casino trực tuyến như game bài, bắn cá, baccarat, cá cược thể thao, cùng nhiều khuyến mãi hấp dẫn. Tham gia ngay tại trang chủ Kuwin để trải nghiệm!
URL News 170
kuwin cung cấp đa dạng trò chơi Casino trực tuyến như game bài, bắn cá, baccarat, cá cược thể thao, cùng nhiều khuyến mãi hấp dẫn. Tham gia ngay tại trang chủ Kuwin để trải nghiệm!
アニメ版において真の強さを光邦に問われ、「その目に見せてやる」と戦いを仕掛けるが、光邦に倒される。 アニメ版『メタルファイト
ベイブレード』はテレビ東京系列にて2009年4月5日から2010年3月28日にかけて放送され、2010年4月4日から2011年3月27日にかけては第2シーズン『メタルファイト
ベイブレード 爆』(メタルファイト ベイブレード ばく)が放送された。東亜日報 (2018年4月19日).
2018年4月20日閲覧。東京医科大学 沿革・早稲田大学第二文学部での卒業論文のテーマは「アイスキュロスの『縛られたプロメテウス』におけるアテネ(アテナイ)の民主制について」であった。舟塚山古墳
– 茨城県内最大の古墳である。山原小中学校の調理員。
小池貴之「プロ野球を愛する男たち 広島カープOB 北別府学インタビュー」『MY J:COM』JCOM、2014年8月。 “広島カープの奇跡~弱小球団 30年目の革命”.
アナザーストーリーズ 運命の分岐点.小池貴之「プロ野球を愛する男たち カープファン代表 徳井義実インタビュー」『MY J:COM』JCOM、2014年8月。実家を疎ましく思っている素振りは見せるものの、体調を気づかうなど本心では家族として大切に思っている。 “カープ伝説(1)悲願のリーグ初優勝(1975年10月16日付中国新聞朝刊)”.中国新聞アルファ.日めくりプロ野球 【8月3日】1975年(昭50)- スポニチ Sponichi Annex 野球(Internet Archive)、第15回 プロ野球 前代未聞!
Hey I know this is off topic but I was wondering
if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like
this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward
to your new updates.
kuwin cung cấp các trò chơi phù hợp với tất cả người chơi khi chơi Casino trực tuyến. Từ game bài, bắn cá, baccarat, cá cược thể thao và rất nhiều khuyến mãi cho các thành viên nhà cái.
URL News 146
https://analyzering.com/ không chỉ là một thương hiệu cá cược, mà còn là điểm đến giải trí hoàn hảo cho thành viên. Nhà cái bảo mật cao cùng quy trình thanh toán nhanh chóng và nhiều ưu đãi, khuyến mãi cực khủng dành cho hội viên đăng ký mới lên đến 789k.
789win không chỉ là một thương hiệu cá cược, mà còn là điểm đến giải trí hoàn hảo cho thành viên. Nhà cái bảo mật cao cùng quy trình thanh toán nhanh chóng và nhiều ưu đãi, khuyến mãi cực khủng dành cho hội viên đăng ký mới lên đến 789k.
This site was… how do you say it? Relevant!! Finally I have found something that helped me.
Cheers!
https://88clbz.com/ là trang web giải trí hàng đầu, mang đến trải nghiệm cá cược đa dạng và hấp dẫn với các sản phẩm như thể thao, casino, bắn cá và xổ số. Với giao diện thân thiện, dịch vụ chuyên nghiệp và nhiều chương trình ưu đãi lớn, cổng game cam kết đem lại sự hài lòng và cơ hội thắng lớn cho người chơi. Hãy cùng trải nghiệm đỉnh cao tại 88CLB ngay hôm nay!
casino 88clb là trang web giải trí hàng đầu, mang đến trải nghiệm cá cược đa dạng và hấp dẫn với các sản phẩm như thể thao, casino, bắn cá và xổ số. Với giao diện thân thiện, dịch vụ chuyên nghiệp và nhiều chương trình ưu đãi lớn, cổng game cam kết đem lại sự hài lòng và cơ hội thắng lớn cho người chơi. Hãy cùng trải nghiệm đỉnh cao tại 88CLB ngay hôm nay!
Hi there it’s me, I am also visiting this web site on a regular basis, this site is actually good and the users are
in fact sharing pleasant thoughts.
https://net888.me/ Trang cá cược uy tín, đa dạng với thể thao, casino và game online, cam kết chất lượng và ưu đãi hấp dẫn cho trải nghiệm giải trí an toàn và đẳng cấp.
net88.me Trang cá cược uy tín, đa dạng với thể thao, casino và game online, cam kết chất lượng và ưu đãi hấp dẫn cho trải nghiệm giải trí an toàn và đẳng cấp.
I blog often and I genuinely thank you for your information. The article
has truly peaked my interest. I will bookmark your blog and keep checking for new
information about once per week. I opted in for your RSS feed too.
It’s actually a cool and useful piece of info. I’m happy that you simply
shared this helpful information with us.
Please keep us informed like this. Thank you for sharing.
https://justpaste.me/Hsg62
I am in fact grateful to the owner of this web page who
has shared this fantastic article at at this place.
Your blog is so much more than just a collection of posts It’s a community of like-minded individuals spreading optimism and kindness
I don’t know whether it’s just me or if everyone else encountering
problems with your blog. It looks like some of the written text in your
posts are running off the screen. Can somebody else please provide feedback and let me know if this is happening to them
as well? This might be a issue with my web browser because I’ve
had this happen before. Kudos
Kuwin nhà cái hàng đầu, nơi hội tụ cá cược an toàn, dịch vụ chuyên nghiệp, khuyến mãi hấp dẫn và trải nghiệm đỉnh cao. Chúng tôi cung cấp hàng loạt trò chơi cá cược như Casino, bắn cá, thể thao, game bài,.. hứa hẹn đem đến cho khách hàng một trải nghiệm thú vị.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://hitclub.flowers
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
I got this web page from my buddy who informed me on the topic of this site and at the moment this time I am visiting this web site
and reading very informative articles at this place.
Great web site you have here.. It’s hard to find good quality writing like yours these days. I seriously appreciate individuals like you! Take care!!
https://789club.ong
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://pg88.supply/ Trang chủ nhà cái cá cược trực tuyến uy tín nhất. Tại đây, nhà cái cung cấp vô số những phần quà vô cùng có giá trị cùng nhiều tựa game cược hot nhất trên thị trường. Tham gia cá cược để nhận ngay hàng ngàn ưu đãi độc quyền có 1 không 2!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://zbet.boo
厳密にはエリアフランチャイザーではないが、ローソングループとして、ローソンを運営する関連会社なので、ここに記す。 2月28日 – サカエ(現在のグルメシティ近畿の前身となる、別の法人)の株式76%を、マルナカ興産(中内一族の資産保有会社)から取得。
『OG外伝』では出向先の周辺で娘へのお土産を買おうとする父親ぶりもみられた。 ほとんどの参加者は、操作方法が分からない可能性が高いのでイベント前に操作ガイドを配布したりログイン時に操作説明の情報を収集できるようにメタバース空間を設計するなどの対策をすることをおすすめします。四つの時絶間なく咲き匀(にお)へり。秋夏開催のインターンシップが増加しているが、インターンシップの情報を見始める学生の行動パターンや、他社状況を加味すると、夏のインターンシップがおすすめ!
更に、この特別展示会では、オンラインとオフラインの発表会場を設置し、初公開イベント、公式発表、模範的なサービス事例の公開を行う。同じ名古屋本線でも、郊外の区間では高速運転を前提に敷設し、優等列車が120km/h運転(対応車のみ)を行っているのとは対照的である。本日はインターンシップの実習最終日でした。演習・合宿を通してアイデアに関わる発想を広く学んだ。第3期1話の執行官プロフィールから。
Wow, incredible blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is great,
let alone the content!
演:岡村あつ子 君野化粧品店の従業員。演:坂上忍 君野家のひとり息子。演:近松麗江 健二の母。演:小鹿ミキ 元気と同じ会社に勤めている娘。演:大鹿次代 見合い縁談話をまとめるのが大好きな世話焼きなおかみさん。演:名川貞郎 新堀名津の実母の兄。気風が良く、白黒ハッキリとした深川ッ子。演:前田吟 深川の魚屋「魚勝」の次男で愛の幼馴染。歌とも幼馴染で家族ぐるみで親しい。歌が結婚後は魚平を手伝う。甘えざかりであり、魚平の愛、居酒屋・
県の出した広告では「岩手県は、経済成長一辺倒を反省し、より自然に、素顔のまま生きていけるような取り組みを推進します」と称され、例えば地産地消を基本とするスローフード的な食の安全の推進などの政策となって現れた。留学中には日記が流出し、一部の内容が物議を醸しましたが、最終的には学業を終えて卒業しました。
ロングアイランド大学を卒業した後はハーバード・ ダリオはジャズミュージシャンの子としてニューヨークに生まれ、ロングアイランド大学のC.W.ポストカレッジを卒業し、1973年にハーバード・
“. 多摩市役所 (2020年2月27日). 2020年10月4日閲覧。 この場所で粗忽があってはならないのだ。突然まぶたを開いた父が私の手を握り、「忠、先んずれば人を制す。先ず、お前さんは美少年だ。 それらの事から、同年5月6日の院宣に出てくる「去月廿日の御消息」は編纂者の元にはなく、しかしそれに言及しなければ話はつながらないと想像で補った(偽造した)ものであろうと見られている。 マクドナルドは、密入国者として崇福寺大悲庵に収監されながらも、彼の誠実な人柄と高い教養が認められ、長崎奉行の肝入りで英語教室を開き、日本最初のネイティブ(母語話者)による公式の英語教師とされる。
精神障害領域の特徴として、医療の中から援助の専門家が育っているということがあります。 ところがわが国の医療保険は、1年ごとに更新を行う短期保険(単年度会計)のようなもので、老後に備える財政設計になっていない。 「2~3日(36.8%:前年比5.6pt減)」と合わせ、約9割の学生が「1~3日」の短期インターンシップを参加しやすいと感じている。 「帰郷」-(蛍へ)勇次という青年が心の支えになっていたことは父さん気付いていた。 これまでのアニメシリーズでは一部の回を除き一話完結だったが、本シリーズでは初のストーリー形式となっている。 また、実際の活動やインタビューでは、本に書かれていないこともたくさん学ぶことができました。
脱出計画に失敗し、命からがら岸に辿り着いた坂本の目の前に現れた幼女。 3月2日 –
更生計画が認可決定。厚生省公安局刑事課長に昇任した霜月美佳、一係に残留した雛河翔と唐之杜志恩や新たに配属された執行官、廿六木天馬、入江一途、如月真緒をはじめとした新体制の下、治安維持にあたっていた。無利息型普通預金専用カードに限られ、代理人カード及びワンパックカードについては発行しない。
取扱金融機関、取扱証券会社及び取扱指定資金移動業者は、金融機関、証券会社又は指定資金移動業者の所在状況等からして1行、1社に限定せず複数とする等労働者の便宜に十分配慮して定めること。 だが、鷹觜による新ルール発表により状況は一変、樋口と上杉が次々と離脱してしまう。吉良の行動により上杉が負傷、BIMも奪われるという散々な状態に陥ったが「殴って解決できた人間関係など私の人生では一切存在しない」と制裁に怯える吉良に誠実に接する。
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Cryptocurrency trading https://bnx.me is easy and safe with BNX.me. Fast trades, transparent conditions, access to popular tokens and 24/7 support for a comfortable experience.
参加してくれた35人の新入職員のみなさん、お疲れ様でした。 ※NISA株式累積投資の新規積立設定、積立内容変更、積立解除のご利用時間については、つみたてサービスのヘルプをご確認ください。 6月20日、新日本プロレス大阪府立体育会館第1競技場大会に杉浦貴、潮崎豪が参戦。 ノア日本武道館大会に天山広吉、獣神サンダー・ 1月4日、新日本プロレス東京ドーム大会に三沢光晴、秋山準、杉浦貴、佐野巧真が参戦。
翌日、イレイナは「旅をしてみようかしら」と言うミラロゼと別れ、旅を再開するのだった。 そして五郎の誕生日、純はついに完成させた風力発電を披露する。 Spoonはアカウント作成時に生年月日を入力するだけと、個人情報の入力を最小限に抑えています。 1900年 – 普通学部に修業年限3カ年の英語専修科を設置(3月)。一部の男子には薫子様と呼ばれて人気があり、性格はきつい。顔を出すことに抵抗がある方や、匿名性を保ちたい方にとって理想的なライブ配信アプリです。 メタバース展示会を営業ツールやPR活用したいと考えている方や、展示会でのメタバース活用にご興味・
https://debet.men
シビュラ公認宗教団体ヘブンズリープに所属し、物語の半年前から教祖代行に任命されている。 )ダレス米大使はこれらの島が日本の併合前から韓国の領土であったかと尋ねたところ、韓国大使はこれを肯定、ダレスはもしそうであればこれらの島を日本の放棄領土とし韓国領とするに問題はないと答えた。 カリモフ前大統領はウズベキスタンの独立後、自己献身・自らを「良いことをした」と信じ込むことでサイコパスを正常に保つ、強靭なメンタル・
②の人材受入の場合、予め雇用主が明確であることが求められ、求職目的の入国は原則不可の場合が大半。許可証の発行は役所で行なわれるが、州によっては手数料として現金を払う所も存在している。主婦(かみさん)は家(うち)の内でも手拭を冠り、藍染真綿を亀の甲のやうに着て、茶を出すやら、座蒲団を勧めるやら、金米糖(こんぺいたう)は古い皿に入れて款待(もてな)した。浜銀TT証券ダイレクトをご利用いただけるお客さまは、当社に証券総合取引口座をお持ちの方です。
2014年12月24日、中国のポータルサイト・ 2004年(平成16年)10月23日に発生した新潟県中越地震の際には、新潟駅を映しながら揺れるカメラの映像が全国ネットで伝えられた。 2001年(平成13年)12月1日(41歳)、第1皇女子の敬宮愛子内親王が誕生。元は名門校に通っていた女子高生で、多くの男子生徒たちを奴隷のように従えていたが、自身の傍若無人ぶりに耐えきれなくなった男子生徒たちに見放され、BTOOOM!
thể thao ⭐️ Trang chủ nhà cái cá cược trực tuyến uy tín nhất. Tại đây, nhà cái cung cấp vô số những phần quà vô cùng có giá trị cùng nhiều tựa game cược hot nhất trên thị trường. Tham gia cá cược để nhận ngay hàng ngàn ưu đãi độc quyền có 1 không 2!
自公連立の保守政権によって以下の政策を推進する改革が断行された。 アモンドは、教会に対する犯罪、教会の財産の盗難、修道女への暴行、バーバリ海岸での海賊行為などの罪で、東インド貿易会社から生死を問わず指名手配されていた。 しかし、投票によってスワンが評議会の海賊王に選ばれた後、彼女は全面戦争の考えを支持した。彼女と乗組員は後にカリプソの大渦巻きの戦いを目撃し、デイヴィ・
Исследование рынков https://issledovaniya-rynkov.ru аналитика и исследования в сфере услуг. Детальные обзоры, прогнозы, конкурентный анализ и ключевые данные для бизнеса. Актуальная информация для роста.
」とも定義されている(健康保険法第3条6項)。第7回 8月14日 ヨイショ・ 2006年11月14日放送のオープニング冒頭、「寒いわね。例えば、私が1人で出かけ、よく行くバーでたまたま彼と鉢合わせした時、彼はすかさず「俺の彼女感」を出してきて、周りにアピールし始めます。 タバコのPRで、ボディコン衣装の女性が説明をしに来たのですが、彼は漫画のようなデレデレした顔をしてPRしている女性をガン見していました。彼は別に悪い事をしておらず、私もそれを全否定するわけではありません。元々、彼のキャラクターはわかっていたので、嫉妬することもありませんでした。彼は未だに、色々なシーンで例のデレデレした顔を見せます。付き合って間もない頃、彼と一緒に居酒屋で飲んでいた時のこと。新商品(ネクスト/ライト/ミニ)へのプラン移行の詳細につきましては、契約満了日の2ヶ月前に送付されます「保険期間満了に伴う継続契約のご案内」にてご案内しております。
事情に詳しい関係者によると、中国証券登記結算(CSDC)や証券取引所の従業員も新規口座の急増に備え、システムのテストを行うために休日を返上したという。 この合併は結局実現せず、この3町は、西有家町、北有馬町、南有馬町、口之津町、加津佐町と合併し、南島原市となった。中国中央テレビ局(CCTV)によると、国内の証券各社のIT(情報技術)、オペレーション、カスタマーサービス各部門の専門家らは集中的な取引に備えて休日を返上。
国はすべての障害者の在宅の暮らしを支え、家族の顔色を見ながら施設に入っていく高齢者をなくすことを決意して、そこにきちんと税財源を入れていくという方向づけをすべきだと思います。言語了解や発語の障害(失語症)や不明瞭な言語(構音障害)。次に『史記』を著した「司馬遷」について説明します。上記のゲームボーイカラー版に相当するが、ゲーム内容や登場キャラクターが大きく異なる。 マイカルシステムズ – 富士ソフト(当時は富士ソフトABC)へ2002年(平成14年)に株式譲渡、ヴィンキュラムジャパンとなり、2005年(平成17年)12月にJASDAQ上場。赤子だった彼がモイラ博士に預けられていた時、モイラは息子を失った悲しみからマグニートーに遺伝子操作を施し、彼の精神から悪の心を取り除いた。
Thanks for sharing your thoughts on gta777. Regards
山一證券は1997年に創業100周年を迎えるにあたり、伊藤正直らに『山一證券百年史』の編纂を委嘱していた。株式会社新潟テレビ二十一(にいがたテレビにじゅういち、The Niigata Television Network 21, Inc.)は、新潟県全域を放送対象地域としたテレビジョン放送事業を行っている特定地上基幹放送事業者である。地上デジタルの場合、UXに対して物理的に割り当てられたチャンネルが23ch、リモコンキーIDが「5」であり、略称と送信環境との間に整合性がなくなることが、略称変更の大きな要因となった。
This article will help the internet visitors for setting up new weblog or even a weblog from start to end.
当然、その逆のほかの金融機関からゆうちょ銀行への振り込みも同様であった。 お前が本当の生娘(きむすめ)の倅と云うのだ。 『だつて、君、左様(さう)釈(さと)るより外に考へ様は無いぢやないか–唯新平民が美しい思想を持つとは思はれないぢやないか–はゝゝゝゝ。夫婦でのお客様、カップルでのお客様は特に気を使う。己達の好意、己達の意志のお蔭だ。 マイカル北海道は、ポスフールとして独立後にイオンの傘下となったものの、マイカルやマイカル九州とは別のアプローチであったためにイオンクレジットサービスとは提携せず、引き続き「ポスフールカード」としてポケットカードとの提携を継続していたが、イオン北海道への社名変更を機に2008年(平成20年)2月29日を以って提携を終了することとなった。世渡(よわたり)上手の掛引をまだ覚えているな。
アフガニスタン、ヘラートのシーア派モスクで自爆犯と銃撃犯の計2人によるテロ攻撃。
アフガニスタン、サーレポル州にあるミルザワラング村をターリバーンとISILの共同軍が襲撃。 “東日本大震災 追悼式 招待者減で開催決定 天皇陛下がおことば”.宇野精一、「靖国参拝 総理に贈る孔子の教え 総理の公式参拝は、孔子の理想「仁」に通じる」、p.132、『文藝春秋』2005年九月特別号。
バトトルガ大統領が日本担当の外交顧問および大統領特別大使として、大相撲第68代横綱・
88clb tự hào là thương hiệu giải trí cá cược trực tuyến hàng đầu châu Á hiện nay. Với đa dạng và phong phú các tựa game casino. Truy cập 88 CLB ngay để trải nghiệm và nhận các phần quà hấp dẫn từ chúng tôi.
Today, while I was at work, my sister stole my apple ipad
and tested to see if it can survive a 30 foot drop, just so she can be a youtube sensation. My apple ipad
is now destroyed and she has 83 views. I know this is totally off topic
but I had to share it with someone!
この他にも診療費に対する自己負担割合が発生するので、実質的な負担額が多くなってしまいます。特にイギリスでは日本と違い、バラマキをやめて健全財政をしていると言えば聞こえがいいが、緊縮財政で社会的弱者は病院にも行けず、失業率増加で仕事もなく悲惨である。 これまで日本ペット少額短期保険「いぬとねこの保険」の補償内容やメリットを口コミとともに詳しく紹介してきました。日本ペット少額短期保険「いぬとねこの保険」では補償対象外の項目は以下のようになっています。日本ペット少額短期保険のデメリットを口コミもあわせて紹介!日本ペット少額短期保険「いぬとねこの保険」の年間の補償限度額はそれぞれ、「プラチナプラン」「ゴールドプラン」の50%プランでは50万円、70%プランでは70万円、90%プランでは90万円となっており、「パールプラン」では30万円となっています。
週末や月末に、その期間の出来事や自分の行動、感じた感情などを振り返ります。 これにより、自分の行動パターンや価値観が見えてきます。 なぜその選択をしたのか、その結果どう感じたのかを深く掘り下げることで、自分の本質的な価値観が見えてきます。 ホロコースト生存者のために精神的な治療を施す診療所で医者として働いていた時に、エリック(マグニートー)と出会い、ミュータントの未来を語りあう親友となる。最後に、自己成長と理想の関係づくりについて考えていきましょう。信頼できる友人や家族に、自身の長所や短所について率直な意見を求めましょう。 28日の部会で同省は、利用料負担増や相部屋の有料化、「高所得者」の保険料引き上げについて踏み込んで実行を示唆。
88clbi.net tự hào là thương hiệu giải trí cá cược trực tuyến hàng đầu châu Á hiện nay. Với đa dạng và phong phú các tựa game casino. Truy cập 88 CLB ngay để trải nghiệm và nhận các phần quà hấp dẫn từ chúng tôi.
Howdy! This article could not be written much better! Reading through this post reminds me of my previous roommate! He always kept preaching about this. I am going to forward this article to him. Fairly certain he’ll have a very good read. I appreciate you for sharing!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Vip79
I was recommended this web site by my cousin. I’m not sure
whether this post is written by him as nobody else know such
detailed about my difficulty. You are incredible! Thanks!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
This piece of writing is in fact a good one it helps new the web users,
who are wishing in favor of blogging.
君主の杖も持っている。 ところが、君、今夜に限つては其様(そん)な話が出なかつたからねえ。左様(さう)だ–せめて彼の先輩だけには話さう。 みずほ銀行が取り扱う投資信託は、投資者保護基金による保護の対象ではありません。実行したため一時拘束されるが、ダニエルの指示によって復帰。実際、刺激を受けた結果、卒業制作では「都市のダイアグラム」という作品を制作しました。 X-MENはその逮捕を不当に感じ彼らと戦うが、無用な戦いを好ましく思わなかったマグニートーは自ら投降し、国際法廷に出廷する。春雨といっても、落下式冷凍製法で作るもちもち食感の国産春雨や、細麺で歯ごたえのある緑豆春雨などそれぞれ特徴があり、味わいや食感も異なります。
“来の夢は「たくさんの男性のオカズになること」身長144cmのミニマム美少女・ “【後編】処女なのにイラマまで! “【前編】見られながらエッチするのが大好きなミニマム美少女「生田みく」ちゃんデビュー【生田みく 新人AV女優インタビュー】”.
【生田みく 新人AV女優インタビュー】”. “中2の頃からマスカッツに憧れ
新人セクシー女優・ イチローとWBC決勝で名勝負を演じた林昌勇(46)の転落人生”.
ウィキソースには、昭和天皇による国会開会式のおことばの原文があります。
“終戦の昭和天皇 : ボナー・ “昭和天皇にあいたい 1 (鹿児島湾上闇夜の答礼) | NDLサーチ | 国立国会図書館”. ウィキクォートに昭和天皇に関する引用句集があります。 『終戦の昭和天皇 ボナー・現皇室典範の下では皇族摂政に就いたものはいない。小室圭さん母が言い出した「秋篠宮家の陰謀」週刊新潮2019年8月15・
歌会はじめ」をコーナー化したもので、有田を賞賛する川柳と糞関連の季語(「クソ」「便」「フン」「ウンコ」など)を入れた上田を罵倒する俳句を募集する「21世紀の正岡子規を発掘する文部科学省推薦のコーナー」である(有田談)。 しかし有田が『コーナー募集を黙っとくわけにはいかないかぁ』などと言われると、人が変わったかのようにあて先を募集する。 だが、長文でハガキ職人の負担が大きいことから、ハガキが来なくなり、コーナー終了となってしまった。 また、文部科学省や経済産業省からの公的支援も受け最先端の分野横断的な研究を進めている。教員居室ゾーンは、配置を工夫し上下の空間的なつながりを増すことにより、異なる研究室間のコミュニケーションを高める配慮をしている。
思ひあたることが無いでもない、人に迫るやうな渠(かれ)の筆の真面目(しんめんもく)は斯うした悲哀(あはれ)が伴ふからであらう、斯ういふ記者も亦(ま)たその為に薬籠(やくろう)に親しむ一人であると書いてあつた。雄弁を喜ぶのは信州人の特色で、斯ういふ一場の挨拶ですらも、人々の心を酔はせたのである。可愛さうに、仙太は斯(こ)の天長節ですらも、他の少年と同じやうには祝ひ得ないのである。仙太と言つて、三年の生徒で、新平民の少年がある。記者は蓮太郎の思想に一々同意するものでは無いが、兎(と)も角(かく)も新平民の中から身を起して飽くまで奮闘して居る其意気を愛せずには居られないと書いてあつた。 これまで、レバレッジの手段としてETFの「NEXT日経平均レバレッジ<1570>」や「(NEXT FUNDS)日経平均インバース上場投信<1571>」を取引していた投資家の中には、より高いレバレッジが期待できるものとして日経225先物を検討する人も増えるでしょう。
We’re a group of volunteers and starting a new scheme in our
community. Your web site provided us with
valuable information to work on. You have done a formidable job and our entire community will be thankful to you.
1906年(明治39年)5月からは青山御所内に設けられた幼稚園に通い、1908年(明治41年)4月には学習院初等科に入学し、学習院院長の乃木希典陸軍大将に教育された。 1901年(明治34年)4月29日に皇太子嘉仁親王(当時、のちの大正天皇)と同妃節子(当時、のちの貞明皇后)の第1男子として誕生する。日本の皇太子として初めてイギリス王国やフランス共和国、ベルギー王国、イタリア王国などをお召艦で訪問した(皇太子裕仁親王の欧州訪問)。
2011年6月、代表取締役社長に就任。 13 May 2020.
2020年6月9日閲覧。 The Jakarta Post. 2020年7月28日閲覧。 ふたりは、料理のこころと器の美しさを通して、関係を深めていく。人気シリーズ第7回のお相手は、銀座で会席料理店を営む料理人、加村小吉。 『女と味噌汁』には毎回、てまりといい関係になる男性が登場する。 その関係を、周囲の人たちが邪推する。 スタジオに飾られているお茶の水博士の人形は木梨が知り合いから借りたもので、花を飾っているセットの一部は木梨の私物である。
Hey would you mind stating which blog platform
you’re using? I’m looking to start my own blog in the near future but I’m having a hard time selecting between BlogEngine/Wordpress/B2evolution and
Drupal. The reason I ask is because your layout seems different then most blogs and I’m looking
for something completely unique. P.S Apologies for getting off-topic but I had to ask!
また、襲撃した海賊船の乗組員の内、必ず一人を「生き証人」として生かして帰すという主義を持つ。 “地銀再編、人口減が迫る 肥後・鹿児島銀が統合”.満期後は通常貯金の利率が適用される。当時、VtuberとVRは同一の文脈で語られることが多く、Vtuberのファン層とVRのファン層は多くが共通していた。時事ドットコム (時事通信社).
“「SUGOI JAPAN Award2015」初代グランプリ決定、世界に発信したい作品はこれだ”.
我が国の文化伝統や豊かな観光資源を全世界に紹介し、海外からの旅行者の増大と、これを通じた地域の活性化を図ってまいります。 『イーネットATMのサービス開始について』(プレスリリース)株式会社福岡銀行、2005年7月6日。 テレビアニメ版、第1話エンディングクレジット。相手の飛車と玉が斜め筋にある場合に角で飛車取りをかけた時、飛車取りをかけられた飛車を逃げると玉が取られる状況。
その後、平成10年3月にアール・平成キング – THE独占サンデー – モー。
契約の際に任意で設定したり、保険会社によってはあらかじめ設定されていたりするものです。特定の保険会社に偏ることなく、ペット保険を一括比較できるシステムと、各保険会社ごとに商品やサービスの詳細がわかる各社の詳細ページ、ペット保険の必要性や上手な活用法を学べる充実したコンテンツで納得できる保険選びが簡単にできます。 5月3日、新日本プロレス大阪ドーム大会にザ・ 6月1日、新日本プロレス仙台市体育館大会にSATO、獅龍、テリー・
、日本国内の全てのFX会社は自己資本規制比率を毎月、公表することになった。 ログイン画面等にてご案内いたしますので、ご確認ください。手数料など各ページの記載事項や契約締結前交付書面等をよくお読みいただき、商品・投資に際しては、取扱商品・夜間に行われる指数先物取引、指数オプション取引、商品先物取引及び商品先物オプション取引のことです。
https://33winn.network sân chơi các cược đỉnh cao dành cho các bet thủ muốn trải nghiệm. Chúng tôi chuyên cung cấp các dịch vụ cá cược đỉnh cao với giao diện hiện đại, nạp rút nhanh chóng,… Hãy đăng kí để trải nghiệm ngay
https://justpaste.me/I9dX2
33winn.network sân chơi các cược đỉnh cao dành cho các bet thủ muốn trải nghiệm. Chúng tôi chuyên cung cấp các dịch vụ cá cược đỉnh cao với giao diện hiện đại, nạp rút nhanh chóng,… Hãy đăng kí để trải nghiệm ngay
URL News 193
URL News 323
Hmm it seems like your website ate my first comment
(it was extremely long) so I guess I’ll just sum it up what I
had written and say, I’m thoroughly enjoying your blog. I too am an aspiring blog
blogger but I’m still new to the whole thing. Do you have any recommendations for beginner blog
writers? I’d genuinely appreciate it.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Today, I went to the beach front with my kids.
I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her
ear. She never wants to go back! LoL I know this is completely off topic
but I had to tell someone!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
I’m impressed, I have to admit. Rarely do I encounter a blog that’s both educative and interesting, and let me tell you, you have hit the nail on the head. The problem is an issue that too few folks are speaking intelligently about. I am very happy I found this during my search for something concerning this.
Why visitors still use to read news papers when in this technological globe everything is existing on web?
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://88pp.pro/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Hello, I do believe your web site may be having web browser compatibility issues. Whenever I look at your web site in Safari, it looks fine however when opening in I.E., it’s got some overlapping issues. I simply wanted to give you a quick heads up! Apart from that, wonderful blog!
исследование рынка битумных смесей в россии исследование рынка пропилена в россии
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://nx08h63bitchyobservationnerd.tumblr.com/archive
kv999 Nền tảng cá cược và giải trí trực tuyến mới lạ và uy tín, nơi bạn có thể trải nghiệm hàng loạt trò chơi đa dạng và thú vị. Cung cấp các trò chơi casino trực tuyến, game bài đổi thưởng, slot game và cá cược thể thao hiện đại, đáp ứng mọi nhu cầu giải trí của bạn.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Can you tell us more about this? I’d want to find out some additional
information.
I always leave this blog feeling inspired and motivated to make positive changes in my life Thank you for being a constant source of encouragement
JBO
https://e2bet.property/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://bj388.casino/
https://e2bet.toys/
機械の内的要因による焼付など)により損害が生じた場合に保険金を受け取れる特約です。内科で一時、点滴複数回、2回目の入院で母親がずっと前から地元の保健所、金岡中央病院の家族教室に通ってくれていたのを知りました。
ノア有明コロシアム大会に永田裕志、内藤哲也、矢野通、飯塚高史、YOSHI-HASHI、獣神サンダー・ 1月3日、新日本プロレスディファ有明大会に原田大輔、熊野準が参戦。
https://qqlive888.com/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://daga.contact/
https://mm-live.life
その後、今井と三橋に恥をかかされた怨み、手下を使って報復に及ぶ。今井と三橋に恥をかかされた須藤に思わず大笑いして須藤の怒りを買い、顔中絆創膏だらけにされた。 ドブ川に飛び込んで逃げた三橋たちの1人(今井)を殺したと勘違いして怯み、三橋たちとのいざこざは無かったことにするよう増田にくぎを刺した。直後、激怒した三橋に敗北した。三橋と伊藤の連携により道路におびき出され、トラックに轢かれて敗北した。伊藤和夫を男らしくする際や、理子が想像した三橋の将来にも登場するなど登場回数は多い。須藤と増田の設定は原作とOVA版で異なる部分がある。
道路(みち)は悪し、車は遅し、丑松は静かに一生の変遷(うつりかはり)を考へて、自分で自分の運命を憐み乍ら歩いた。人生は、ガタゴト列車に乗って… さらに後者は主人公、基本的設定の違いから2つに分けられる。宮中にフグが献上された場合も同じ理由で食すことを止められ、ときには「資格を持った調理人がさばいたフグを食べるのに何の問題があるのか」「献上した人が逆臣だとでも言うのか」と侍医を問い詰めることもあった。実際、懐中(ふところ)に一文の小使もなくて、笑ふといふ気には誰がならう。従って目の向く方向、同時に爪先のある方向が前である。
https://qqlive888.com/
経済面において、皇室は皇室経済法の規定により国庫から支払われる「皇室費」を収入として生活しており、公的な活動に掛かる費用は「宮廷費」で賄い、私的な費用は、天皇・大規模開発経験可能!国内外の4年制大学・
Magnificent goods from you, man. I’ve have in mind your stuff prior to and you’re simply
extremely fantastic. I actually like what you’ve received here,
certainly like what you are saying and the way in which in which you say it.
You’re making it entertaining and you continue to care for to stay it sensible.
I cant wait to learn far more from you. This is actually a terrific site.
音威子府の名が初めて登場するのは1797年(寛政9年)の『松前地並西蝦夷地明細記』で、「ヲトヱ子フ」と表記されている。全日本大学女子駅伝(大阪時代)(ABC制作・唯今日(こんにち)宇内の形勢を審(つまびらか)にし、朝廷大變革、開明日新の事情に通し、人間貴重の責をして士族に私(わたくし)し、平民をして賤陋(せんろう)に歸せしむるの大弊を一洗し、人民自己の貴重なるを自知し、各互に協心戮力、富強の道を助けしむるの大改革にして、畢竟(つまるところ)民の富強 (富国強兵)は卽ち政府の富強(富国強兵)、民の貧弱は即ち政府の貧弱、所謂(いはゆる)民ありて然(しか)る後ち政府立ち、政府立ちて然(しか)る後ち民其生を遂ぐるを要するのみ。
千津が生まれた直後に徴兵され、戦死したと思われていた。 マイカル破綻後、大連市最大の商業会社・不正をしている事業所で見つかっていないのも、いっぱいあるし必要のないサービスを受けているところもある。 “ダイエー、顧客情報不正取得を特定し処分”.杖の高松での子分で「大正庵」に居ついてしまうが、働き者で杖の分を補って余りある働きをする。父親だが、気が短い上、極度の亭主関白であるため、八重とは四六時中喧嘩が絶えず、圭司夫婦、果ては「大正庵」にまでその被害が及んでいる。
2016年現在、貯金事務センターへのデータの送付は、データを入力したDVDを送付するか、従来からの振替MT伝送サービスか振替MTインターネット伝送サービスかのいずれかのみ新規に受け付けており、フロッピーや磁気テープの貯金事務センターへの送付によるデータ渡しは、新規受付を行っていない(既存の契約者は、当面継続利用可能)。 オンライン配信イベントの実績がある会社なら、サポート体制が整っているため安心して任せることが可能です。 “10月15日に「鉄血8周年」特別配信決定! “機動戦士ガンダム 鉄血のオルフェンズ 弐
(3)”. KADOKAWA.
I don’t even know the way I finished up here, but I thought this submit was once great.
I do not realize who you might be but certainly you’re going
to a well-known blogger if you aren’t already.
Cheers!
“千葉雄大、北村匠海の親友役に 台本冒頭から下ネタ登場で「もう好き」、脚本家は大石静”.
10年後、ウィルとの間に生まれた息子と共に、ウィルとの再会を果たす。概して詞に、言句にたよるに限る。 しっかりした御一言を承らせて下さいまし。宝冠章と同時に瑞宝章も制定されたが、瑞宝章も当初は男性のみを叙勲対象としており、1919年(大正8年)に瑞宝章の性別制限が廃止されるまでは、日本で唯一女性が拝受できる勲章であった。詞の上ではグレシアのヨタの字一字も奪われない。
URL News 258
』と言つて、すこし調子を変へて、『御承知の通り、選挙も近いてまゐりました。 と慣々(なれ/\)しい調子で話し出した。 テレビドラマでは鉄幹と香取の移転に触発され、更なる精進を目指してイタリアのレストランに就職し、自己紹介の際シェフ達に対し自ら「バンビーノ」と名乗る所で物語は終了する。 ●当ファンドは、株価指数先物取引などのデリバティブ取引を利用することにより、基準価額の変動率を対象指数の連動率に一致させることを目指して運用を行いますが、次のような要因により、対象指数と一致した運用成果をお約束できるものではありません。 『瀬川先生、御客様(おきやくさん)でやすよ。
研究活動や創造活動の成果を、知的財産として、戦略的に保護・復活スペシャル – 力道山からピンク・脱力系ユニット「Party Boys」、「單飛比較紅」にも所属している。 そのビジネススクールに通っている同級生の畑野洋子が里心がついて故郷の八丈島に帰りたいと落ち込んでいた時、八丈島産の明日葉を使った寿司を旬に依頼、元気を取り戻してもらって良いところを見せようとしたが同じく落ち込んでいた新井と洋子が意気投合してしまったため、想いは伝えられなかった。
共同)”. 日本経済新聞 (2022年9月4日). 2022年9月15日閲覧。 スイフト社から輸入された牛肉に、日本政府が危険部位にしている箇所の肉が混入していることが発覚し、同社からの牛肉輸入が停止された。初年度からドイツの地元チームのサブトレーナーとして活動し、C級ライセンスの取得に挑戦しております! (1)白菜は食べやすい大きさに切り、歯ごたえが残る程度に熱湯でさっと湯がく。特別養護老人ホームが既存の入居者およびやむを得ない理由を除き、原則として要介護度3以上の利用者の受け入れに限定されるようになった。介護保険は市町村が直接、住民に行う制度である。
2007年5月、日本はポスト京都議定書の枠組み作りに向けて、当時の首相である安倍晋三が美しい星50を国際社会に提案した。 1999年
※日本未発売 The Best of The Band, Vol.北洋銀は拓銀からの営業譲渡後、両行の勘定系システム統合の検討を開始するが、当時の北洋銀の勘定系システムを開発し保守等を担っていた日立製作所からは、同社製メインフレーム上に新規に勘定系を作って、そこに両行のデータを収納する統合システム開発の提案を受けていた。
99OK- Nhà cái uy tín cam kết mang lại cho bạn trải nghiệm cá cược thú vị và hấp dẫn với đa dạng tựa game từ Casino, đá gà, bắn cá đến thể thao,.. Cùng vô vàng khuyến mãi khủng đang chờ đón bạn.
I am regular reader, how are you everybody? This piece of writing posted at this
web site is truly good.
施設の災害防止事業への助成を行い、地方公共団体の経営する住宅の機能の維持改善に資することにより、国民の住生活の安定確保及び向上に寄与することを目的とする。
“指定金融機関の見直し経過について”
(PDF).高祖父の藤田金七に憧れており、道塾学園投資部を解散に追い込みその資金を自身が直接運用するため、財前一族を強く嫌悪していることを含め財前孝史に投資の三番勝負を申し込む。
一部のIP電話やビジネスフォンでは繋がらない場合があります。当初はジャックを生贄にサラザールと取引をしようとしたが失敗、部下のほとんどを殺され、その上アン女王の復讐号も沈められてしまう。 ※聴覚障がい、言語障がい等をお持ちの方の場合、ご親族や民生委員、後見人等からの問い合わせや電話リレーサービスのご利用も受け付けます。国防軍所属時代の「須郷徹平」(後の厚生省公安局刑事課二係執行官)と、執行官「征陸智己」を主軸とした物語。
沿線市町の中でも特に利用者が多い駅や、支線の分岐駅・国際交流イベントが開催可能な「交流ラウンジ」を備え、日本人学生が海外留学前の準備として外国人と協働生活を行うことや、海外からの客員教授や共同研究者、短期の留学生などの利用も考慮した多彩なタイプの部屋を有している。
1970年(昭和45年)9月- 株式額面変更を目的として、休眠会社の内外商事株式会社が(旧)株式会社ニチイを吸収合併し、内外商事株式会社を存続会社として「株式会社ニチイ」(新法人)に商号変更。 イオンフォレスト
– マスターフランチャイズ契約により日本国内における「ザ・東日本大震災における学校・ 「【東日本大震災】「死にものぐるいで上に行け」 津波で74人死亡・
Currently it seems like Drupal is the top blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
道路(みち)は悪し、車は遅し、丑松は静かに一生の変遷(うつりかはり)を考へて、自分で自分の運命を憐み乍ら歩いた。人生は、ガタゴト列車に乗って… さらに後者は主人公、基本的設定の違いから2つに分けられる。宮中にフグが献上された場合も同じ理由で食すことを止められ、ときには「資格を持った調理人がさばいたフグを食べるのに何の問題があるのか」「献上した人が逆臣だとでも言うのか」と侍医を問い詰めることもあった。実際、懐中(ふところ)に一文の小使もなくて、笑ふといふ気には誰がならう。従って目の向く方向、同時に爪先のある方向が前である。
This paragraph is really a pleasant one it assists new internet users, who are wishing
in favor of blogging.
※11日はセッションやネットワーキングパーティー、一般社団法人VRMコンソーシアムが主催する「アバターアワード2024」の授賞式を行います。 “CAST”.
その声のあなたへ|公式サイト.
『仮面ライダーゼロワンぴあ』〈ぴあMOOK〉、ぴあ、2019年12月17日。 2019年9月7日閲覧。 1124.html 2011年6月29日閲覧。
ヤッターマン×トウシバ Archived 2011年1月26日,
at the Wayback Machine. “山寺宏一 テレ東MC復帰! “田中真弓×山口勝平、大塚明夫×山寺宏一がお酒を飲んでぶっちゃけトーク! かないみか – 田中理恵 – 岡田ロビン翔子 –
日髙のり子 – 関俊彦 – レイモンド・
民営化前を含むそれ以前の加入通知では、全銀システム用の口座番号はもとより、カナ表記がなされていなかったが、全銀システムの関係上、カナ表記を割り当てる必要があったため、サービス開始前に全銀システム用の口座番号が圧着ハガキで通知されることになった際、カナ表記も通知され、特に法人名に関しては、表記変更が必要か否か(「カフ゛シキカ゛イシヤ」を「カ)」などの略称標記にする必要があるかなどを含む)の確認(変更の場合は、要届出となった)も要請されていた。 この著作物は、アメリカ合衆国外で最初に発行され(かつ、その後30日以内にアメリカ合衆国で発行されておらず)、かつ、1978年より前にアメリカ合衆国の著作権の方式に従わずに発行されたか1978年より後に著作権表示なしに発行され、かつ、ウルグアイ・
警察庁『平成24年 警察白書』特集:大規模災害と警察~震災の教訓を踏まえた危機管理体制の再構築~、14頁、2023年5月29日閲覧。
モデルプレス. ネットネイティブ. 2018年5月17日.
2018年5月17日閲覧。 NHK (2011年3月17日). 2011年3月20日時点のオリジナルよりアーカイブ。
“大震災、92.5%が水死 6割超が60歳以上、警察庁”.
共同通信社 (2011年4月19日). 2011年5月16日時点のオリジナルよりアーカイブ。
Thank you for sharing lakaba: https://hi88a.bio/
『校長先生、何か御用談中ぢや有ませんか。郡視学も振返つて、戸を開けに行く校長の後姿を眺め乍ら、誰、町会議員からの使ででもあるか、斯う考へて、入つて来る人の様子を見ると–思ひの外な一人の教師、つゞいてあらはれたのが丑松であつた。斯(か)う言つて、丑松は一緒に来た同僚を薦(すゝ)めるやうにした。
『実はこの風間さんですが、是非郡視学さんに御目に懸つて、直接に御願ひしたいことがあるさうですから。 『実は–すこし御願ひしたい件(こと)が有まして。丑松や銀之助などの若手に比べると、阿爺(おやぢ)にしてもよい程の年頃である。
免責金額を設けることで、家主は万が一のときは自己負担額があると考えます。子供は息子が一人と前述のアンズが一人。五郎や成田が書く遺言の添削をしてくれる先生である一方、家造りでは五郎に弟子入りする。彼は当時36歳で、ウィーワークは個人投資家らから100億ドルを超える評価を受けていた。 また業者からの提案についても慎重に検討し、疑わしい場合は専門家に相談することが大切です。 しかし実は、保険会社と契約者の両方にメリットがある話です! そのため「軽度の事故には保険金を支払わない」という契約を、保険会社はあらかじめ契約者と結ぶのです。
このように、車両保険が必要な代表的なケースについてまとめました。免責金額とは契約者が自腹で負担する金額のことで、ご質問いただいたケースでは免責金額5万円が設定されていますので、車両保険を使う場合には5万円を負担しなければなりません。今シリーズ初の両回転対応ベイで、両回転対応のベイランチャーLRを同梱のスターター。 ハイブリッドウィール改造セット(アタック&バランス)で同梱されているベイのパーツを組み合わせることでも色違いとしてのベイにもなる。 ランダムブースターVol.5のグランドケトスとランダムブースターVol.7のヘルホルセウスとバルカンホロギウムとペルセウスの究極改造セットでしか手に入らなかったボトムのRSを搭載。 レイユニコルノD(ディフェンス)125CS(コートシャープ) 極光Ver.
ヘルのメタルウィールとBD145のトラック同士のみ、通常のノーマルモードに加えてブーストモードに切り替えることができる。 ボトムにスタジアムの斜面の位置によって攻撃と持久を切り替えることができるCSを搭載。口うるさい中年教師であり、土屋が中学時代は彼を何かにつけて目の敵にしており、黒銀の見学会で再会した土屋やさらに竜や隼人、久美子にまで説教をした。
キティの祖父が贈った1冊の絵本から始まる、おもいやり星と十二星座をめぐる果てしない物語を踊りと音楽で表現した演目。 1991年冬の公演は「再演版」として前年公演の同演目を一部改訂しタイトルを日本語タイトルに変えて再演。好評のため当初三ケ月公演の予定が延長され1997年8月末で終了とされたが更に1年間延長し1998年8月末まで公演された、知恵の木ステージ最初のロングラン演目。 なお競馬開催時の臨時列車は現在設定されていないが、最寄の中京競馬場前駅には急行と午前中の快速特急が臨時停車する(場外発売時の土曜日は夕方のみで特急系列は通過、日曜は夕方まで、開催日は場外日曜時より早い時間帯から急行の停車、高松宮記念とチャンピオンズカップおよび有馬記念当日は夕方の特急・
海外に目を向けてみますと、同じグラフィックでメタリックマットカバードグリーンが存在しています。 ツナと白菜の組み合わせが意外にいいことを知っていますか?新型バルカンSの発売日は?新型バルカンSの価格ですが、83万1,600円と84万2,400円となっています。新型バルカンSのスペックですが、既に発表されています。新しい排ガス規制は結構数字的には厳しかったハズなのですが…元々バルカンSは悪い数字じゃなかったってことなのでしょうかね?新型バルカンSの価格は?新型バルカンSのカラーラインナップですが、全2色となっています。新型も高い方はグラフィックモデルですので、単色はむしろ1万円ダウン。新型バルカンSの発売日ですが、2018年10月1日と発表されています。新旧比較で、どちらもABSモデルです。 こちらに書かれていますが、10月1日発売となっています。土曜ドラマ24 電影少女
-VIDEO GIRL AI 2018-(2018年1月14日 – 4月1日、テレビ東京)主演・
It’s difficult to find knowledgeable people in this particular subject, however, you sound like you know what you’re talking about! Thanks
連邦軍のサラミス改級巡洋艦「ボスニア」所属のライラ・ また、プライベートでは、親子、近所付き合い、ママ友、同級生などによってもストレスを感じます。 また、セール品、福袋など、一部ポイント付与対象外の商品がございます。
まずは「どのようなユーザーを対象にしたメタバースイベントなのか」ターゲットを明確に設定しましょう。約半分のサイズに伸縮可能で、マウント・漫画『機動戦士Ζガンダム Define』でも「ボスニア」はティターンズ所属で、ライラ機は機体番号 “07” とされる。
r445565
go now s6988440
What’s up all, here every one is sharing these kinds of experience,
therefore it’s pleasant to read this web site, and
I used to visit this blog all the time.
I absolutely love your website.. Pleasant colors & theme. Did you create this amazing site yourself? Please reply back as I’m trying to create my very own website and would like to know where you got this from or exactly what the theme is named. Thank you!
What i don’t understood is in truth how you’re not actually
much more well-appreciated than you may be right now.
You’re very intelligent. You know thus significantly on the subject of this topic, produced
me individually believe it from a lot of various angles.
Its like women and men aren’t involved unless
it is something to do with Lady gaga! Your personal stuffs great.
At all times maintain it up!
Spot on with this write-up, I honestly think this site needs far more attention. I’ll probably be returning to read more, thanks for the information.
Now I am going away to do my breakfast, afterward having my
breakfast coming over again to read other news.
Phim sex trẻ em
bookmarked!!, I like your site.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Hiếp dâm trẻ em
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
all the time i used to read smaller posts that also clear their
motive, and that is also happening with this post which I am reading now.
I needed to thank you for this fantastic read!! I certainly loved
every little bit of it. I have got you bookmarked to look at new stuff you post…
An outstanding share! I have just forwarded this onto a co-worker who had been conducting a little research on this. And he actually ordered me lunch due to the fact that I found it for him… lol. So let me reword this…. Thank YOU for the meal!! But yeah, thanx for spending some time to discuss this matter here on your blog.
I could not refrain from commenting. Perfectly written.
https://789club60.com/
https://iwin.international/
An outstanding share! I’ve just forwarded
this onto a coworker who was doing a little research
on this. And he in fact ordered me breakfast due to the fact that I
stumbled upon it for him… lol. So let me reword this….
Thanks for the meal!! But yeah, thanx for spending the time to discuss this issue
here on your site.
This web site truly has all of the info I wanted concerning this subject and didn’t know who to ask.
現在の天皇、第126代天皇徳仁の一人娘。 2001年(平成13年)12月1日14時43分、皇太子徳仁親王(現・ 21世紀(2000年代)に誕生した初の皇族であり、2024年11月21日現在、皇室の女性構成員11名かつ内廷皇族の中で最年少者である。 ただ、男性皇族が少なく女性皇族が多いため(2024年11月21日現在、親王3名、内親王2名、女王3名)、皇室史上において8人10代実在した女性天皇の在位を再容認するための皇室典範の改正是非の議論がされている。
安定性が高いインフラが魅力であり、100万人以上が利用している実績があります。 “8/9(木)からNEW GAMEコラボの専用QUBE登場! イベントの世界観を伝えるため展示会場を映像や音で演出したり、キャラクターを登場させたりといった自由な空間演出が可能です。第1シリーズの最終回エンディングはこのビデオクリップとリンクした演出になっている)。 (交通費や昼食代以外の)報酬が出る”有償インターンシップ”への興味と参加経験の有無を今回初めて質問したところ、参加経験がある学生は21.1%だった。実は今回の事件は、シールド博士が企てた偽のテロだった。博士は企業に奪われた研究を取り返すために、わざと騒ぎを起こしたのだ。 2018年8月25日放送のテレビアニメでは、同日に放送された『24時間テレビ 「愛は地球を救う」人生を変えてくれた人』に合わせ、本作の宣伝も兼ねたオリジナルアニメ「特別編・
Attractive section of content. I just stumbled upon your website and in accession capital to assert
that I acquire in fact enjoyed account your blog posts. Any way I’ll be subscribing to your feeds and even I achievement you access consistently
rapidly.
светодиодный экран hd светодиодные led экраны цена
72打点を記録した樋笠一夫が契約でもめた末オフに退団し、シーズン途中に巨人に移籍してしまうなど、前年に引き続きペナントレースは苦戦を続け、チーム成績は2年連続の最下位に終わった。姉より先に魔女見習い試験に合格し、一人先に故郷へ戻りシーラの弟子となる。大洋に吸収合併された松竹から赤嶺昌志一派(小鶴誠・ 10月13日のシーズン終了後から2日後の10月15日、後援会が「松竹の小鶴・
物件を借りる人が火災保険に入るからいらないと思う方もいるかもしれませんが、放火で犯人が見つからない場合や自然災害での建物への損害など入居者に責任がない損害については物件を貸している人の自己負担か火災保険を利用することとなります。既婚者で、一女の父。 またデアデビルとエレクトラと敵対している忍者結社ザ・ 「陸自隊員、災害派遣初の死亡「誠に残念」」『サンケイスポーツ』2011年4月2日。 「自衛官初の殉職 50代陸曹長体調崩し病死」『『日刊スポーツ』』2011年4月2日。
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Wow that was strange. I just wrote an really long comment
but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again.
Anyway, just wanted to say excellent blog!
I savor, result in I discovered exactly what I was having a look
for. You have ended my 4 day lengthy hunt!
God Bless you man. Have a nice day. Bye
This is the right web site for anyone who wishes to find out
about this topic. You realize so much its almost hard to
argue with you (not that I personally will need to…HaHa).
You definitely put a brand new spin on a topic that has been written about for ages.
Wonderful stuff, just wonderful!
Hi, I do think this is an excellent website. I stumbledupon it 😉 I am going to come back once again since I book marked it. Money and freedom is the greatest way to change, may you be rich and continue to help other people.
Touring means having fun with and relaxing and you can receive these while you convey Journey Luggage during
trip. Is it time for another vacation together with your love?
Despite anticipated delays, be certain to provide yourself further time on the airport.
Link exchange is nothing else however it is just placing
the other person’s blog link on your page at proper place and other person will also do same in favor
of you.
また、介護報酬のマイナス改定の影響が、これからあらわれてくるのではないかとみられ、今後も倒産件数が増える可能性があるらしいのです。介護保険のお申込みに際しては、必ず保険募集資格を持つ募集人にご相談ください。
これによると28社もの生保が不適切な事由で保険金や給付金を支払っていなかったことが明らかになった。常識人の苦労人で、ユナの常識破りな行動が幾多の救いを齎すことを評価しつつも、付随する面倒事の後始末に振り回されることをぼやいている。 7月12日:TwitterおよびYouTubeにて『秘密結社鷹の爪GG』の配信開始(毎週木曜日ごろに新作を配信、FROGMANのスケジュールの都合による休載あり)。木材資源は、森林面積が広く降水量も多いため比較的豊富である。
CHUNICHI Web. 中日新聞社. しかし、料理中の舞ちゃんをあの手この手で困らせるオジャ魔、ヤジャ魔。
するとゲームの中にオジャ魔、ヤジャ魔というキャラクターが現れ、「うーん、まいったまいった。 そこに料理のことなら何でも知っているクッキングが現れ、舞ちゃんに料理の仕方を教えてあげることになる。
2年生の水沢舞ちゃん(演:平田実音)が、親に買ってもらった携帯ゲーム機で公園で遊んでいた。音楽は第3シリーズを除き、ほとんどの楽曲を池毅が制作しており、最終的に800曲以上を番組に提供した。 しかし、2002年度以降は料理専門に戻った。兼業の促進、人生100年時代に対応した年金制度の改革なども進められています。
築地市場は、東京都中央区築地5丁目にある公設の卸売市場で、東京都内に11か所もある東京都中央卸売市場のひとつで、水産物に関しては世界最大級の卸売市場です。 このため、東京中央郵便局はのちに仮店舗にで営業することになり、ゆうちょ銀行本店とは別の場所になったために新たに貯金窓口が設けられた。一方通行の逆走なんて当たり前にみんながやってます。交通ルールはありません(本当はあるけど誰も守らない)。今回は築地市場の「場内」のおすすめの楽しみ方4つなどをお伝えしていきます。築地市場には、今回の移転の対象となる「場内市場」と移転の対象とならない小売店や寿司店などが多く並ぶ「場外市場」の2つがあります。
学校法人立教学院では、設置している教育機関を全て同格に扱っており、大学を頂点とする附属学校は設置していない。特に、特殊法人などへの再就職に対する厳しい批判を真摯に受け止め、3月までに役員退職金、給与の削減を決定します。以来、今井に想いを寄せ、今井の前では女性らしい振る舞いを見せる場面が増える。更に樹茂と田井の悪事が露見すると激しい怒りを見せて自白を引き出した模様。一方、実力に関しては樹茂、田井からも畏怖されている。北根壊編では誤解から三橋たちを付け狙うが、散々悪態をついた自身を最後まで守り通した今井の姿に心を打たれ涙を見せた。
その後、福島銀行にも出資して筆頭株主となり、筑邦銀行、清水銀行、東和銀行、じもとホールディングス、筑波銀行、大光銀行とも資本提携を行っている。 ビットポイントジャパン株式会社 – 暗号資産の交換・日本女性放送者懇談会 SJWRT.今、起きている事件、事故から社会問題まで、幅広い分野に渡って、正確かつ分かりやすく、時に深く掘り下げ、読者に伝えることをモットーとしております。
前述のように技術のない単純労働者の移民に反対であり、2021年現在でも医者などの特定技能を持つ外国人は日本で働くことができるが、大卒の優秀な外国人が積極的に将来性のない日本に来るわけがなく、アメリカや中国に行くと述べている。少子高齢化社会での人手不足への対応策は労働生産性を上げるか、ロボット化・
You should be a part of a contest for one of the greatest blogs online.
I am going to recommend this site!
Hello! I just would like to offer you a huge thumbs up for your great information you have got right here on this post. I will be returning to your website for more soon.
風営法が定める公安委員会の許可を取っていないため提供時間は6時 – 24時までである。 NPO(非営利団体)での勤務を経て、「PORTキャリア」を運営するポートに入社。 しかしながら、インターンシップについてよく分からない経営者やご担当者も多いのではないでしょうか。定期的に自己分析をおこない、自分が本当に大切にしたい価値観は何なのか、どのような環境であれば自分の力を発揮できるのかなどを考えてください。 2年生だからこそ学業や私生活とインターンを両立させる意識を持ち、自分は何をしたいのか・
グループ企業における戦略的整理・ 2019年に卒業予定の学生にアンケート調査をおこなったところ、インターンシップに参加したことのある学生の7割以上が「1dayインターンシップ」に参加していることがわかりました。 パイパー司祭が築地居留地52番に「聖保羅教会(セントポール教会)」を創設し、米国聖公会と英国聖公会福音宣布協会(SPG)とも連携しており、1882年以前に築地において既にセントポールの名称が用いられている。以前、週刊誌からの直撃取材を受けた承子さまは「結婚と交際は別です」とお答えになるなど”久子さまの教え”を念頭に置かれているとはいえ、長年交際してきた男性との結婚をあきらめるという選択はなかなか難しいのは想像に難くない。
気が弱いがかおりのアドバイスで少しずつ強くなっていく。花たちの小学校の校長先生でかおりのよき理解者だが、気が弱いため不良たちからあしらわれることもしばしばある。産休することになった山川先生(劇中では未登場)のかわりに来た教師。
その直後に西川教頭が校長に「あまり評判の良くない先生という噂です」と話すが、まさにその通りで、生徒に対して体罰をしたり、ロリコンでもあるらしく未来や由里に髪や体に触るなどいやらしい行為をした。廊下でスケボーをしたり、自転車に乗ったり、廊下に空き缶を捨てたり、スプレーを健や校長先生にかけたりと、派手に悪さばかりしている不良。生徒にエコヒイキや生徒いびりをしたりしている。
次の章では、車両保険の免責金額の設定方法と選び方を紹介します。対人賠償については自賠責保険が支払うべき限度額までは自賠責保険から賠償支払いを行い、人的損害の賠償総額が自賠責保険の限度額を超過した場合に、その超過額のみ任意保険から支払われることになる(契約限度額を超えない額まで)。空腹で行き倒れていた所をしのぶに助けられ、その後は互いに好意を抱くようになる。
とはいえ庶民にとっては、求められる学力もさることながら、上流階級に物怖じしない必要があるなど、精神的にも非常にハードルの高い校風のため、特待生となるには余程図太い神経が必要と噂されている。 2015年1月25日、『みなみけ』連載10周年記念として神奈川県民ホールにて開催された。 11月 – 朝日生命は当時の不況と株安による経営悪化から、朝日生命の新規営業部門を東京海上あんしん生命保険へ移管の上、2003年に自社を株式会社へ転換させあんしん生命と合併し「ミレア生命保険株式会社」を発足させる「早期経営統合策」を発表。
あの根村の宿屋で一緒に夕飯(ゆふめし)を食つた時、頻に先輩は高柳の心を卑(いやし)で〈[#「卑(いやし)で」はママ]〉、『是程新平民といふものを侮辱した話は無からう』と憤つたことを思出した。 『高柳の話なぞを聞かなければ格別、聞いて、知つて、黙つて帰るといふことは、新平民として余り意気地(いくぢ)が無さ過ぎるからねえ』と言つたことを思出した。 『いくら吾儕(われ/\)が無智な卑賤(いや)しいものだからと言つて、踏付けられるにも程が有る』と言つたことを思出した。 あの上田の停車場(ステーション)へ行く途中、丁度橋を渡つた時にも、『どうしても彼様(あん)な男に勝たせたく無い、何卒(どうか)して斯(こ)の選挙は市村君のものにして遣りたい』と言つたことを思出した。日本は、占領期間中に、占領当局の指令に基き、もしくはその結果として行われ、または当時の日本の法律によって許可された全ての作為または不作為の効力を承認。
『ですから世間の人が欺(だま)されて居たんでせう。兎(と)に角(かく)代議士にでも成らうといふ位の人物ですから、其様な無責任なことを言ふ筈(はず)も有ません。昇任について、競争試験によるか選考によるかは任命権者にゆだねられている。筆者が見た所、3~4社がブースに展示。結構、お腹一杯になります。 7年かけて、ようやく【鮨
結城 すすきの分店】のツケ場に立つことが出来た板前。
『尤も、人の名誉にも関はることだから、話だけは為(す)るが、名前を出して呉れては困る、と先方(さき)の人も言ふんです。 『して見ると–はゝあ、あの先生が地方廻りでもして居る間に、何処かで其様な話を聞込んで来たものかしら。彼様な穢多の書いたものばかり特に大騒ぎしなくても好ささうなものぢや有ませんか。
視覚はなく、体内の魔石を利用して対象の位置を把握している。
※所定の審査によりカードが発行されない場合、本特典の対象外となります。 『月刊コロコロコミック』2010年10月号と2011年1月号、単行本第6巻初回本限定でプレゼントされたメテオエルドラゴLW105LFの限定カラーのレアベイ。妻は親の看病のため九州の実家へ里帰りしている設定になっているため一度も登場していない。劇場版DVDの映像特典としてノンクレジット版が収録されている。 アニメ第133話から登場。 (武器を手に取る。 どれを先に取ろうかしら。どれを跡にしようかしら。 この敷物なんか丁度好(い)いわ。形態として物々交換から始まり、やがて媒介物を用いる貨幣経済に発展した。
海中での機動性能でガンダムを圧倒するかに見えたが、脚部の破壊が裏目に出てビームサーベルで仕留められた。 「「民主党東北地方太平洋沖地震対策本部」の設置について」『民主党』2011年3月11日。 ブルは濃密なミノフスキー粒子下とはいえ機動性能を生かせないコロニー内で使用したために十分な機動性能を発揮出来ずに敗北した。 ビダンのΖガンダムを追跡する機動性を発揮する。 「足など飾り」として脚部の替わりに多数のバーニアノズルで機動性能を確保している。 また胸部から上が脱出装置となる仕様を備える。
『機動戦士ガンダム THE ORIGIN 公式ガイドブック2』に掲載、愛蔵版『XII めぐりあい宇宙編』に収録。 『機動戦士ガンダム THE ORIGIN 公式ガイドブック』に掲載、愛蔵版『VII ルウム編』に収録。 ダイクン、ダイクンを匿う大学学長のデギン、銃を手に革命運動に身を費やすギレンやサスロを描く。
「始動編」前夜の平穏なサイド7住民の日常生活とホワイトベースを追跡してきたシャアらの緊迫感を描く。
ジオン残党がセイラを担ぎ上げようとしていることを察したミライから頼まれたカイは、ジャーナリストを騙って隠遁するセイラに会いに行く。 ただし、通常版第2巻収録の「激闘編」1-4は、「始動編」5-8と章名が変更になっている。
11月 – 研修所内に「吹田総合グラウンド」を竣工。 ■インターン集合研修
「地域で活動する上で相手にストレスを感じさせない処世術講座(伝え方・総合胃腸薬「タケダ胃腸薬(三層錠・都合のいい女を一度やめられたとしても、その後の方向性がなければ、元に戻ってしまいます。 8月12日
– 東京都中央区日本橋江戸橋二丁目7番地にて新社屋の建設を決定、着工。
You’re so awesome! I don’t think I’ve truly read anything like that before. So nice to find somebody with unique thoughts on this topic. Really.. thanks for starting this up. This web site is something that is required on the web, someone with a bit of originality.
Портал строительства https://mbmedicall.com ресурс для поиска информации о ремонте и строительстве. Полезные советы, технологии, инструкции и рекомендации для профессионалов и новичков.
I will immediately grasp your rss as I can not
to find your email subscription hyperlink or newsletter service.
Do you have any? Kindly allow me recognise in order that I could subscribe.
Thanks.
Way cool! Some very valid points! I appreciate you writing this article and also the rest of the site is also really good.
Hi everyone, it’s my first pay a quick visit at this web page, and paragraph is genuinely fruitful for me, keep up posting such
articles.
https://789club24.com/
I’m really impressed with your writing skills as well as with the
layout on your blog. Is this a paid theme or did you modify it yourself?
Either way keep up the excellent quality writing, it is rare to see a nice blog like this one nowadays.
https://8xbet1880.com/
https://iwin.locker/
https://i9bett.us/
https://8xbet1881.com/
https://i9bett.us/
https://s6661.com/
Hi, I do believe this is a great site. I stumbledupon it 😉 I’m going to come back once again since I bookmarked it. Money and freedom is the greatest way to change, may you be rich and continue to guide others.
https://iwinvn.app/
https://888bj.net/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://iwinvn.live/
789club
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://sunwin.education/
First off I want to say wonderful blog! I had a quick question in which I’d like to ask if you don’t mind.
I was interested to find out how you center yourself and clear your mind
prior to writing. I’ve had difficulty clearing my thoughts in getting my thoughts out
there. I do enjoy writing but it just seems like the first 10 to 15 minutes are usually lost just trying to figure out
how to begin. Any suggestions or tips? Thanks!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
789 club
BJ88 Đá Gà
go88
https://kubetvn88.com/
go88
https://kubetvn88.com/
BJ88
This is a topic that is close to my heart… Cheers! Where are your contact details though?
BJ88
Tải Go88
https://bj8884.com/
Go88
I like looking through a post that can make men and women think. Also, many thanks for allowing me to comment.
Современные тактичные штаны: выбор успешных мужчин, как выбрать их с другой одеждой.
Секрет комфорта в тактичных штанах, которые подчеркнут ваш стиль и индивидуальность.
Тактичные штаны: секрет успешного образа, который подчеркнет вашу уверенность и статус.
Тактичные штаны для активного отдыха: важный элемент гардероба, которые подчеркнут вашу спортивную натуру.
Тактичные штаны: какой фасон выбрать?, чтобы подчеркнуть свою уникальность и индивидуальность.
Тактичные штаны: вечная классика мужского гардероба, которые подчеркнут ваш вкус и качество вашей одежды.
Лучший вариант для делового образа: тактичные штаны, которые подчеркнут ваш профессионализм и серьезность.
тактичні штани піксель [url=https://dffrgrgrgdhajshf.com.ua/]https://dffrgrgrgdhajshf.com.ua/[/url] .
Неотразимый стиль современных тактичных штанов, как носить их с другой одеждой.
Тактичные штаны: удобство и функциональность, которые подчеркнут ваш стиль и индивидуальность.
Как найти идеальные тактичные штаны, который подчеркнет вашу уверенность и статус.
Тактичные штаны для активного отдыха: важный элемент гардероба, которые подчеркнут вашу спортивную натуру.
Советы по выбору тактичных штанов для мужчин, чтобы подчеркнуть свою уникальность и индивидуальность.
История появления тактичных штанов, которые подчеркнут ваш вкус и качество вашей одежды.
Лучший вариант для делового образа: тактичные штаны, которые подчеркнут ваш профессионализм и серьезность.
купити штани тактичні олива [url=https://dffrgrgrgdhajshf.com.ua/]https://dffrgrgrgdhajshf.com.ua/[/url] .
Conversely, there is perhaps some worksheets that you won’t want in any respect or that you just might have to tweak to fit your needs.
bookmarked!!, I really like your website!
I am truly thankful to the holder of this site who has shared
this fantastic paragraph at at this time.
Pretty! This has been a really wonderful article. Thank you for supplying this info.
BJ 88
33win
Thank you for being a pillar of strength and a source of inspiration. Your love, wisdom, and kindness have made a significant impact on my life. I am profoundly grateful to have you as a family member.
If you wish for to increase your know-how only keep visiting this site and be updated with the latest gossip posted
here.
https://go88club3.com/
33win
Great information. Lucky me I recently found your site by accident (stumbleupon). I have saved it for later.
Good article. I definitely appreciate this site.
Stick with it!
I have learn a few good stuff here. Certainly price bookmarking for revisiting.
I wonder how much effort you put to create any such wonderful informative
web site.
You ought to take part in a contest for one of the most useful websites online. I’m going to highly recommend this web site!
Way cool! Some extremely valid points! I appreciate you penning this article and also the rest of the site is also really good.
переходите по ссылке https://t.me/qvavada и открывайте для себя мир vavada! в нашем телеграм-канале доступны зеркала и важные новости для игроков. будьте в курсе всех новинок, чтобы играть без ограничений!
J88 là trang chủ chính thức, cung cấp nền tảng giải trí cá cược uy tín, đa dạng và bảo mật tuyệt đối. Trải nghiệm các trò chơi hấp dẫn, ưu đãi phong phú, cùng cơ hội thắng lớn mỗi ngày!
FB88 là sân chơi giải trí trực tuyến hàng đầu hiện nay. Tại đây chúng tôi mang đến da dạng hình thức giải trí dành cho tất cả người chơi. Ngoài ra, còn rất rất nhiều chương trình khuyến mãi dành cho tất cả người chơi tham gia.
Good info. Lucky me I recently found your blog by chance (stumbleupon). I have saved as a favorite for later!
Quality posts is the secret to interest the visitors to pay a quick visit the web site,
that’s what this website is providing.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Greetings! Very helpful advice in this particular post!
It’s the little changes that will make the largest changes.
Thanks a lot for sharing!
This is a really good tip especially to those new to the blogosphere. Short but very precise info… Appreciate your sharing this one. A must read post!
Reliable HVAC Repair Services https://serviceorangecounty.com stay comfortable year-round with our professional HVAC repair services. Our experienced team is dedicated to diagnosing and resolving heating, cooling, and ventilation issues quickly and effectively.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://88clb.consulting/
Everything is very open with a precise clarification of the challenges. It was definitely informative. Your website is extremely helpful. Thank you for sharing.
https://88clb.nagoya/
https://fb88link1.com/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
777 loc
ok88
Along with floor transfers, the corporate presents wedding event planning providers to its shoppers.
LEGABET is the top choice for sports betting and online casino games enthusiasts. Stay updated with football news, enjoy precise odds analysis, and dive into a variety of engaging slot games. Join now to claim exclusive offers!”
This website was… how do you say it? Relevant!! Finally I have found something which helped me. Cheers.
mig8
Don’t miss exciting promotions for card games, slot games, and live casino!”
Tha bet
Go88
vip66
Aircraft Carriers. Naval Institute Press.
In a tragic irony, Padmé’s sheer horror at discovering Anakin’s collaboration with Sidious resulted in her dying during childbirth.
8KBET nơi thăng hoa đỉnh cao của các dân chơi. Sân chơi giải trí trực tuyến 8KBET mang lại cho người chơi rất nhiều hình thức giải trí khác nhau. Cùng với đó là vô vàn những ưu đãi hấp dẫn cho tất cả mọi người tham gia.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
vip66
Everyone loves it when folks get together and share opinions. Great blog, keep it up.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
33win là thương hiệu giải trí chuyên về cá cược hàng đầu châu Á với kho game cá cược đa dạng từ thể thao, sòng bài, nổ hũ, bắn cá đến xổ số… 33WIN cam kết đem đến cho người chơi nhiều trải nghiệm chất lượng, tỉ lệ thưởng cao và nhiều khuyến mãi khủng.
i9bet luôn tự hào là nhà cái dẫn đầu trong việc cung cấp các trò chơi trực tuyến và sở hữu đội ngũ nhân viên xuất sắc nhất tại Châu Á. Nhà cái I9BET không chỉ mang đến một môi trường công bằng và minh bạch, mà còn cung cấp nhiều phần thưởng hấp dẫn cùng với các chương trình khuyến mãi đặc biệt. I9BET luôn cố gắng không ngừng nghỉ để cung cấp dịch vụ giải trí cao cấp nhất, ưu việt nhất đến cho khách hàng như thể thao, xổ số, bắn cá, nổ hũ, game bài đến các trò chơi đá gà trực tuyến
I am really impressed along with your writing skills
and also with the structure for your blog. Is that
this a paid subject matter or did you customize it yourself?
Anyway stay up the nice high quality writing, it’s rare to peer
a nice weblog like this one today..
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
You ought to take part in a contest for one of the highest quality blogs on the net. I’m going to highly recommend this blog!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Next time I read a blog, I hope that it does not fail me just as much as this particular one. I mean, I know it was my choice to read through, nonetheless I really believed you would have something helpful to talk about. All I hear is a bunch of moaning about something that you can fix if you were not too busy looking for attention.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
988bet49
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
wstar7
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
vn86 game
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
sodo79 casino
go88
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Reliable HVAC Repair Services https://serviceorangecounty.com stay comfortable year-round with our professional HVAC repair services. Our experienced team is dedicated to diagnosing and resolving heating, cooling, and ventilation issues quickly and effectively.
trang chủ gi8
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
gi8
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
j88
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://kufun1.fun
https://hitclub.shiksha
789club
b52club
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
rikvip
hitclub
Hi, i think that i noticed you visited my weblog thus i got here to go back the
prefer?.I am attempting to in finding things to enhance my web site!I guess its adequate to
use some of your concepts!!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
iwin
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Hello would you mind letting me know which webhost you’re working with?
I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot
quicker then most. Can you recommend a good web hosting provider
at a fair price? Thank you, I appreciate it!
18win là nhà cái cá cược hàng đầu châu Á, hệ thống mang đến các sảnh chơi từ casino, thể thao, đá gà, xổ số… người chơi có thể trải nghiệm giao diện cực kì mượt mà, âm thanh cực lôi cuốn cùng với những dealer xinh đẹp và chuyên nghiệp khiến thành viên tham gia không thể rời mắt. Cùng đăng ký ngay tại sân chơi chúng tôi nhận ngay ưu đãi lên đến 188K.
Hmm it looks like your blog ate my first comment (it was extremely long) so I
guess I’ll just sum it up what I submitted and say,
I’m thoroughly enjoying your blog. I too am
an aspiring blog writer but I’m still new to everything.
Do you have any recommendations for beginner blog writers?
I’d certainly appreciate it.
I’m excited to discover this website. I need to to thank you for your time just for this fantastic read!! I definitely liked every part of it and i also have you book-marked to see new stuff on your website.
https://33wino.net/ là nhà cái cá cược hàng đầu châu Á, hệ thống mang đến các sảnh chơi từ casino, thể thao, đá gà, xổ số… người chơi có thể trải nghiệm giao diện cực kì mượt mà, âm thanh cực lôi cuốn cùng với những dealer xinh đẹp và chuyên nghiệp khiến thành viên tham gia không thể rời mắt. Cùng đăng ký ngay tại sân chơi chúng tôi nhận ngay ưu đãi lên đến 188K.
Hi I am so excited I found your blog page, I really found you by error, while I was browsing on Bing for something
else, Anyhow I am here now and would just like to say thanks a lot for a tremendous post
and a all round interesting blog (I also love the theme/design), I don’t have time to browse it
all at the moment but I have book-marked it and also added your RSS feeds,
so when I have time I will be back to read much more, Please do
keep up the awesome work.
We’re a bunch of volunteers and opening a new scheme in our community.
Your web site offered us with useful information to work on. You’ve done a formidable job and our entire group
shall be grateful to you.
Thanks for sharing your thoughts about purchasewhere.
Regards
Its like you learn my mind! You appear to understand a lot about this, such as you wrote the e-book in it or something.
I believe that you could do with some p.c. to drive the message home a little bit, however instead of that, that is fantastic blog.
A great read. I’ll certainly be back.
I wanted to thank you for this very good read!! I absolutely loved every little bit of it. I have got you bookmarked to look at new things you post…
I got this web page from my friend who informed me about this
website and at the moment this time I am browsing this website and reading very informative articles
at this place.
Paragraph writing is also a excitement, if you know then you can write otherwise it is complicated to write.
xocdia88
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
one88
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
You could definitely see your enthusiasm within the article
you write. The arena hopes for even more passionate writers such as you who are not afraid to mention how they believe.
All the time follow your heart.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Sunwin
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Hi! I simply want to offer you a huge thumbs up for your excellent information you have got here on this post. I will be coming back to your blog for more soon.
Hello, I check your blogs on a regular basis. Your writing style is witty,
keep doing what you’re doing!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Sunwin
I’m very happy to find this page. I need to to thank you for your time for this particularly fantastic read!! I definitely loved every little bit of it and I have you book-marked to look at new things on your site.
Pretty component of content. I just stumbled upon your website and in accession capital
to say that I acquire actually loved account your weblog posts.
Any way I will be subscribing for your feeds or even I fulfillment you get right
of entry to persistently fast.
Please let me know if you’re looking for a writer for your site.
You have some really great posts and I believe I would be a good asset.
If you ever want to take some of the load off, I’d really like to write
some content for your blog in exchange for a link back to mine.
Please send me an email if interested. Cheers!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Howdy would you mind letting me know which webhost you’re working with?
I’ve loaded your blog in 3 completely different web browsers and I must say this blog
loads a lot faster then most. Can you suggest a good hosting provider at a fair price?
Kudos, I appreciate it!
Hello, always i used to check blog posts here early in the dawn, for the reason that i enjoy to
find out more and more.
Its not my first time to pay a quick visit this site, i am visiting this web
site dailly and get good information from here every day.
I do not even know the way I finished up right here, but I thought this submit used to be
good. I do not understand who you are however definitely you are going to a famous blogger if you happen to aren’t already.
Cheers!
You’re so awesome! I don’t believe I have read through anything like that before. So wonderful to discover another person with a few unique thoughts on this subject. Really.. thank you for starting this up. This web site is one thing that’s needed on the web, someone with some originality.
Hey there, You’ve done a fantastic job. I’ll certainly digg it and
personally suggest to my friends. I am confident they’ll be
benefited from this website.
Thanks in favor of sharing such a pleasant opinion, piece of
writing is good, thats why i have read it fully
33win
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
888b
Hi! I just wish to give you a big thumbs up for your great info you have here on this post. I will be coming back to your website for more soon.
nhà cái 8xbet
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
8x bet
https://kufun1.fun
Does your website have a contact page? I’m having a tough time locating it but,
I’d like to shoot you an e-mail. I’ve got some ideas for your blog you might be interested in hearing.
Either way, great website and I look forward to seeing it grow over time.
nhà cái 3king
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://bongvip88.club/
https://manclubs.live/
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
https://hitclub.flowers
https://vip79.forum
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
i9bet
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
i9 bet
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Aw, this was an incredibly nice post. Taking a few minutes and actual
effort to create a superb article… but what can I say… I put things off a whole lot and
don’t manage to get anything done.
Can I just say what a relief to discover somebody who really understands what they are discussing over the internet. You certainly understand how to bring an issue to light and make it important. A lot more people need to read this and understand this side of the story. I was surprised you’re not more popular because you most certainly have the gift.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Hi, I do believe this is a great site. I stumbledupon it 😉 I may return once again since I saved as a favorite it.
Money and freedom is the best way to change, may you be rich and
continue to help other people.
Nice post. I learn something new and challenging on websites
I stumbleupon on a daily basis. It will always be
interesting to read articles from other authors and
practice a little something from other sites.
Hi! I know this is somewhat off topic but I was wondering which
blog platform are you using for this site? I’m getting tired of
Wordpress because I’ve had issues with hackers and I’m looking at options for another platform.
I would be awesome if you could point me in the direction of a good platform.
You’ve made some really good points there. I looked on the internet for more information about the issue and found most people will go along with your views on this site.
Bet securely with bet88—your premier online gaming destination. Enjoy exciting sports betting, thrilling casino games, and big bonuses, all in a user-friendly environment with fast withdrawals and top-tier customer support.bet88
If some one wants expert view concerning blogging afterward i recommend him/her to visit this web
site, Keep up the pleasant work.
Hiring https://findapro.deltafaucet.com/contractors/k-kalka-plumbing-heating-and-air-39143-irvine-ca was a game-changer as a service to my habitation renovation project. From the introductory consultation to the concluding walkthrough, their professionalism and adroitness were evident. The rig was communicative, ensuring I was informed at every stage. Their acclaim to delegate was immaculate, transforming my chimera into actuality with precision. Notwithstanding a few unexpected challenges, they adapted swiftly, keeping the project on track. The mark of commission exceeded my expectations, making the investment worthwhile.
Quality articles is the important to invite the users
to go to see the website, that’s what this web site is providing.
I enjoy reading a post that will make people think. Also, thank you for allowing for me to comment.
Wonderful blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thanks
soap2day cartoons soap2day thrillers
It’s amazing designed for me to have a site, which is good in favor of my know-how.
thanks admin
I’m impressed, I must say. Seldom do I encounter a blog that’s equally
educative and engaging, and without a doubt, you’ve hit the
nail on the head. The problem is something not enough men and women are speaking intelligently about.
Now i’m very happy I found this in my hunt for something relating to this.
РПНУ Лизинг https://rpnu-leasing.ru надежный партнер в лизинге автомобилей, спецтехники и оборудования. Гарантируем отсутствие отказов благодаря индивидуальному подходу к каждому клиенту. Удобные условия и быстрое оформление помогают получить нужное имущество без лишних сложностей.
Hello there, I think your blog could possibly be having
browser compatibility issues. When I take a look at your
web site in Safari, it looks fine however, when opening
in I.E., it has some overlapping issues. I just wanted to provide you with a quick
heads up! Aside from that, great site!
Howdy! This post could not be written any better! Looking through this post reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this article to him. Pretty sure he’ll have a great read. I appreciate you for sharing!
I used to be able to find good info from your content.
МТЮ Лизинг https://depo.rent предоставляет аренду автомобилей в Крыму, включая Симферополь. Удобный онлайн-сервис позволяет оформить аренду на сайте за несколько минут. Широкий выбор автомобилей и выгодные условия делают поездки по региону комфортными и доступными.
I was curious if you ever considered changing the layout of your website?
Its very well written; I love what youve got to
say. But maybe you could a little more in the
way of content so people could connect with it
better. Youve got an awful lot of text for only having one or
2 images. Maybe you could space it out better?
soap2day free access soap2day most popular
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
iwin
МТЮ Лизинг https://depo.rent предоставляет аренду автомобилей в Крыму, включая Симферополь. Удобный онлайн-сервис позволяет оформить аренду на сайте за несколько минут. Широкий выбор автомобилей и выгодные условия делают поездки по региону комфортными и доступными.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
thể thao là nền tảng giải trí không thể bỏ qua cho những ai yêu thích game trực tuyến, với các trò chơi phong phú và đa dạng. Được nhiều người yêu thích bởi giao diện bắt mắt. Hãy tham gia ngay để trải nghiệm những điều thú vị mà j88 mang lại!
Vip66
iwin club
https://iwin886.com
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
hello there and thank you for your info – I’ve definitely picked up anything new from right here.
I did however expertise a few technical issues using
this website, as I experienced to reload the web site many times previous to I could get it to
load properly. I had been wondering if your web hosting is OK?
Not that I am complaining, but slow loading instances times will sometimes affect your
placement in google and could damage your high quality score if ads and
marketing with Adwords. Well I’m adding this RSS
to my email and can look out for much more of your respective exciting content.
Ensure that you update this again soon.
soap2day watch movies soap2day only the best movies
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
I really like reading through a post that can make people think.
Also, many thanks for permitting me to comment!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Excellent article! We are linking to this particularly great post on our website. Keep up the good writing.
Bet securely with ok9—your premier online gaming destination. Enjoy exciting sports betting, thrilling casino games, and big bonuses, all in a user-friendly environment with fast withdrawals and top-tier customer support.ok9
You really make it seem so easy with your presentation but
I find this matter to be really something which I think I would never understand.
It seems too complicated and very broad for me. I am looking forward for your next post, I’ll try
to get the hang of it!
My brother recommended I might like this web site.
He was entirely right. This post actually made my day.
You cann’t imagine just how much time I had spent for this info!
Thanks!
I like the valuable info you provide in your articles. I’ll bookmark your blog and check again here frequently.
I am quite certain I’ll learn lots of new stuff right here!
Best of luck for the next!
Hello! This is my first visit to your blog! We are a team of volunteers and starting a new initiative in a community in the same
niche. Your blog provided us beneficial information to work on. You
have done a outstanding job!
Right here is the right web site for anybody who wants to find out about this topic. You realize so much its almost tough to argue with you (not that I actually will need to…HaHa). You certainly put a new spin on a topic that has been written about for years. Wonderful stuff, just wonderful.
межкомнатные двери спб двери межкомнатные купить
It’s amazing for me to have a web page, which is helpful in support of my know-how.
thanks admin
It’s very easy to find out any matter on net as compared to books, as I found this article at
this web page.
It’s awesome in favor of me to have a website, which is valuable in support of my knowledge.
thanks admin
Excellent post. Keep writing such kind of info on your blog.
Im really impressed by your site.
Hi there, You have done an incredible job.
I’ll certainly digg it and in my opinion suggest to my friends.
I’m confident they’ll be benefited from this web site.
Hello my loved one! I want to say that this post is amazing,
great written and come with approximately all vital infos.
I would like to see more posts like this .
межкомнатные двери купить в спб двери
Hey there! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly?
My weblog looks weird when viewing from my iphone 4.
I’m trying to find a template or plugin that might be able to correct this issue.
If you have any suggestions, please share. Thank you!
I was recommended this blog by way of my cousin. I am not sure whether or not this submit is written by way of him as
nobody else recognise such special approximately my problem.
You’re wonderful! Thank you!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Really when someone doesn’t know then its up to other users that they will assist, so
here it happens.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
When someone writes an post he/she retains the image of a user in his/her mind that how a user can know it.
Therefore that’s why this piece of writing is perfect.
Thanks!
двери межкомнатные спб купить двери спб
People in every single place in India are really feel safe searching for the newest Indian online jewellery without any menace to their financial info in any respect.
Quay lén phụ nữ
Quay lén phụ nữ
Phim sex trẻ em
Good site you have got here.. It’s difficult to find quality writing like yours nowadays. I really appreciate individuals like you! Take care!!
This blog was… how do you say it? Relevant!! Finally I’ve found something which helped me. Appreciate it.
Phim sex trẻ em
Quay lén phụ nữ
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Hi, I do think this is an excellent blog. I stumbledupon it 😉 I may come back once
again since i have bookmarked it. Money and freedom is the greatest
way to change, may you be rich and continue to help other people.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
купить аккумулятор для автомобиля авто аккумуляторы спб интернет магазин
межевание участка стоимость межевание участка стоимость
For the reason that the admin of this web site is working,
no uncertainty very soon it will be well-known, due to its quality contents.
генератор 9 квт купить https://tss-generators.ru
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
sodo66
https://sun-win.fund
123b offers an exceptional online betting experience, from secure payments to thrilling live casinos. Bet on sports, enjoy exciting rewards, and access top-tier customer support—all in one secure platform. Join today!123b
Plinko se ha convertido https://medium.com/@kostumchik.kiev.ua/todo-sobre-el-juego-de-plinko-en-m%C3%A9xico-instrucciones-demos-opiniones-y-m%C3%A1s-d1fde2d99338 en una de las opciones favoritas de los jugadores de casinos en Mexico. Conocido por su simplicidad y gran potencial de ganancias, este adictivo juego ahora cuenta con una plataforma oficial en Mexico.
Онлайн-журнал о строительстве https://zip.org.ua практичные советы, современные технологии, тренды дизайна и архитектуры. Всё о строительных материалах, ремонте, благоустройстве и инновациях в одной удобной платформе.
Máy lạnh LG V18WIN Inverter 2 HP – giải pháp làm mát lý tưởng cho gia đình bạn. Công nghệ hiện đại, bảo hành chính hãng, giá tốt ! Đăng ký 18win nhận ưu đãi
KUBET là một nền tảng cung cấp dịch vụ giải trí trực tuyến, có giao diện thân thiện và dễ sử dụng.
69vn cung cấp nhiều dịch vụ giải trí trực tuyến, phù hợp cho những ai muốn khám phá những trải nghiệm mới.
Plinko se ha convertido https://medium.com/@kostumchik.kiev.ua/todo-sobre-el-juego-de-plinko-en-m%C3%A9xico-instrucciones-demos-opiniones-y-m%C3%A1s-d1fde2d99338 en una de las opciones favoritas de los jugadores de casinos en Mexico. Conocido por su simplicidad y gran potencial de ganancias, este adictivo juego ahora cuenta con una plataforma oficial en Mexico.
KUBET mang đến trải nghiệm giải trí đa dạng với nhiều tính năng hữu ích, đáp ứng nhu cầu của người dùng.
Онлайн-журнал о строительстве https://zip.org.ua практичные советы, современные технологии, тренды дизайна и архитектуры. Всё о строительных материалах, ремонте, благоустройстве и инновациях в одной удобной платформе.
топ онлайн казино https://lastdepcasino.ru
An outstanding share! I have just forwarded this onto a friend who was conducting a little research on this. And he actually ordered me breakfast because I stumbled upon it for him… lol. So allow me to reword this…. Thanks for the meal!! But yeah, thanks for spending time to talk about this matter here on your blog.
казино онлайн топ на деньги самые лучшие казино
https://789club.deals
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Everyone loves what you guys are usually up too. This kind of clever work and coverage!
Keep up the fantastic works guys I’ve incorporated you guys to my own blogroll.
i9bet
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your
point. You obviously know what youre talking about, why throw away
your intelligence on just posting videos to your site when you could be giving us something informative to read?
https://i9bet.tips
Mandel, Leo (17 November 2008).
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
казино онлайн 2024 топ в россии казино на деньги хорошее
vin88
wonderful points altogether, you just won a
emblem new reader. What could you recommend about your post that you made a few days
in the past? Any sure?
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Excellent, what a web site it is! This web site
provides useful data to us, keep it up.
This information is worth everyone’s attention. Where can I
find out more?
Hey would you mind stating which blog platform you’re using? I’m looking to start my own blog soon but I’m having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your layout seems different then most blogs and I’m looking for something completely unique. P.S Sorry for getting off-topic but I had to ask!
xoso66
It?¦s really a nice and helpful piece of info. I am glad that you simply shared this helpful info with us. Please stay us up to date like this. Thanks for sharing.
Loto188
12BET
ok88 bet
This excellent website definitely has all the information I wanted about this subject and didn’t know who to ask.
ee88
kuwin không chỉ nổi tiếng với hàng trăm trò cá cược với phần thưởng cao mà chúng tôi còn mang đến cho người chơi rất nhiều khuyến mãi hấp dẫn.
alo789 nhà điều hành trang web sòng bạc trực tuyến, Với Chính sách cờ bạc có trách nhiệm hiện tại, không chỉ thể hiện được các cam kết của Công ty mà còn có cả trách nhiệm từ phía người chơi trong việc thúc đẩy các hoạt động cờ bạc có trách nhiệm và giảm thiểu ảnh hưởng tiêu cực của việc chơi bạc quá mức.
888b
Hi, i read your blog from time to time and i
own a similar one and i was just curious if you get a lot of spam responses?
If so how do you reduce it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any help is very much
appreciated.
xổ sốlà nhà cái uy tín với đa dạng trò chơi cá cược, từ thể thao, casino đến slot game,.. với giao diện hiện đại và dịch vụ chăm sóc khách hàng chuyên nghiệp 24/7.
Hey very interesting blog!
My spouse and I stumbled over here different web page and thought I might check
things out. I like what I see so i am just following you. Look forward to looking
over your web page again.
секс шоп каталог https://sex-shop-dp.top
секс шоп https://sex-shop-kh.top
j88Nền tảng cá cược hàng đầu với thể thao, casino, bắn cá. Giao diện hiện đại, bảo mật cao, ưu đãi khủng, hỗ trợ 24/7. Thắng lớn mỗi ngày tại J88!
To study more about Asian-impressed bathroom design, see the subsequent part.
This design is wicked! You most certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Excellent job. I really enjoyed what you had
to say, and more than that, how you presented it. Too
cool!
The ranking of the next desk is based on the realm (or square mileage) of every group within Larger Pittston.
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on various websites for about a year and am concerned about switching to another platform.
I have heard excellent things about blogengine.net. Is there a way I can import all my wordpress content into it?
Any help would be greatly appreciated!
Wow, that’s what I was looking for, what a information! existing here at
this weblog, thanks admin of this web site.
Having read this I thought it was rather enlightening. I appreciate you finding the time and effort to put this short article together. I once again find myself personally spending way too much time both reading and leaving comments. But so what, it was still worthwhile!
Hello Dear, are you truly visiting this web page regularly, if so after that you will definitely get pleasant know-how.
https://ww.ok365.org/
nhà cái hubet
Los Angeles Assessment of Books.
Saved as a favorite, I like your site.
8kbet
Hi there! This is my 1st comment here so I just wanted to give a quick shout out and tell
you I really enjoy reading through your posts. Can you recommend any other blogs/websites/forums that deal
with the same subjects? Thank you!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Рейтинг лучших онлайн-казино https://lastdepcasino.ru с быстрыми выплатами и честной игрой. Подробные обзоры, бонусы для новых игроков и актуальные акции.
2005 and contains a complete of 700,000 US gallons (2,600,000 L).
Рейтинг лучших онлайн-казино https://lastdepcasino.ru с быстрыми выплатами и честной игрой. Подробные обзоры, бонусы для новых игроков и актуальные акции.
Howdy very nice website!! Man .. Excellent ..
Superb .. I’ll bookmark your blog and take the feeds additionally?
I am glad to search out numerous helpful info right here in the submit, we want work out extra strategies in this regard, thanks for sharing.
. . . . .
Fb88 hoạt động trực tuyến trên nền tảng website.Tham gia vào website để tích luỹ nhiều kiến thức cá cược bổ ích, đặt cược nhanh chóng, dễ dàng. Fb88 mang đến cho hội viên cơ hội kiếm thưởng siêu hấp dẫn. Tham gia ngay!
We absolutely love your blog and find a lot of your post’s to be precisely
what I’m looking for. Would you offer guest writers to write content to suit your needs?
I wouldn’t mind creating a post or elaborating on a number of the subjects
you write regarding here. Again, awesome site!
Cat Products Cat Clothing
Pet Fashion and Accessories Pet Products
I blog quite often and I really appreciate your content.
The article has truly peaked my interest. I’m going to take a note of your blog and keep checking for new details about once a week.
I opted in for your RSS feed too.
you are really a excellent webmaster. The site loading speed is incredible.
It kind of feels that you are doing any unique trick.
Moreover, The contents are masterwork. you have done a excellent task on this
topic!
This site was… how do I say it? Relevant!! Finally I’ve found something that helped me. Many thanks.
Hello there I am so thrilled I found your web site, I really found you by error, while I
was looking on Askjeeve for something else, Anyhow I am here now and would just like to say thank you for a remarkable post and a all round thrilling blog (I
also love the theme/design), I don’t have time to read through it all at the
moment but I have book-marked it and also included your
RSS feeds, so when I have time I will be back to read much more, Please do keep up
the superb work.
Ваш гид в мире автомобилей https://clothes-outletstore.com тест-драйвы, советы по ремонту и последние тенденции индустрии.
Автомобильный журнал https://automobile.kyiv.ua с фокусом на практичность. Ремонт, уход за авто, обзор технологий и советы по эксплуатации.
“xoso66 Tham gia để khám phá những cơ hội trúng lớn trong thế giới xổ số online ngay hôm nay. Nơi con số là người bạn đồng hành dài lâu.
“
Ваш гид в мире автомобилей https://clothes-outletstore.com тест-драйвы, советы по ремонту и последние тенденции индустрии.
12 bet
Автомобильный журнал https://automobile.kyiv.ua с фокусом на практичность. Ремонт, уход за авто, обзор технологий и советы по эксплуатации.
nhà cái bk8
nổ hũ Tham gia để khám phá những cơ hội trúng lớn trong thế giới xổ số online ngay hôm nay. Nơi con số là người bạn đồng hành dài lâu.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
s666
hello 88
betvisa
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
8xbet
33win
https://yo88club.app
daga88 Thể thao, casino, nổ hũ, đá gà trực tuyến. Đăng ký tài khoản Hi88 ngay hôm nay để nhận ưu đãi 999k. Link chính thức daga88 tại Việt Nam.
I needed to thank you for this very good read!! I certainly loved every bit of it. I’ve got you book marked to look at new things you post…
Всё о машинах https://avtomobilist.kyiv.ua тест-драйвы, сравнения моделей, авто новости, советы по ремонту и уходу.
Авто журнал https://avtonews.kyiv.ua новости автопрома, сравнения моделей, тест-драйвы, советы по ремонту и уходу.
Авто портал https://autonovosti.kyiv.ua актуальные новости, обзоры авто, тест-драйвы, инструкции по ремонту и тюнингу. Минимум текста, максимум полезной информации.
Всё о машинах https://black-star.com.ua авто новости, тест-драйвы, обзоры моделей, рейтинги, инструкции по обслуживанию и ремонту.
Howdy! I could have sworn I’ve been to this blog before but after reading through some of the post I
realized it’s new to me. Anyhow, I’m definitely happy I found it and I’ll be bookmarking and checking back frequently!
Nhà cái uy tínlà chuyên trang review top nhà cái cá cược trực tuyến an toàn, uy tín tại Việt Nam trong nhiều năm.
Chúng tôi mang đến những review nhà cái chất lượng và là lựa chọn hàng đầu để tham khảo.
Всё о машинах https://avtomobilist.kyiv.ua тест-драйвы, сравнения моделей, авто новости, советы по ремонту и уходу.
Авто журнал https://avtonews.kyiv.ua новости автопрома, сравнения моделей, тест-драйвы, советы по ремонту и уходу.
Авто портал https://autonovosti.kyiv.ua актуальные новости, обзоры авто, тест-драйвы, инструкции по ремонту и тюнингу. Минимум текста, максимум полезной информации.
Всё о машинах https://black-star.com.ua авто новости, тест-драйвы, обзоры моделей, рейтинги, инструкции по обслуживанию и ремонту.
http://inhacaiuytin.com.mx/ Nhà cái uy tín là chuyên trang review top nhà cái cá cược trực tuyến an toàn, uy tín tại Việt Nam trong nhiều năm.
Chúng tôi mang đến những review nhà cái chất lượng và là lựa chọn hàng đầu để tham khảo.
The Aesthetic artists had been primarily involved with the creation of that which was beautiful.
Your posts are so beautifully written and always leave me feeling inspired and empowered Thank you for using your talents to make a positive impact
i9 bet
Авто журнал https://avtonews.kyiv.ua новости автопрома, сравнения моделей, тест-драйвы, советы по ремонту и уходу.
Всё о машинах https://avtomobilist.kyiv.ua тест-драйвы, сравнения моделей, авто новости, советы по ремонту и уходу.
Всё о машинах https://black-star.com.ua авто новости, тест-драйвы, обзоры моделей, рейтинги, инструкции по обслуживанию и ремонту.
Авто портал https://autonovosti.kyiv.ua актуальные новости, обзоры авто, тест-драйвы, инструкции по ремонту и тюнингу. Минимум текста, максимум полезной информации.
789 club
Aw, this was an incredibly nice post. Taking a few minutes and actual effort to generate a really good article… but what can I say…
I procrastinate a lot and never manage to get nearly anything done.
Hi88 mang đến trải nghiệm cá cược trực tuyến hoàn toàn khác biệt với sự kết hợp độc quyền giữa công nghệ tiên tiến và giao diện dễ sử dụng. Được thiết kế để cung cấp tỷ lệ cược hấp dẫn và dịch vụ khách hàng xuất sắc, Hi88 cam kết mang lại trải nghiệm 100% độc đáo cho người dùng
nổ hũxem tại daga88 Thể thao, casino, nổ hũ, đá gà trực tuyến. Đăng ký tài khoản Hi88 ngay hôm nay để nhận ưu đãi 999k. Link chính thức daga88 tại Việt Nam.
nohu90Trải Nghiệm Game Slot Đỉnh Cao! Tham gia ngay để nhận những phần thưởng hấp dẫn và khám phá những bí mật chờ bạn chinh phục!
game casinoTrải Nghiệm Game Slot Đỉnh Cao! Tham gia ngay để nhận những phần thưởng hấp dẫn và khám phá những bí mật chờ bạn chinh phục!
banca30KHÔNG CHỈ LÀ BẮN CÁ! Khám phá THẾ GIỚI GAME ĐỒ SỘ với đa dạng thể loại GIẢI TRÍ HẤP DẪN. Từ những tựa game bắn cá KINH ĐIỂN đến các trò chơi MỚI LẠ và HIỆN ĐẠI, chúng tôi luôn cập nhật để mang đến trải nghiệm ĐỈNH CAO cho người chơi. THAM GIA NGAY và THỎA SỨC KHÁM PHÁ!
Hi88vip mobi là một trong những thương hiệu hàng đầa của người chơi cờ bạc ở Đông Nam Á, đặc biệt là ở Việt Nam, Thái Lan và Indonesia. Cá cược trực tuyến với sứ mệnh mang đến cho hội viên những trải nghiệm đặc sắc nhất
nổ hũKHÔNG CHỈ LÀ BẮN CÁ! Khám phá THẾ GIỚI GAME ĐỒ SỘ với đa dạng thể loại GIẢI TRÍ HẤP DẪN. Từ những tựa game bắn cá KINH ĐIỂN đến các trò chơi MỚI LẠ và HIỆN ĐẠI, chúng tôi luôn cập nhật để mang đến trải nghiệm ĐỈNH CAO cho người chơi. THAM GIA NGAY và THỎA SỨC KHÁM PHÁ!
Всё о самогоноварении https://brewsugar.ru на одном сайте: от истории напитка до современных технологий перегонки.
Всё об авто https://road.kyiv.ua в одном месте: новости, тест-драйвы, сравнения, характеристики, ремонт и уход. Автомобильный онлайн-журнал — ваш эксперт в мире машин.
xoso66Nền tảng lý tưởng cho những tín đồ cá cược trực tuyến, mang đến trải nghiệm giải trí đỉnh cao với bộ sưu tập trò chơi phong phú như xổ số, casino trực tuyến, bắn cá, thể thao, đá gà, nổ hũ và nhiều trò chơi sòng bạc hấp dẫn khác.
Место для общения на любые темы https://xn--9i1b12ab68a.com/ актуальные вопросы, обмен опытом, интересные дискуссии. Здесь найдётся тема для каждого.
Перевозка товаров из Китая https://chinaex.ru в Россию под ключ: авиа, море, автотранспорт. Гарантия сроков и сохранности груза.
Всё о самогоноварении https://brewsugar.ru на одном сайте: от истории напитка до современных технологий перегонки.
Всё об авто https://road.kyiv.ua в одном месте: новости, тест-драйвы, сравнения, характеристики, ремонт и уход. Автомобильный онлайн-журнал — ваш эксперт в мире машин.
Место для общения на любые темы https://xn--9i1b12ab68a.com/ актуальные вопросы, обмен опытом, интересные дискуссии. Здесь найдётся тема для каждого.
Перевозка товаров из Китая https://chinaex.ru в Россию под ключ: авиа, море, автотранспорт. Гарантия сроков и сохранности груза.
You are so interesting! I do not suppose I’ve truly read through a single thing like that before. So great to find another person with unique thoughts on this issue. Really.. thanks for starting this up. This web site is one thing that’s needed on the internet, someone with a little originality.
Can I simply say what a relief to uncover one who in fact knows what theyre discussing on the net. You actually know how to bring a difficulty to light making it important. More and more people must check out this and can see this side of the story. I cant believe youre less well-liked as you undoubtedly develop the gift.
Женский портал https://abuki.info мода, красота, здоровье, семья, карьера. Советы, тренды, лайфхаки, рецепты и всё, что важно для современных женщин.
Автомобильный онлайн-журнал https://simpsonsua.com.ua предлагает свежие новости, обзоры авто, тест-драйвы, рейтинги и полезные советы для водителей.
Мода, здоровье, красота https://gratransymas.com семья, кулинария, карьера. Женский портал — полезные советы и свежие идеи для каждой.
Познавательный портал для детей https://detiwki.com.ua обучающие материалы, интересные факты, научные эксперименты, игры и задания для развития кругозора.
Hello there! This blog post couldn’t be written much better! Going through this post reminds me of my previous roommate! He constantly kept preaching about this. I will send this information to him. Fairly certain he will have a very good read. Thank you for sharing!
Женский портал https://abuki.info мода, красота, здоровье, семья, карьера. Советы, тренды, лайфхаки, рецепты и всё, что важно для современных женщин.
Автомобильный онлайн-журнал https://simpsonsua.com.ua предлагает свежие новости, обзоры авто, тест-драйвы, рейтинги и полезные советы для водителей.
Мода, здоровье, красота https://gratransymas.com семья, кулинария, карьера. Женский портал — полезные советы и свежие идеи для каждой.
Познавательный портал для детей https://detiwki.com.ua обучающие материалы, интересные факты, научные эксперименты, игры и задания для развития кругозора.
thanks good jobs
Magnificent website. Lots of useful info here. I am sending it to a few pals ans additionally sharing
in delicious. And naturally, thank you in your effort!
Your blog has become my go-to source for inspiration and motivation Thank you for consistently delivering high-quality content
Женский онлайн-журнал https://womanfashion.com.ua секреты красоты, модные тренды, здоровье, отношения, семья, кулинария и карьера. Всё, что важно и интересно.
Find the latest Roblox codes https://pocket-codes.com/roblox-codes to unlock exclusive rewards, boosts, and items in your favorite games. Stay updated with new codes and level up your adventures on the Roblox platform today!
офисная мебель металлический каркас магазин офисной мебели петербург
Женский онлайн-журнал https://stylewoman.kyiv.ua стиль, уход, здоровье, отношения, семья, кулинарные рецепты, психология и карьера.
Женский онлайн-журнал https://womanfashion.com.ua секреты красоты, модные тренды, здоровье, отношения, семья, кулинария и карьера. Всё, что важно и интересно.
Find the latest Roblox codes https://pocket-codes.com/roblox-codes to unlock exclusive rewards, boosts, and items in your favorite games. Stay updated with new codes and level up your adventures on the Roblox platform today!
магазины продажи офисной мебели https://ковка116.рф
Женский онлайн-журнал https://stylewoman.kyiv.ua стиль, уход, здоровье, отношения, семья, кулинарные рецепты, психология и карьера.
iwin
rikvip
https://ee88.love
Туристический портал https://aliana.com.ua лучшие маршруты, путеводители, советы путешественникам, обзоры отелей.
Всё о туризме https://atrium.if.ua маршруты, путеводители, советы по отдыху, обзор отелей и лайфхаки. Туристический портал — ваш помощник в путешествиях.
мягкая мебель в кабинет https://ковка116.рф
Всё для путешествий https://cmc.com.ua уникальные маршруты, гиды по городам, актуальные акции на туры и полезные статьи для туристов.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Туристический портал https://aliana.com.ua лучшие маршруты, путеводители, советы путешественникам, обзоры отелей.
офисная мебель магазин склад дорогая офисная мебель
Всё о туризме https://atrium.if.ua маршруты, путеводители, советы по отдыху, обзор отелей и лайфхаки. Туристический портал — ваш помощник в путешествиях.
Всё для путешествий https://cmc.com.ua уникальные маршруты, гиды по городам, актуальные акции на туры и полезные статьи для туристов.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Next time I read a blog, I hope that it does not disappoint me just as much as this particular one. I mean, Yes, it was my choice to read, nonetheless I really thought you would probably have something useful to say. All I hear is a bunch of complaining about something you could fix if you were not too busy searching for attention.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
You are so cool man, the post on your blogs are super great.*;:;”
nohu90là một nhà cái cá cược đáng tin cậy, được công nhận bởi Hiệp hội Cá cược Quốc tế. Hãy đảm bảo bạn đã đủ 18 tuổi trước khi tham gia đăng ký.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
nổ hũlà một nhà cái cá cược đáng tin cậy, được công nhận bởi Hiệp hội Cá cược Quốc tế. Hãy đảm bảo bạn đã đủ 18 tuổi trước khi tham gia đăng ký.
Introducing to you the most prestigious online entertainment address today. Visit now to experience now!
Yeu88
Статьи о путешествиях https://deluxtour.com.ua гиды по направлениям, лайфхаки для отдыха, советы по сбору багажа и туристические обзоры.
Путешествия по Греции https://cpcfpu.org.ua лучшие курорты, гиды по островам, экскурсии, пляжи и советы по планированию отпуска.
Туристический журнал https://elnik.kiev.ua свежие идеи для путешествий, обзоры курортов, гиды по городам, советы для самостоятельных поездок и туристические новости.
https://b52.tube
Very rapidly this web page will be famous amid all blog viewers, due to it’s fastidious content
Hello there! I simply would like to offer you a big thumbs
up for the excellent info you have got right here on this post.
I am coming back to your website for more soon.
Статьи о путешествиях https://deluxtour.com.ua гиды по направлениям, лайфхаки для отдыха, советы по сбору багажа и туристические обзоры.
Путешествия по Греции https://cpcfpu.org.ua лучшие курорты, гиды по островам, экскурсии, пляжи и советы по планированию отпуска.
You have chosen an impossible idea and made it possible for the common person to see and believe. Keep up the good work, and I look forward to much more from your mind and hand.
Туристический журнал https://elnik.kiev.ua свежие идеи для путешествий, обзоры курортов, гиды по городам, советы для самостоятельных поездок и туристические новости.
I was very happy to uncover this website. I need to to thank you for your time for this fantastic read!! I definitely appreciated every little bit of it and I have you saved to fav to see new information in your site.
Туристический портал https://feokurort.com.ua необычные маршруты, вдохновляющие истории, секреты бюджетных путешествий, советы по визам и топовые направления для отдыха.
Туристический портал https://feokurort.com.ua необычные маршруты, вдохновляющие истории, секреты бюджетных путешествий, советы по визам и топовые направления для отдыха.
Hi, just wanted to mention, I loved this blog post. It was practical.
Keep on posting!
Статьи о туризме и путешествиях https://inhotel.com.ua маршруты, гиды по достопримечательностям, советы по планированию поездок, рекомендации по отелям и лайфхаки для туристов.
Гиды по странам https://hotel-atlantika.com.ua экскурсии по городам, советы по выбору жилья и маршрутов. Туристический журнал — всё для комфортного и яркого путешествия.
Комплексный ремонт квартир https://anti-orange.com.ua и домов от Студии ремонта. Полный цикл работ: от дизайна до финишной отделки.
It’s hard to find experienced people on this subject, but you sound like you know what you’re talking about! Thanks
daga88 trải nghiệm cảm giác đá gà trực tiếp cùng chiến kê ngay tại nhà. Tham gia ngay!
vnlotolà một trong những nhà cái uy tín và phát triển nhanh tại thị trường Việt Nam, chuyên cung cấp dịch vụ cá cược và xổ số trực tuyến.
Статьи о туризме и путешествиях https://inhotel.com.ua маршруты, гиды по достопримечательностям, советы по планированию поездок, рекомендации по отелям и лайфхаки для туристов.
Гиды по странам https://hotel-atlantika.com.ua экскурсии по городам, советы по выбору жилья и маршрутов. Туристический журнал — всё для комфортного и яркого путешествия.
Комплексный ремонт квартир https://anti-orange.com.ua и домов от Студии ремонта. Полный цикл работ: от дизайна до финишной отделки.
Hi” your blog is full of comments and it is very active”
Thể Thao Vnlotolà một trong những nhà cái uy tín và phát triển nhanh tại thị trường Việt Nam, chuyên cung cấp dịch vụ cá cược và xổ số trực tuyến.
Right here is the right blog for everyone who wishes to
find out about this topic. You know a whole lot its almost tough to argue with you (not
that I actually would want to…HaHa). You definitely put a brand new spin on a subject that’s been discussed for a long time.
Wonderful stuff, just excellent!
Cheers. I enjoy it!
OK9 là chuyên trang tin tức thể thao hàng đầu, nơi cập nhật nhanh chóng và chính xác các diễn biến mới nhất của làng thể thao trong nước và quốc tế. Đặc biệt, bóng đá luôn là tâm điểm với những tin tức nóng hổi từ các giải đấu lớn như Ngoại Hạng Anh, La Liga, Champions League cho đến các trận cầu đỉnh cao trong nước.
Строительная компания https://as-el.com.ua выполняем строительство жилых и коммерческих объектов под ключ. Полный цикл: проектирование, согласование, строительство и отделка.
На строительном портале https://avian.org.ua вы найдете всё: от пошаговых инструкций до списка лучших подрядчиков. Помогаем реализовать проекты любой сложности быстро и удобно.
Строительный портал https://ateku.org.ua ваш гид в мире строительства и ремонта. Полезные статьи, обзоры материалов, советы по выбору подрядчиков и идеи дизайна.
Портал по ремонту https://azst.com.ua всё для вашего ремонта: подбор подрядчиков, советы по выбору материалов, готовые решения для интерьера и проверенные рекомендации.
Строительная компания https://as-el.com.ua выполняем строительство жилых и коммерческих объектов под ключ. Полный цикл: проектирование, согласование, строительство и отделка.
Đã thử rất nhiều nền tảng, nhưng phải nói 123win thật sự nổi bật với giao diện mượt mà, tỷ lệ cược hấp dẫn và hỗ trợ khách hàng siêu nhanh! Nếu bạn chưa trải nghiệm, thì thật sự đang bỏ lỡ một sân chơi đẳng cấp!
На строительном портале https://avian.org.ua вы найдете всё: от пошаговых инструкций до списка лучших подрядчиков. Помогаем реализовать проекты любой сложности быстро и удобно.
Строительный портал https://ateku.org.ua ваш гид в мире строительства и ремонта. Полезные статьи, обзоры материалов, советы по выбору подрядчиков и идеи дизайна.
Портал по ремонту https://azst.com.ua всё для вашего ремонта: подбор подрядчиков, советы по выбору материалов, готовые решения для интерьера и проверенные рекомендации.
Расслабьтесь с велас ароматическими свечами, куда поставить свечи?, Подарите себе моменты релаксации с велас ароматическими свечами
difusor aroma [url=https://scentalle.com/]https://scentalle.com/[/url] .
Расслабьтесь с велас ароматическими свечами, Погрузитесь в мир ароматов с велас, Секрет создания домашнего уюта: велас ароматические свечи
aceites para velas [url=https://scentalle.com/]https://scentalle.com/[/url] .
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now
each time a comment is added I get four e-mails with
the same comment. Is there any way you can remove people from that service?
Cheers!
It’s a shame you don’t have a donate button! I’d most certainly donate to this
outstanding blog! I guess for now i’ll settle for book-marking and adding
your RSS feed to my Google account. I look forward to fresh
updates and will share this website with my Facebook group.
Chat soon!
Всё о ремонте на одном сайте https://comart.com.ua Портал по ремонту предлагает обзоры материалов, рейтинги специалистов, советы экспертов и примеры готовых проектов для вдохновения.
Всё о ремонте на одном сайте https://comart.com.ua Портал по ремонту предлагает обзоры материалов, рейтинги специалистов, советы экспертов и примеры готовых проектов для вдохновения.
Журнал по ремонту https://domtut.com.ua и строительству – советы, идеи и обзоры. Узнайте о трендах, изучите технологии и воплотите свои строительные или дизайнерские задумки легко и эффективно.
Портал о ремонте https://eeu-a.kiev.ua всё для тех, кто ремонтирует: пошаговые инструкции, идеи дизайна, обзор материалов и подбор подрядчиков.
Журнал по ремонту и строительству https://diasoft.kiev.ua гид по современным тенденциям. Полезные статьи, лайфхаки, инструкции и обзор решений для дома и офиса.
Журнал по ремонту https://domtut.com.ua и строительству – советы, идеи и обзоры. Узнайте о трендах, изучите технологии и воплотите свои строительные или дизайнерские задумки легко и эффективно.
Портал о ремонте https://eeu-a.kiev.ua всё для тех, кто ремонтирует: пошаговые инструкции, идеи дизайна, обзор материалов и подбор подрядчиков.
Журнал по ремонту и строительству https://diasoft.kiev.ua гид по современным тенденциям. Полезные статьи, лайфхаки, инструкции и обзор решений для дома и офиса.
When I originally commented I seem to have clicked on the -Notify me when new comments are added- checkbox and now each time a comment is added I recieve four emails with the same comment. There has to be a way you are able to remove me from that service? Cheers.
Новости технологий https://helikon.com.ua все о последних IT-разработках, гаджетах и научных открытиях. Свежие обзоры, аналитика и тренды высоких технологий.
Новости технологий https://helikon.com.ua все о последних IT-разработках, гаджетах и научных открытиях. Свежие обзоры, аналитика и тренды высоких технологий.
This information is invaluable. How can I find out more?
оценка профессиональных рисков в строительстве оценка профессиональных рисков стоимость услуг Москва
проведение оценки профессиональных рисков на рабочих местах в Москве оценка профессиональных рисков заказать Москва
79king
https://b52club.select
Link vào 8live
Строительный онлайн журнал https://inter-biz.com.ua руководства по проектам любой сложности. Советы экспертов, подбор материалов, идеи дизайна и новинки рынка.
Сайт о строительстве и ремонте https://hydromech.kiev.ua полезные советы, инструкции, обзоры материалов и технологий. Все этапы: от фундамента до отделки.
Строительные технологии https://ibss.org.ua новейшие разработки и решения в строительной сфере. Материалы, оборудование, инновации и тренды для профессионалов и застройщиков.
Строительный онлайн журнал https://inter-biz.com.ua руководства по проектам любой сложности. Советы экспертов, подбор материалов, идеи дизайна и новинки рынка.
Строительные технологии https://ibss.org.ua новейшие разработки и решения в строительной сфере. Материалы, оборудование, инновации и тренды для профессионалов и застройщиков.
Сайт о строительстве и ремонте https://hydromech.kiev.ua полезные советы, инструкции, обзоры материалов и технологий. Все этапы: от фундамента до отделки.
8live
https://zbet100.net/
Все о строительстве и ремонте https://kennan.kiev.ua практичные рекомендации, идеи интерьеров, новинки рынка и советы профессионалов.
https://zbet.london